КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Використання індексу для операцій над файлом з довільним доступом
|
|
|
|
Вправи
Питання для роздумів
- Як Ви думаєте, більше чи менше місця в пам'яті будуть займати відомості про студентів із прикладу 4.6, якщо їх помістити у файл не довільного, а послідовного доступу? Від чого буде залежати обсяг пам'яті, що займається цими зведеннями? (Відповідь: У текстовому файлі пам'ять буде залежати від сумарної кількості символів у значень типу String, довжина яких буде нефіксована. Наприклад, кількість символів у чотирьох прізвищ прикладу 4.2 дорівнює 26, а у файлі довільного доступу їм надається пам'ять обсягом 20*6 = 120 символів!)
- Як, використовуючи функції Len і LOF, можна знайти число записів у файлі довільного доступу? (Підказка: Див. коди 4.6 і 4.8.)
- Як Ви знаєте, викладачі ведуть журнал. У цьому журналі, по-перше, записуються теми занять з кожного предмету, а по-друге: виставляються оцінки, отримані студентами на заняттях. Придумайте дві таблиці бази даних, у яких містилися б відомості з такого журналу.
- Допустимо, що в поточному навчальному році Ви вивчаєте 10 предметів, у навчальному році 36 тижнів, а на кожного студента припадає 1180 годин. Встановіть розміри полів для таблиць з попередньої вправи й оцініть довжину файлів для їхнього збереження.
Поступове заповнення таблиць бази даних (у вигляді файлів з довільним доступом) найчастіше робиться стихійно, безсистемно. На факультет переводиться новий студент і дані про нього просто дописуються у файл як останній запис. Списки на мал. 4.5 демонструють дані, отримані з таких безладно складених файлів.
Використання стихійно побудованих файлів, коли вони стають досить великими, перетворюється в дуже клопітку справу. Очевидно, що для зручності роботи з файлами їх потрібно якось впорядкувати.
Найпоширеніший спосіб — переставити записи файлу так, щоб значення якого-небудь поля були розташовані в алфавітному (лексикографічному) порядку, а якщо значення поля числове — у порядку його зростання чи спадання. Такий спосіб впорядкування називається сортуванням файлу (Поняття сортування масиву було розглянуто в розд. 3.3. Ідеї сортування файлу аналогічні ідеям сортування одномірного масиву.). А обране для цієї мети поле називають ключем сортування.
Яке поле варто вибрати як ключ? У розглянутому прикладі 4.6 бази даних зі зведеннями про студентів на роль такого поля напрошується Прізвище. Однак, Ви знаєте, що у великих колективах, таких, як інститут, завжди знайдуться люди з однаковими прізвищами, тому для сортування файлу як ключ краще взяти не одне поле Прізвище, а об'єднання полів: Прізвище та Ім'я, чи ще краще — Група, Прізвище та Ім'я (Малоймовірно, що в одній групі знайдуться студенти з одним і тим же прізвищем і тим самим ім'ям.).
Але кращим рішенням проблеми є введення ще одного спеціального поля, що називають Ідентифікаційним номером (IdNumber) чи просто ідентифікатором запису. Звичайно ідентифікатором буває число, що однозначно визначає запис. (Іншими словами, не повинно бути двох записів з однаковими ідентифікаторами.)
У нашому випадку (приклад 4.6) кожен запис відноситься до визначеного студента й ідентифікатором міг би бути, наприклад, номер його студентського квитка.
Ми ще повернемося до цього питання у наступній главі, а в нашому випадку для простоти будемо вважати ключем сортування об'єднання двох полів — Прізвища та Імені.
Для того щоб представити записи файлу в упорядкованому вигляді, замість сортування усього файлу зручніше зробити таким чином:
- створити так званий індекс — множину коротких записів. Кожен короткий запис складається тільки з двох полів — Ключа і НомераЗапису. НомеромЗаnucу служить номер довгого запису (Довгим ми назвали повний запис файлу, для якого створюється індекс. У прикладі 4.7 такий запис містить 6 полів і складається з 94 символів. А короткий запис індексу, якщо він буде містити тільки прізвище і номер запису, складатиметься всього з 22 символів (20 символів — прізвище і 2 символи — номер запису).) файлу;
- потім відсортувати цей індекс за зростанням (чи спаданням) Ключа;
- і, нарешті, видати довгі записи файлу в тому порядку, у якому будуть розміщені їхні короткі представники в індексі після сортування.
Приклад 4.9. Повернемося до програм прикладів 4.7 і 4.8. Доповнимо їх сортуванням масиву з довільним доступом Студенти.raf. З цією метою насамперед оголосимо індекс.
З'являється індекс так само, як і користувацький тип даних (див. код 4.7),у тому ж місці програми:
| Код 4.12 |

|
Після того як буде відкритий файл довільного доступу й у нього будуть записані всі довгі записи (код 4.10). Перед тим як вводити ці записи (код 4.11)необхідно заповнити індекс поки ще не відсортованими короткими записами. Для цього код 4.11 доповнити наступним фрагментом:
| Код 4.13 |

|
У даному випадку виділяються тільки два із шести полів довгого запису: Студент.Прізвище і Студент.Ім'я. До них застосовується функція Trim — вилучення зайвих пробілів, потім вони «склеюються» за допомогою операції конкатенації (+) і до рядка, що вийшов, застосовується операція UCase. Результат буде значенням ключа сортування — Іпdех(і).ПрізвищеІм’я. Другим компонентом індексу буде номер довгого запису у файлі — Index(i).HoмерЗапису.
Тепер ми можемо приступити безпосередньо до сортування індексу. Для цього скористаємося одним з методів сортування, описаних у гл. 3, наприклад, кульковим методом (Нагадаємо ідею кулькового методу. Спочатку ключ першого (i=l) елемента відсортованої множини 1пdех(1).ПрізвищеІм по черзі порівнюються з ключами інших елементів. Як тільки трапляється менший (за значенням ключа) елемент, порівнювані елементи Index(i) і Index(j) міняються місцями. У результаті «спливає кулька» — мінімальний за значенням ключа елемент множини на перше місце. Потім все це робиться і з іншими елементами. Обмін вмістом елементів Index(i) і Index(j) робиться за допомогою «запасного» елементу Index(0).).
| Код 4.14 |

|
У коді 4.11 варто зробити доповнення:
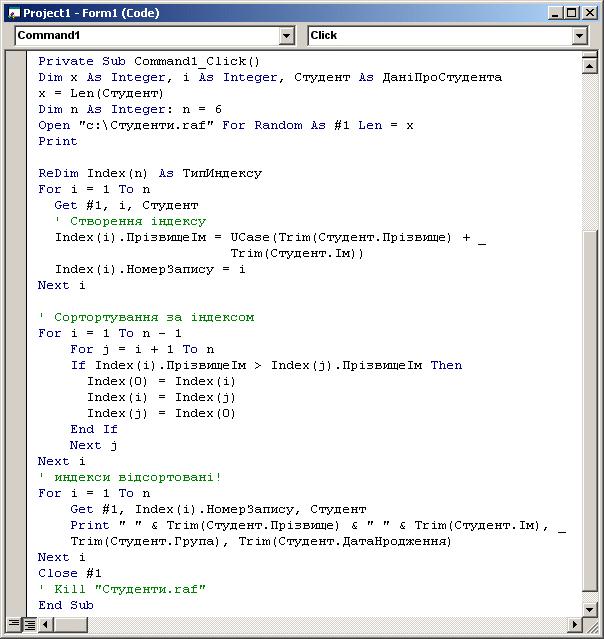
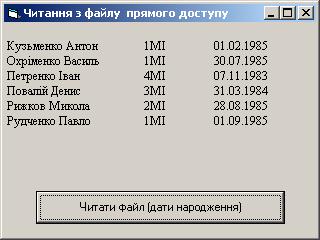
Get #1, Index(i).HoмepЗапису, Студент ми одержимо остаточний варіант коду 4.11 для виводу відсортованих записів (код. 4.11 а). Результат, роботи цього коду приведений на мал. 4.6:
| Код 4.11 а |
|
|
| Мал. 4.6. Результат сортування (у лексикографічному порядку) файлу довільного доступу з використанням індексу |
Ви бачите, що даний список відрізняється від того, котрий був отриманий раніше (мал. 4.5), — він відсортований. (Ключем сортування є конкатенація рядків Прізвище й Ім'я.)
При роботі з файлом довільного доступу індекс можна використовувати для багатьох цілей, наприклад для відновлення файлу.
Задача відновлення файлу полягає в наступному:
- частину зведень у якому-небудь наявному запису потрібно замінити новими даними (наприклад, у якого-небудь студента змінився телефон чи навіть адреса);
- потрібно внести у файл зовсім новий запис (з'явився новий студент);
- потрібно видалити який-небудь запис з файлу (студента відраховано).
В усіх цих випадках використання індексу дозволяє істотно полегшити перегляд і прискорити пошук потрібного Вам запису, якщо Ви знаєте значення ключа, а індекс цього ключа відсортовано.
У відсортованому індексі можна, наприклад, організувати так званий двійковий пошук. Ідея алгоритму такого пошуку полягає в наступному.
Береться номер посередині між максимальним і мінімальним номерами записів файлу. Значення ключа шуканого запису порівнюється зі значенням ключа індексу, що має даний номер. У залежності від результату цього порівняння рівно половина номерів відкидається, тому що шуканий запис свідомо не може мати номер з цієї половини. Потім береться номер посередині номерів, що залишилися, і все повторюється. Такий процес дуже швидко приводить до результату, навіть якщо довжина файлу дуже велика!
Зрозуміло, рішення перерахованих задач вимагає визначених зусиль по складанню часом не дуже простих програмних кодів. Програми, у яких реалізований двійковий пошук елемента у відсортованому масиві й у відсортованому файлі, приведені в останньому розділі даної глави.
Hові поняття:
|
|
|
|
|
Дата добавления: 2014-12-23; Просмотров: 407; Нарушение авторских прав?; Мы поможем в написании вашей работы!