КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Основные модели и инструменты описания архитектуры информации
|
|
|
|
Результатами процесса разработки архитектуры информации являются:
· документированное описание существующих источников данных;
· модели данных. Специалисты Gartner не рекомендуют, однако, тратить избыточные усилия на создание единой, полной и детальной модели в рамках всего предприятия, так как затраты на ее разработку и последующее поддержание могут быть неадекватны получаемым выгодам. Основное внимание стоит уделять выявлению семантической разницы в описаниях данных, поступающих из различных источников, и созданию относительно стабильных так называемых "канонических" представлений данных, описывающих их использование бизнес-пользователями;
· описание существующих и планируемых информационных потоков, соответствующих интерфейсов, алгоритмов преобразования или консолидации данных, а также необходимые соглашения по уровню сервиса, связанного с передачей данных;
· описание решений по организации хранения данных – от общих каталогов до витрин и хранилищ данных;
· используемые технологии и средства для преобразования и управления данными.
Целью разработки моделей информации и моделей данных является создание графических представлений потребностей организации и отдельных бизнес-процессов в информации. Это становится основой для реорганизации бизнес-процессов и конструирования новых прикладных систем, описания взаимодействий и информационного обмена, который происходит между организацией и клиентами, партнерами.
Естественным для архитектурного процесса является рассмотрение моделей информации на различных уровнях абстракции. Действительно, представление о таком информационном объекте как "клиент" у руководителя высокого уровня отличается от более точного представления у представителя по продажам или у маркетолога, которые мыслят в терминах более детальной сегментации заказчиков. Наконец, разработчик архитектуры информационной системы представит этот объект в форме некоторой сущности со строго определенным набором атрибутов. Этот процесс декомпозиции "сверху-вниз" является ключевым для создания архитектуры информации. Модели информации и политики, созданные в результате такого анализа, окажут существенное влияние на логическую и физическую структуру баз данных.
На концептуальном уровне достаточно высокоуровневых моделей, описывающих информационные потоки между функциональными подразделениями организации в самом общем виде. Эти потоки не связаны с какой-то отдельной прикладной системой и не уточняют методы доступа или физического хранения информации, т.е. рассматриваются на бизнес-уровне без описания проблем практической реализации.
На уровне логического описания модели информации и данных описывают требования к информации в форме и терминах, понятных бизнес-пользователям. Процесс моделирования на логическом уровне обеспечивает средства обнаружения, анализа, определения, стандартизации и нормализации отношений между бизнес-процессами и прикладными системами, идентификацию потоков информации и соответствующих элементов данных, которые требуются организации. Процессы, информационные потоки и элементы данных являются логическими фактами, которые организация должна поддерживать для выполнения бизнес-операций. Этот уровень анализа уже позволяет идентифицировать общие элементы данных, которые используются разными организационными единицами и разными бизнес-процессами, что позволяет уменьшить пересечения и конфликты между этими элементами. Однако он не зависит от способа хранения информации в базе данных.
При этом модель используется для сбора и анализа требований к данным и включает в себя такие элементы, как сущности, атрибуты, отношения и количество вхождений.
· Сущностями являются такие объекты, как "клиент", "гражданин", "заказ", "место", "вещь или объект" и т.д. Совокупность сущностей одного типа становится таблицей в базе данных, а строка этой таблицы – это одна реализация некоторой сущности.
· Атрибут является характеристикой, которая обеспечивает более детальную информацию о сущности (объекте), например, "фамилия", "имя", "пол" и т.д. Атрибут становится колонкой в таблице базы данных. Ключевой атрибут, или первичный ключ, является уникальным идентификатором сущности. Примером является серийный номер.
· Отношения показывают, как одна сущность соотносится с другой. При описании связи представлены глаголами, поскольку означают действие. Примером может быть высказывание "гражданин владеет недвижимостью": сущность "гражданин" "владеет" некоторой другой сущностью "недвижимость". Когда между сущностями установлены связи, то одна сущность является "родителем", а другая "потомком".
· Количество вхождений показывает, какое количество сущностей может состоять в отношениях с другой сущностью. Например, гражданин может владеть несколькими объектами недвижимости.
Одним из способов моделирования данных на логическом уровне является построение моделей "Сущности-Отношения" (ERM – Entity-Relationship Model).
На физическом уровне даются точные ответы на вопросы типа: "Какие данные требуются для того, чтобы реализовать логику бизнес-процесса соответствующей прикладной системой?", "Сколько требуется различных информационных объектов (сущностей)?", "Каков набор элементов данных каждой сущности?". Физическая модель данных служит, по сути, представлением того, как данные, приведенные в логической модели, будут храниться в системе управления базами данных.
Сравнительные характеристики этих уровней (с использованием идеи систематизации из [4.19] приведены в таблице 5.6.
| Таблица 5.6. | |||
| Модель/уровень | Концептуальная | Модель данных | Реализация данных |
| Точка зрения | Бизнес-взгляд на ИТ | ИТ-взгляд на бизнес | ИТ-взгляд на ИТ |
| Фаза | Планирование | Анализ | Реализация |
| Рассматриваемые связи | Связи данных с бизнес-функциями, интерфейсами, технологиями | Связи данных с другими данными | Связи данных с системами хранения |
| Фокус | Сбор, обработка и использование данных | Структура данных | Объемы и степень использования данных |
| Это, скорее… | Искусство? | Наука? | Религия? (cледование рекомендациям вендоров) |
При разработке данной архитектуры необходимо помнить об использовании в организации как структурированной, так и неструктурированной информации. Многие исследования показывают, что люди, принимающие решения, только на одну треть полагаются на информацию из структурированных источников (документы и отчеты, генерируемые компьютерными системами). Две трети источников по значимости в плане принятия решений – это информация, получаемая в результате встреч, телефонных разговоров, участия в конференциях и пр. Это должны помнить и учитывать специалисты, отвечающие за разработку архитектуры информации.
Еще одним важным понятием, относящимся к архитектуре информации, которое является особенно серьезным для крупных организаций или органов государственной власти с их большим количеством достаточно независимых систем и организационных структур (на национальном, региональном или муниципальном уровнях), является управление федеративными данными и метаданными (federated data management) [4.17]. Под управлением федеративными данными понимается архитектура, которая обеспечивает управление и доступ к данным и метаданным независимо от их внутренней логической структуры и физических границ их расположения, в целях организации взаимодействия систем и различных подразделений внутри организации и с внешними организациями.
Рисунок 5.10 показывает общее видение принципов управления федеративными данными, который, в частности, положен в основу справочной модели архитектуры данных методики Федеральной архитектуры США FEAF[4.15].
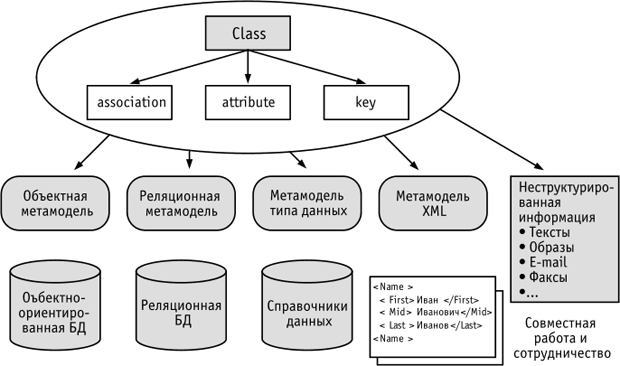
Рис. 5.10. Видение принципов управления федеративными данными
Идея заключается в использовании общей метамодели, которая позволяет управлять отношениями между различными "оригинальными" (native) моделями данных и таким образом делать их прозрачными на корпоративном уровне.
Любая попытка интегрировать данные и информацию между различными системами в конечном итоге основывается на обнаружении и использовании метаданных этой системы (метаданные – это данные о данных системы). Получение информации о метаданных – это только половина проблемы. Вторая, гораздо более важная половина проблемы связана с определением отношений между метаданными одной системы с аналогичными метаданными другой.
Суть федеративных данных состоит в одинаковом определении на некотором новом уровне абстракции общих элементов данных для различных информационных систем предприятия. При этом данные (например, о клиенте или гражданине) могут быть описаны различным образом в каждой системе, таблице базы данных, в которых они встречаются. Определения включают такие атрибуты, как имена полей, длину, формат чисел, формат дат, диапазон значений и т.д. Однако при этом имеются объединяющие их общие виртуальные модели. Если это достигнуто, то гораздо проще реализовать обмен данными между системами.
Рисунок 5.11 иллюстрирует принципы интеграции информации на основе управления федеративными данными.
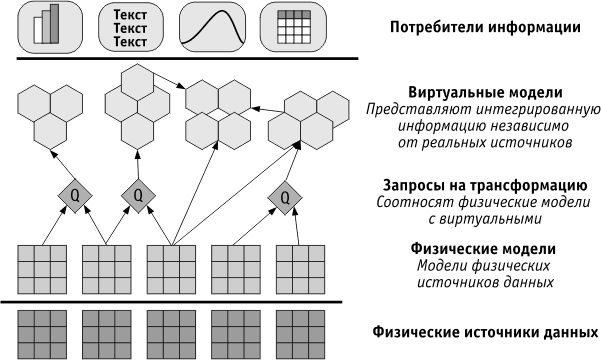
Рис. 5.11. Принципы интеграции через управление федеративными данными
В нижней части рисунка мы имеем набор различных физических систем управления данными. Уровень выше представляет набор моделей этих систем, независимых от платформы реализации. Уровень запросов выполняет трансформацию и устанавливает соответствие для создания виртуальных моделей объектов, чьи физические аналоги могут и не существовать в физических системах. Эти виртуальные модели для различных пользователей могут представляться по-разному – например, базами данных, бизнес-объектами, представлениями (выборки из базы), моделями данных предприятия, документами, сервисами или компонентами в зависимости от потребностей. Важно то, что определения этих объектов создаются с помощью моделей. В связи с этим серьезную роль может играть стандарт Meta Object Facuility (MOF), который и помогает определять все необходимые модели для метаданных.
Частью процесса описания архитектуры является сбор информации, которая определяет объекты в виде "как есть", определение целевого состояния, а также плана перехода из текущего состояния в целевое. Это верно и для Архитектуры информации, и для моделей информации. Как правило, текущее состояние архитектуры информации описывается с использованием логических и физических моделей данных, многие из которых могут отсутствовать в репозитории метаданных предприятия. Эти модели обычно являются платформенно-зависимыми. Целевое состояние, как правило, описывается в форме платформенно-независимых семантических или виртуальных моделей. Для перехода от текущего состояния в желаемое будущее потребуется установление отображения (mapping) и трансформации между платформенно-зависимыми моделями и виртуальными моделями. Со временем, когда понадобится создание новой прикладной системы, может потребоваться отображение виртуальной модели на новую, специфическую для выбранной платформы реализации модель.
Точно так же, как и в случае с бизнес-архитектурой и со всеми остальными доменами архитектуры предприятия, в данном случае нет какого-то одного универсального средства, которое бы позволяло решить все задачи, связанные с построением архитектуры информации, и строить все необходимые модели. Однако в последнее время в этой области также идет процесс консолидации. В частности, перспективными являются средства моделирования, основанные на использовании языка UML, а также распространение возможностей языка XML и основанных на нем других стандартов.
|
|
|
|
|
Дата добавления: 2015-04-25; Просмотров: 1321; Нарушение авторских прав?; Мы поможем в написании вашей работы!