КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Mpirun n0-6 –v hosts hello
|
|
|
|
Hello world from process 0 of 7
Hello world from process 3 of 7
Hello world from process 5 of 7
Hello world from process 4 of 7
Hello world from process 2 of 7
Hello world from process 6 of 7
Hello world from process 1 of 7
Программа будет запущена на 7 узлах (включая сервер), а адреса этих узлов находятся в файле hosts. Печать на экран осуществлялась процессами не по порядку их рангов. Это связано с тем, что запуск процессов не синхронизирован, однако в MPI существуют специальные функции для синхронизации процессов.
Простейшая программа не содержит функций передачи сообщений. В реальных же задачах процессам требуется взаимодействовать друг с другом. Естественно, на передачу сообщений тратится время, что снижает коэффициент распараллеливания задачи. Чем выше скорость интерфейса передачи сообщений (например Ethernet 10Mb/sec и Gigabit Ethernet), тем меньше будут затраты на передачу данных. Т.к. время обмена данными между процессами намного (на порядки) больше времени доступа к собственной памяти, распределение работы между процессами должно быть ‘крупнозернистым’, нужно избегать ненужных пересылок данных.
Среди задач численного анализа встречается немало задач, распараллеливание которых очевидно. Например, численное интегрирование сводится фактически к (многочисленному) вычислению подинтегральной функции (что естественно доверить отдельным процессам), при этом главный процесс управляет процессом вычислений (определяет стратегию распределения точек интегрирования по процессам и собирает частичные суммы). Подобным же распараллеливанием обладают задачи поиска и сортировки в линейном списке, численного нахождения корней функций, поиск экстремумов функции многих переменных, вычисление рядов и другие. В этой лабораторной работе мы рассмотрим два параллельных алгоритма вычисления числа π.
Вычисление числа π методом численного интегрирования
Известно, что 
Заменяя вычисление интеграла конечным суммированием, имеем 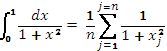 , где
, где 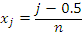 , n-число участков суммирования при численном интегрировании. Площадь каждого участка вычисляется как произведение ширины ‘полоски’ на значение функции в центре ‘полоски’, далее площади суммируются главным процессом (используется равномерная сетка).
, n-число участков суммирования при численном интегрировании. Площадь каждого участка вычисляется как произведение ширины ‘полоски’ на значение функции в центре ‘полоски’, далее площади суммируются главным процессом (используется равномерная сетка).

Очевидно, что распараллеливание этой задачи легко сделать, если каждый процесс будет считать свою частичную сумму, а затем передаст результат вычислений главному процессу. Как избежать здесь повторяющихся вычислений? Процесс должен знать свой ранг, общее число процессов и число интервалов, на которое будет разбит отрезок (чем больше интервалов, тем выше будет точность). Тогда в цикле от 1 до числа интервалов процесс будет вычислять площадь полоски на i-ом интервале, а затем переходить не на следующий i+1интевал, а на интервал i+m, где m-число процессов. Как мы уже знаем, для получения ранга и общего числа процессов существуют функции MPI_Comm_rank и MPI_Comm_size. Перед началом вычислений главный процесс должен передать всем остальным число интервалов, а после вычислений собрать у них полученные частичные суммы и просуммировать их, в MPI это реализуется передачей сообщений. Для передачи сообщений здесь удобно использовать функцию коллективного взаимодействия MPI_Bcast, которая рассылает одинаковые данные от одного процесса всем остальным. Для сбора частичных сумм есть 2 варианта - можно использовать MPI_Gather, которая собирает данные со всех процессов и отдает их одному (получается массив из m элеменов, где m-число процессов) или MPI_Reduce. MPI_Reduce действует аналогично MPI_Gather – собирает данные от всех процессов и отдает одному, но не в виде массива, а предварительно производит определенную операцию между элементами массива, например, суммирование и после этого отдает один элемент. Для этой задачи более удобным выглядит использование MPI_Reduce. Текст программы приведен ниже
#include "mpi.h"
#include <stdio.h>
#include <math.h>
double f(double a)
{
return (4.0 / (1.0 + a*a));
}
int main(int argc, char *argv[])
{
int n, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x;
double startwtime, endwtime;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);
n = 0;
if (myid == 0)
{
n=100;
startwtime = MPI_Wtime();
}
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD);
h = 1.0 / (double) n;
sum = 0.0;
for (i = myid + 1; i <= n; i += numprocs)
{
x = h * ((double)i - 0.5);
sum += f(x);
}
mypi = h * sum;
MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD);
if (myid == 0)
{
printf("pi is approximately %.16f, Error is %.16f\n",
pi, fabs(pi - PI25DT));
endwtime = MPI_Wtime();
printf("wall clock time = %f\n",
endwtime-startwtime);
}
MPI_Finalize();
return 0;
}
Рассмотрим подробнее вызовы функий MPI_Bcast и MPI_Reduce:
MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD) – содержимое переменной n и одного элемента типа MPI_INT из процесса с рангом 0 посылается всем остальным процессам (MPI_COMM_WORLD – все процессы в коммуникаторе) в ту же переменную n. После этого вызова каждый процесс будет знать общее число интервалов. По окончании вычислений MPI_Reduce(&mypi, &pi, 1, MPI_DOUBLE, MPI_SUM, 0, MPI_COMM_WORLD) суммирует (параметр MPI_SUM) значения из переменных mypi типа MPI_DOUBLE каждого процесса и записывает результат в переменную pi процесса с рангом 0. Для замера времени вычислений главный процесс использует функцию MPI_Wtime.
double MPI_Wtime();
MPI_Wtime возвращает число секунд в формате числа с плавающей точкой, представляющее время, прошедшее с момента старта программы.
Вычисление числа π методом Монте-Карло
Для вычисления значения πможно использовать метод ‘стрельбы’. В применении к данному случаю метод заключается в генерации равномерно распределенныхна двумерной области [0 ≤ x ≤ 1, 0 ≤ y ≤ 1] точек и определении  .
.
Вычисленное таким образом значение π является приближенным, в общем случае точность вычисления искомого значения повышается с увеличением числа ‘выстрелов’ и качества генетатора случайных чисел; подобные методы используются в случае трудностей точной числовой оценки.
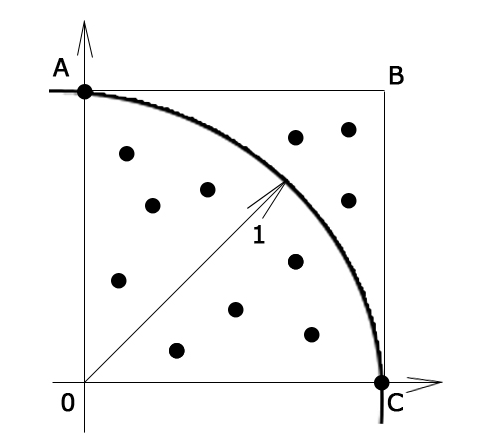
Параллельный алгоритм вычисления числа π данным методом во многом похож на предыдущий рассмотренный нами алгоритм. Для генерации случайных чисел нужно использовать функцию srand, которой в качестве агрумента (семени последовательности) задавать ранг процесса, таким образов, у каждого процесса будет своя последовательность.
#include <stdlib.h>
void srand(unsigned seed);
Функция srand() устанавливает исходное число для последовательности, генерируемой функцией rand().
#include <stdlib.h>
int rand(void);
Функция rand() генерирует последовательность псевдослучайных чисел. При каждом обращении к функции возвращается целое в интервале между нулем и значением RAND_MAX.
Для сбора результата здесь также удобно использовать MPI_Reduce с заданием операции суммирования (MPI_SUM), затем разделить полученную сумму на число процессоров, получив среднее арифметическое.
int MPI_Reduce(void* sendbuf, void* recvbuf, int count,
MPI_Datatype datatype, MPI_Op op, int root, MPI_Comm comm);
Параметры:
sendbuf адрес посылающего буфера
recvbuf адрес принимающего буфера
count количество элементов в посылающем буфере (целое)
datatype тип данных элементов посылающего буфера
op операция редукции
root номер главного процесса (целое)
comm коммуникатор
int MPI_Bcast(void *buffer, int count, MPI_Datatype datatype, int root,
MPI_Comm comm);
Параметры:
buffer адрес посылающего/принимающего буфера
count количество элементов в посылающем буфере (целое)
datatype тип данных элементов посылающего буфера
root номер главного процесса (целое)
comm коммуникатор
Задание: в соответствии с номером варианта откомпилировать и запустить параллельную программы, вычисляющую число π по заданному алгоритму.
Запустить задачу на одном узле и с кластера, на заданном количестве узлов. Оценить время выполнения вычислений, точность и коэффициент распараллеливания Амдала с учетом сетевой задержки теоретически и по результатам выполнения работы.
Варианты заданий
| № Варианта | Алгоритм | Число процессоров | Число итераций на каждом процессоре |
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло | |||
| Численное интегрирование | |||
| Монте-Карло |
Содержание отчета
· Постановка задачи, вариант.
· Текст параллельной программы на языке С согласно заданию.
· Результаты запуска программы на одном узле, время выполнения ti, результат вычислений, ошибка.
· Результаты запуска программы на сервере, время выполнения, результат вычислений, ошибка.
· Описать параллельный алгоритм, информационные потоки при выполнении программы и загрузку КЭШ-памяти узлов. Вычислить по результатам работы программы коэффициент Амдала - Кj.
· Учитывая результаты работы группы студентов, построить гистограмму зависимости Кj , ti от количества процессоров участвующих в вычислениях.
· Выводы. Рекомендации по улучшению быстродействия программы.
|
|
|
|
|
Дата добавления: 2014-12-26; Просмотров: 643; Нарушение авторских прав?; Мы поможем в написании вашей работы!