КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Виды ошибок
|
|
|
|
Статистическая гипотеза.
Статистическая гипотеза
Статистическая гипотеза, предположительное суждение о вероятностных закономерностях, которым подчиняется изучаемое явление. Как правило, С. г. определяет значения параметров закона распределения вероятностей или его вид. С. г. называется простой, если она определяет единственный закон распределения; в ином случае С. г. называется сложной и может быть представлена как некоторый класс простых С. г. Например, гипотеза о том, что распределение вероятностей является нормальным распределением с математическим ожиданием а = а0 и некоторой (неизвестной) дисперсией s2 будет сложной, составленной из простых гипотез а = а0, 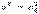 (а0 и
(а0 и 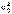 — заданные числа).
— заданные числа).
Ошибки первого рода (англ. type I errors, α errors, false positives) и ошибки второго рода (англ. type II errors, β errors, false negatives) в математической статистике — это ключевые понятия задач проверки статистических гипотез. Тем не менее, данные понятия часто используются и в других областях, когда речь идёт о принятии «бинарного» решения (да/нет) на основе некоего критерия (теста, проверки, измерения), который с некоторой вероятностью может давать ложный результат.
Определения
Пусть дана выборка 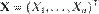 из неизвестного совместного распределения PX, и поставлена бинарная задача проверки статистических гипотез:
из неизвестного совместного распределения PX, и поставлена бинарная задача проверки статистических гипотез:
H0, H1 где H0 — нулевая гипотеза, а H1 — альтернативная гипотеза. Предположим, что задан статистический критерий
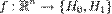 ,
,
сопоставляющий каждой реализации выборки X=xодну из имеющихся гипотез. Тогда возможны следующие четыре ситуации:
Распределение PX выборки X соответствует гипотезе H0, и она точно определена статистическим критерием, то есть f(x)=Ho.
Распределение PXвыборки соответствует гипотезе H0, но она неверно отвергнута статистическим критерием, то есть f(x)=H1.
Распределение PXвыборки Xсоответствует гипотезе H1, и она точно определена статистическим критерием, то есть f(x)=H1.
Распределение Pxвыборки Xсоответствует гипотезе H1, но она неверно отвергнута статистическим критерием, то есть f(x)=H0.
Во втором и четвертом случае говорят, что произошла статистическая ошибка, и её называют ошибкой первого и второго рода соответственно.
Вероятности ошибок (уровень значимости и мощность)
Вероятность ошибки первого рода при проверке статистических гипотез называют уровнем значимости и обычно обозначают греческой буквой α (отсюда название α-errors).
Вероятность ошибки второго рода не имеет какого-то особого общепринятого названия, на письме обозначается греческой буквой β (отсюда β-errors). Однако с этой величиной тесно связана другая, имеющая большое статистическое значение — мощность критерия. Она вычисляется по формуле (1 − β). Таким образом, чем выше мощность, тем меньше вероятность совершить ошибку второго рода.
Обе эти характеристики обычно вычисляются с помощью так называемой функции мощности критерия. В частности, вероятность ошибки первого рода есть функция мощности, вычисленная при нулевой гипотезе. Для критериев, основанных на выборке фиксированного объема, вероятность ошибки второго рода есть единица минус функция мощности, вычисленная в предположении, что распределение наблюдений соответствует альтернативной гипотезе. Для последовательных критериев это также верно, если критерий останавливается с вероятностью единица (при данном распределении из альтернативы).
В статистических тестах обычно приходится идти на компромисс между приемлемым уровнем ошибок первого и второго рода. Зачастую для принятия решения используется пороговое значение, которое может варьироваться с целью сделать тест более строгим или, наоборот, более мягким. Этим пороговым значением является уровень значимости, которым задаются при проверке статистических гипотез. Например, в случае металлодетектора повышение чувствительности прибора приведёт к увеличению риска ошибки первого рода (ложная тревога), а понижение чувствительности — к увеличению риска ошибки второго рода (пропуск запрещённого предмета).
|
|
|
|
|
Дата добавления: 2014-12-24; Просмотров: 510; Нарушение авторских прав?; Мы поможем в написании вашей работы!