КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Ввод-вывод
|
|
|
|
H-файлы и программные модули
Для этой цели в Си предусмотрено использование заголовочных файлов (h-file). Такой файл содержит описания заголовков (прототипов) процедур и описания пользовательских типов, использующихся при обращении к этим процедурам. В состав программы пользователя подобный заголовочный (header) файл включается с помощью директивы #include. Имя подобного файла обычно совпадает с именем модуля.
Знание состава h-файла модуля позволяет программистам-пользователям писать свои программы не отвлекаясь на то, как соответствующая функция будет реализована в модуле. Таким образом удаётся распараллелить между несколькими разработчиками написание программ большой системы. Им оказывается достаточным договориться о прототипах вызовов и поддерживать в актуальном состоянии библиотеку h-файлов системы.
Для средней системы (50 — 100 тысяч строк программного текста) обычно оказывается достаточно поддерживать в процессе разработки три уровня заголовочных файлов. Нижний уровень соответствует программным модулям. Промежуточный — функциональным областям. ФО — функциональная область. Это группа модулей, отвечающих за реализацию некоторой локальной функции системы. Например, расчёт местоположения, планирование маневра, управление двигателем и т.п. Верхний уровень, обычно не более двух файлов, содержит определения типов и констант, общих для всей системы. В том числе в одном из файлов верхнего уровня могут вводиться принятые в проекте соглашения об именах (см. 4.1.1), определения типа BITSET и тому подобное. Во втором — описания типов данных, которые являются общими для всех функциональных областей (описание битового формата слова ARINC-протокола, принятые в проекте константы и прочее).
В ряде случаем можно порекомендовать структуру, условно называемую 2*2 (два по два). Её идея в том, что на каждую функциональную область создаётся 2 h-файла. Первый – внешний, содержит экспортируемые определения типов, констант, и заголовков процедур. Второй – внутренний, используется только для локальных для данной функциональной области объектов. Если к этому добавить ещё и соглашения о том, чтобы все импортируемые имена имели префикс уникальный для каждой ФА, то чтение (анализ) текстов программных кодов существенно упрощается.
Как и большинство языков компактного типа, Си не содержит собственных средств ввода-вывода. Для этой цели используется богатая библиотека программных модулей частично стандартизованная. Для простых целей чаще всего программист пользуется услугами программного модуля stdio, соответственно включая текст его макроподстановкой:
#include <stdio.h>
тем самым модулю пользователя (включившему описания стандартного ввода-вывода) становятся доступными определение типа FILE, процедуры потокового ввода и вывода данных fopen, putc, getc, putchar, getchar, fclose и ряд констант: NULL, EOF.
Кроме того, импортирующий модуль может воспользоваться процедурами форматного преобразования printf, fprintf и sprintf, описания которых тоже включены в stdio. Процедуры printf и fprintf обеспечивают выполнение форматных преобразований при выводе в файл, а sprintf производит преобразование в форму выходной строки — своего первого параметра. Процедура printf не требует указывать имя файла вывода, так как осуществляет его стандартный выходной поток stdout.
По умолчанию в программе связываются с терминалом пользователя три файла: входной — stdin, выходной - stdout и файл сообщений об ошибках - stderr. Все они относятся к потоковому вводу-выводу, когда перенос данных из входного буфера (a) в зону обработки программы (b) и из зоны (b) в выходной буфер обмена (с) (См. Рис.6) рассматриваются как непрерывная последовательности символов.
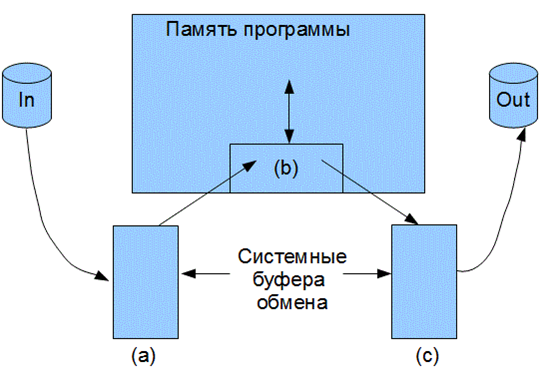
Рисунок 6. Схема форматированного ввода-вывода
На самом деле, система ввода-вывода (вместе с исполнительной средой операционной системы компьютера) обменивается с внешними устройствами блоками данных, используя для этого системные области (буфера обмена). По мере потребности, по запросам команд ввода программы данные из текущей точки буфера (а) переносятся в зону обработки в память программы (b). При этом среда поддержки ввода вывода, реализованная в библиотеке stdio Си, например процедуры scanf, fscanf, может выполнять форматные преобразования символов потока.
Так последовательность символов '3' и '5' может быть перенесена в зону (b) без изменений в виде двух байт с кодом:
или может быть преобразована по числовому формату %2d к двоичному числу:
То есть, в первом случае они останутся символами в кодировке ASCII, а во втором предстанут в форме числа 35, записанного в прямом двоичном коде.
Аналогичные преобразования предусмотрены и при выводе, когда содержимое памяти из зоны программы переносится побайтово без изменений, либо преобразуется из числовой формы в символьную форму записи. В последнем случае, они могут быть выведены на экран или распечатаны в форме привычной для человека.
Как при вводе, так и при выводе, обычно, надо указывать длину символьной последовательности обрабатываемой или формируемой в потоке при преобразовании. При вводе, стоит ещё подумать об обработке возможных ошибок. Что если вместо цифровых символов в потоке окажутся буквы или какие-либо другие символы? Стандартное преобразование окажется невозможным и программа «сломается». Скорее всего её выполнение будет просто прервано.
Хороший стиль программирования предполагает, что программа введёт любые данные как символы, и лишь потом будет сама разбираться, что с ними делать. А если пользователь ошибочно ввёл неправильные значения — сообщит ему об этом и попросит исправить ошибку.
Но даже просто при вводе последовательности символов могут возникнуть ошибки. Например, если необходимо считать строку со стандартного потока ввода, то первое и самое простое – это использование функции scanf.
#include <stdio.h>
int main()
{
char instr[300];
printf("Input string:\n");
scanf("%s", instr);
return 0;
}
Но что произойдет, если будет введено больше 300 символов? В функции scanf контроля длины вводимой строки не происходит, она не знает, какого размера в программе переменная instr. Получается, что все символы, не поместившиеся в массив instr будут записываться дальше в память, которая может использоваться другими переменными. Эта ситуация называется переполнением. При определенных обстоятельствах (когда память после массива действительно используется), рассмотренный вариант вызовет ошибку, но не при чтении, а позже, при обращении к переменным, которые располагаются в памяти после массива. Такие ошибки очень сложно отловить, т.к. они проявляются не в том месте, где допущены.
Как же поступать? У функции scanf в спецификаторе ввода можно задать ограничение на длину считываемой строки:
scanf("%300s", instr);
и тогда со стандартного потока ввода не будет считано более 300 символов, независимо от того, сколько их реально было введено. Таким образом, при чтении данных всегда надо учитывать возможность переполнения. Отследить переполнение можно и вручную, например, считывая по одному символу:
int i=0;
while ((*(instr+i) = getc(stdin))!='\n' && i++<300);
*(instr+i)='\0';
Считывание происходит посимвольно, пока не встретится символ конца строки (символ '\n') или пока количество считанных символов не достигнет 300.
Следует обратить внимание на то, что в случае использования scanf, если внутри строки будет содержаться пробел, то строка будет считана до пробела. Дело в том, что пробел, как и символ табуляции, считается разделителем, и многие функции работы со строками используют этот разделитель. Происходит ситуация, когда некоторые символы в строке интерпретируются по особому. Поэтому при использовании библиотечных функций надо это учитывать. И когда необходимо считать строку до символа конца строки (а не до разделителя), следует использовать либо посимвольное чтение (показанное ранее), либо более сложную функцию, например, fgets:
fgets(instr,300,stdin);
В качестве примера рассмотрим чтение с клавиатуры и последующее кодирование строки.
/*
Date: 10 May 2011
Description: string reading and encoding sample
*/
#include <stdio.h>
const int STARTD = 97; /* 'a' code */
const int ENDD = 122; /* 'z' code */
/**********************************************************************
*
* Name: testString
*
* Purpose: checks whether string contains anything
* except English small characters
* Input: str (string to check)
* Output: none
* Return:
* -1 bad string
* 0 good string (only small English characters)
*
********************************************************************/
int testString(char *str)
{
int i = 0;
for(; *(str+i)!='\0'; i++) {
if ((*(str+i) < STARTD) || (*(str+i) > ENDD)) {
return -1;
}
}
return 0;
}
/**********************************************************************
*
* Name: replaceLineEnd
*
* Purpose: replaces ending '\n' (if exists)
* symbol by '\0' symbol
* except English small characters
* Input: str (string)
* Output: str (string)
* Return: none
*
********************************************************************/
void replaceLineEnd(char *str) {
int i;
char temp[2];
for(i=0; ((*(str+i)!='\n') && (*(str+i)!='\0')); i++);
if (*(str+i) == '\0') {
/* empty input buffer */
while (temp[0]!= '\n') {
fgets(temp,2,stdin); /* reads 1 symbol + 1 end */
}
}
if (*(str+i) == '\n') {
*(str+i) = '\0';
}
}
/**********************************************************************
*
* Name: readString
*
* Purpose: reads string from keyboard, and tests
* whether it is a correct string
* Input: str (empty string)
* Output: str (inputted string)
* Return:
* -1 bad string
* 0 good string
*
********************************************************************/
int readString(char *str)
{
/* reads only 11 chars from keyboard */
fgets(str,12,stdin);
replaceLineEnd(str);
return testString(str);
}
/**********************************************************************
*
* Name: encodeAtbash
*
* Purpose: encodes string str using Atbash code
* Input: str (string)
* Output: str (encoded string)
* Return: none
*
********************************************************************/
void encodeAtbash(char *str)
{
int tmp;
while (*str)
{
if ((int)*str >= STARTD && (int)*str <=ENDD) {
tmp = ENDD + STARTD - (int)*str;
*str = (char)tmp;
}
str++;
}
}
int main()
{
char str[12]; /* max length 11 + 1 for ending symbol */
printf("Enter string to encode: ");
if (readString(str) < 0) {
printf("Incorrect string, exiting");
return 0;
}
encodeAtbash(str);
printf("Encoded string: %s",str);
return 0;
}
В данном примере строка хранится в переменной str для которой выделено 12 байт статической памяти. Выделение происходит при компиляции программы, т.к. переменная определена как массив char. Можно было бы задать str как указатель на char, в этом случае необходимо выделить память самостоятельно:
str = (char*) malloc(12);
и строка располагалась бы в динамической памяти.
Из выделенных 12 байт один используется для хранения символа конца строки ‘\0’, для хранения символов самой строки остается 11 байт.
Чтение строки реализовано в функции readString и выполняется при помощи стандартной функции fgets. Она предназначена для работы с файлами (с потоками), но позволяет задать максимальное количество считываемых символов. Второй параметр этой функции – это размер буфера, в который происходит считывание строки и fgets обеспечивает не переполнение этого буфера. При таком подходе никогда не произойдет переполнение строки str – больше 11 символов считано не будет. В конце функция добавляет символ конца строки (при считывании 11 символов он окажется 12-м). Т.к. fgets создана для работы с потоками, то считывает из стандартного потока ввода (клавиатуры) символ конца строки ‘\n’. Поэтому его надо удалить из строки, т.к. определение строки в Си подразумевает символ ‘\0’ в качестве конца строки без предшествующего ему символа переноса строки. Удаление (а точнее замена символа переноса строки на конец строки) выполнено в функции replaceLineEnd.
Дополнительно в функции replaceLineEnd реализован сброс буфера ввода:
if (*(str+i) == '\0') {
/* empty input buffer */
while (temp[0]!= '\n') {
fgets(temp,2,stdin); /* reads 1 symbol + 1 end */
}
}
Вызов
fgets(str,12,stdin);
приведет к считыванию из стандартного потока ввода только 11 символов и если пользователь введет более 11 символов, то в буфере ввода останутся введенные пользователем символы. Чтобы следующее считывание обеспечило ввод новых данных из потока, необходимо очистить (сбросить) буфер ввода. В приведенном примере для этого происходит последовательное считывание из буфера по одному символу, пока не будет встречен символ перевода строки, которым пользователь закончил ввод.
Для кодирования строки выбран алгоритм «Атбаш». Упоминание об его использовании встречается в Библии. Книга пророка Иеремии глава 25, стих 26 содержит текст: "И всех царей севера, близких друг к другу и дальних, и все царства земные, которые - на лице земли, а царь Сессаха выпьет после них". Слово "Сессах" не является ни ошибкой, ни искажением библейского текста, хотя такого царя или царства в истории не существовало. Священные тексты древних иудеев шифровались шифром простой замены "Атбаш". Алгоритм этого шифра прост: первая буква алфавита заменялась на последнюю, вторая - на предпоследнюю в алфавите и т.д. После дешифрации на языке оригинала (для успешной дешифрации необходимо знать язык сообщения) слова "Сессах" получается "Вавилон". По смыслу алгоритма функция, реализующая шифровку и зашифровку, одна и та же.
Алгоритм подразумевает кодирование строки, состоящей из символов конкретного алфавита, в примере реализации выбран английский алфавит, точнее его прописные символы. Перед началом кодирования введенная строка проверяется на допустимость функцией testString. Т.к. прописные символы английского алфавита расположены последовательно в таблицы кодировки символов ASCII, то достаточно проверить каждый символ введенной строки на принадлежность определенному диапазону кодов по таблице ASCII.
В функции кодирования encodeAtbash для доступа к символами строки используется синтаксис работы с указателем. Чтобы получить текущий символ используется выражение *str. Для перехода к следующему символу выполняется str++. Можно реализовать эту функцию иначе, с использованием механизма работы с массивом:
void encodeAtbash(char *str)
{
int tmp;
int i;
i = 0;
while (str[i])
{
if ((int)str[i] >= STARTD && (int)str[i] <=ENDD) {
tmp = ENDD + STARTD - (int)str[i];
str[i] = (char)tmp;
}
i++;
}
}
Более того, даже параметр функции можно указать не как ссылку на char, а как «открытый» массив:
void encodeAtbash(char str[])
В этом случае, несмотря на то, что в Си нет динамических массивов, и их размер должен указываться при инициализации, при передаче параметров допускается указывать «открытые» массивы. Но тогда разработчик должен самостоятельно позаботиться о том, чтобы сообщить функции размер конкретного массива, который передается в ходе работы программы. В приведенном примере передаваемая строка всегда заканчивается символом конца строки ‘\0’, поэтому можно последовательно перебирать элементы массива, пока не встретиться символ ‘\0’ и не опасаться выйти за границы массива. Если же конечного символа не предусматривается (в большинстве случаев в массиве хранятся не строки, а единообразные данные, не заканчивающиеся никаким специальным элементом) то размер массива следует передать дополнительно:
void encodeAtbash(char str[], int arrayLength)
{
int i;
for (i = 0; i < arrayLength; i++) {
…
}
…
}
А теперь вернемся к задаче, рассмотренной ранее в Главе 2 и посмотрим, как будет выглядеть реализация программы, соответствующая сформулированным требованиям.
Чтение строки может быть выполнено аналогично приведенному примеру кодирования строки алгоритмом «Атбаш», но считывать необходимо не 11, а 81 символ. Последний, 81 символ нужен, чтобы обработать ситуацию, когда пользователь ввел более 80 символов.
/*
Date: 10 May 2011
Description: string reading and encoding sample 2
*/
#include <stdio.h>
/**********************************************************************
*
* Name: isEnglishLetter
*
* Purpose: checks whether the symbol belongs to
* English alphabet
* Input: c - symbol
* Output: none
* Return: 1 – belongs, 0 – do not belongs
*
********************************************************************/
int isEnglishLetter(char c) {
if((c >= 'a') && (c <= 'z')) {
return 1;
}
if ((c >= 'A') && (c <= 'Z')) {
return 1;
}
return 0;
}
/**********************************************************************
*
* Name: isRussianLetter
*
* Purpose: checks whether the symbol belongs to
* Russian alphabet
* Input: c - symbol
* Output: none
* Return: 1 – belongs, 0 – do not belongs
*
********************************************************************/
int isRussianLetter(char c) {
if((c >= 'а') && (c <= 'я')) {
return 1;
}
if ((c >= 'А') && (c <= 'Я')) {
return 1;
}
return 0;
}
/**********************************************************************
*
* Name: isNumber
*
* Purpose: checks whether the symbol is number
* Input: c - symbol
* Output: none
* Return: 1 – number, 0 – not a number
*
********************************************************************/
int isNumber(char c) {
if(((int)c >= (int)'0') && ((int)c <= (int)'9')) {
return 1;
}
return 0;
}
/**********************************************************************
*
* Name: isDelimeter
*
* Purpose: checks whether the symbol is a delimiter
* Input: c - symbol
* Output: none
* Return: 1 – delimiter, 0 – not a delimiter
*
********************************************************************/
int isDelimeter(char c) {
if((c == ',') || (c == '.') || (c == ' ') || (c == '\0')) {
return 1;
} else {
return 0;
}
}
/**********************************************************************
*
* Name: testString
*
* Purpose: test string for correctness
* (according requirements)
* Input: str (string to check)
* Output: none
* Return:
* -1 bad string
* 0 good string (only acceptable characters)
*
********************************************************************/
int testString(char *str)
{
int start;
int goodSymb;
int count;
count = 0;
start = 0;
while(*str) {
goodSymb = 0;
if (isEnglishLetter(*str)) {
start = 1;
goodSymb = 1;
}
if (isRussianLetter(*str)) {
start = 1;
goodSymb = 1;
}
if (isNumber(*str)) {
start = 1;
goodSymb = 1;
}
if ((*str) == ' ') {
goodSymb = 1;
}
if ((isDelimeter(*str)) && start) {
goodSymb = 1;
}
if (goodSymb == 0) {
return 0;
} else {
str++;
count++;
}
}
if (count > 10) {
return 0;
} else {
return 1;
}
}
/**********************************************************************
*
* Name: replaceLineEnd
*
* Purpose: replaces ending '\n' (if exists)
* symbol by '\0' symbol
* except English small characters
* Input: str (string)
* Output: str (string)
* Return: none
*
********************************************************************/
void replaceLineEnd(char *str) {
int i;
char temp[2];
for(i=0; ((*(str+i)!='\n') && (*(str+i)!='\0')); i++);
if (*(str+i) == '\0') {
/* empty input buffer */
while (temp[0]!= '\n') {
fgets(temp,2,stdin);
}
}
if (*(str+i) == '\n') {
*(str+i) = '\0';
}
}
/**********************************************************************
*
* Name: readString
*
* Purpose: reads string from keyboard
* Input: str (empty string)
* Output: str (inputted string)
* Return: none
*
********************************************************************/
void readString(char *str)
{
/* reads only 81 chars from keyboard, 82 sets to '\0' */
fgets(str,82,stdin);
replaceLineEnd(str);
}
/**********************************************************************
*
* Name: change231
*
* Purpose: encodes word in string str using 231 exchange
* Input: str (string),
* startPos – position in string
* where the word starts from
* Output: str (encoded string)
* Return: encoded word end position in str
*
********************************************************************/
int change231(char *str, int startPos) {
int i;
char temp;
i = startPos + 1;
while (!isDelimeter(str[i])) {
temp = str[i];
str[i] = str[i-1];
str[i-1] = temp;
i++;
if (((i-startPos)%3 == 0) && (!isDelimeter(str[i]))) {
i++;
}
}
return i;
}
/**********************************************************************
*
* Name: processString
*
* Purpose: encode words in string
* leaving delimiters unchanged
* Input: str (string),
* Output: str (encoded string)
* Return: none
*
********************************************************************/
void processString(char *str) {
int i;
i = 0;
while(*(str+i)!= '\0') {
if (isDelimeter(*(str+i))) {
i++;
} else {
i = change231(str, i);
}
}
}
int main()
{
/* max length 80 + 1 for ending symbol
+ 1 to test >80 entered symbols */
char str[82];
printf("Введите строку для кодирования\n");
readString(str);
while(*str!= '\0') {
if (testString(str) == 0) {
printf("Ошибка во входной строке\n");
} else {
processString(str);
printf("%s\n", str);
}
printf("Введите строку для кодирования\n");
readString(str);
}
printf("Работа закончена");
return 0;
}
Проверка корректности строки выделена в функцию testString, которая последовательно рассматривает каждый символ строки и проверяет, принадлежит ли он английскому алфавиту и/или русскому и/или является цифрой и/или разделителем. В начале допускаются в качестве разделителей только пробелы, поэтому используется дополнительная переменная start. Исходно она равна нулю и только после появления в строке символа алфавита и/или цифры она становится равна 1. Пока start равна нулю допускается только пробел в качестве разделителя:
if ((*str) == ' ') {
goodSymb = 1;
}
а когда start равна единице допускается любой разделитель (точка, запятая, пробел).
if ((isDelimeter(*str)) && start) {
goodSymb = 1;
}
Кодирование строки выполнено в один проход. В данной задаче сложность алгоритма определяется количеством проходов по строке, поэтому их желательно минимизировать. Разделители остаются без изменения. Когда встречается слово, оно кодируется в функции change231, в которую передается вся строка и позиция начала слова. После кодирования слова функция change231 возвращает позицию конца слова (номер следующего за концом слова символа).
Сама перестановка символов выполнена последовательно попарно. Требуемый результат – 231 получается, если сначала переставить первый символ со вторым (получив 213) и далее второй с третьим (получив как раз 231). Такой подход оказывается справедлив и в случае, когда остается два символа (12 – 21). Т.е. алгоритм перестановки сводится к работе лишь с двумя рядом стоящими символами (перемене их мест). Однако требуется перестановка только в рамках тройки символов, поэтому на каждом третьем шаге следует пропустить одну позицию:
if (((i-startPos)%3 == 0) && (!isDelimeter(str[i]))) {
i++;
Алгоритм основной программы уже был определен ранее.
(1) Вести входную строку.
(2) Если строка пустая, то закончить работу.
(3) Преобразовать входную строку.
(4) Вывести преобразованную строку.
(5) Ввести очередную входную строку и вернуться к действию(2).
Соответственно будет выглядеть и реализация.
(1) Вести входную строку:
printf("Введите строку для кодирования\n");
readString(str);
(2) Если строка пустая, то закончить работу:
while(*str!= '\0') {
...
}
printf("Работа закончена");
return 0;
(3) Преобразовать входную строку:
if (testString(str) == 0) {
printf("Ошибка во входной строке\n");
} else {
processString(str);
printf("%s\n", str);
}
(4) Вывести преобразованную строку:
processString(str);
printf("%s\n", str);
(5) Ввести очередную входную строку и вернуться к действию(2):
while(*str!= '\0') {
...
printf("Введите строку для кодирования\n");
readString(str);
}
|
|
|
|
|
Дата добавления: 2014-12-26; Просмотров: 445; Нарушение авторских прав?; Мы поможем в написании вашей работы!