КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Поиск источников информации. Метапоисковая машина
|
|
|
|
Метапоисковая машина
Адреса наиболее популярных поисковых машин за рубежом и в России.
Зарубежные поисковые машины:
Google - www.google.com Altavista - www.altavista.com Excite - www.excite.com HotBot - www.hotbot.com Nothern Light - www.northernlight.com Go (Infoseek) - www.go.com (infoseek.com) Fast - www.alltheweb.com
Российские поисковые машины:
Яndex - www.yandex.ru (или www.ya.ru)Рэмблер - www.rambler.ru Апорт - www.aport.ru
Метапоисковая система. Обратите внимание на то, что различные поисковые системы описывают разное количество источников информации в Интернет. Поэтому нельзя ограничиваться поиском только в одной из указанных поисковых системах. Теперь познакомимся с инструментами поиска, которые не формируют собственный индекс, но умеют использовать возможности других поисковых систем. Это метапоисковые системы (поисковые службы) - системы, способные послать запросы пользователя одновременно нескольким поисковым серверам, затем объединить полученные результаты и представить их пользователю в виде документа со ссылками.
Адреса известных метапоисковых систем:
MetaCrawler - www.metacrawler.com SavvySearch - www.savvysearch.com
Обсудим проблему поиска такого источника информации, как статьи в группах новостей. Инструментами поиска в данном случае могут являться рассмотренные поисковые машины WWW, которые индексируют не только пространство WWW, но и статьи в телеконференциях и имеют специальный режим поиска именно в этом ресурсе. Поиск в группах новостей поддерживает, например, поисковый сервер Altavistа. Следует отметить, что поисковые системы WWW весьма оперативно индексируют группы новостей и содержат информацию о статьях, реально существующих в сети. Для поиска в архивах новостей существую специализированные системы, самой известной из которых является система Deja (www.deja.com). Эта система позволяет проводить как поиск отдельных статей, содержащих введенный термин, так и поиск определенных групп новостей, посвященных обсуждению заданной темы. Можно зарегистрироваться в Deja и подписаться на определенные группы новостей.
Теперь рассмотрим инструменты, позволяющие проводить поиск файлов. Многие поисковые системы WWW стали оказывать услугу поиска мультимедийных файлов (Altavista, Aport). Для этого вовсе нет необходимости знать специальные операторы, а достаточно перейти с домашней страницы по ссылкам Картинки (Images), MP3/Audio или Video к специальному режиму поиска. Поиск проводится по возможному имени файла или по тексту в комментарии к ссылке на мультимедийный файл.
Что касается поиска программного обеспечения, во всемирной паутине существуют поисковые Web-серверы с коллекциями условно-бесплатного ПО, некоторые из них специализируются на поиск программного обеспечения для Интернета или для конкретной операционной системы. Эти системы в конечном итоге приведут вас к конкретному серверу, с которого и можно скачать искомый программный продукт. Следует упомянуть серверы Archie, также оказывающие услугу поиска файлов на FTP-серверах, однако пользоваться Web-серверами гораздо удобнее.
Рассмотрим поисковые инструменты для поиска адресной информации. Введем понятие Белого(White) и Желтого (Yellow) поиска.
White-поиск - поиск адресной информации по заранее известному собственному имени адресата (имя человека или организации)
Yellow-поиск - поиск собственного имени по дополнительным признакам (по роду деятельности, по географическому признаку), а затем поиск его адресной информации.
Обычно Yellow Pages системы фактически сразу включают в себя и White Pages - у найденного адресата сразу видны его телефон и почтовый адрес. Кроме того, некоторые Yellow Pages позволяют искать просто в алфавитном списке своих абонентов (white-поиск). С другой стороны, White pages также содержат элементы yellow-поиска - кроме задания собственного имени они обычно позволяют указать название города, штата и другие, сужающие поиск, данные (что необходимо в случае многих однофамильцев). Возможно, именно поэтому многие on-line телефонные справочники, выполняющие, фактически white-поиск, называют себя Yellow pages.
Здесь приведены адреса Web-систем для поиска адресной информации для людей и организаций.
Поиск людей:
· Поиск людей на Yahoo (http://people.yahoo.com).
· Система WhoWhere (www.whowhere.com).
· Система Bigfoot (www.bigfoot.com).
Поиск организаций: раздел Желтые страницы (Yellow pages) на поисковых системах специализированные сервера www.yellowpages.com - для поиска в США и других странах.
Пользователям Internet уже хорошо известны названия таких сервисов и информационных служб, как Lycos, AltaVista, Yahoo, OpenText, InfoSeek, а без услуг этих систем сегодня практи чески нельзя найти что-либо полезное в море информационных ресурсов Сети. Но что собой представляют эти сервисы изнутри, как они устроены, почему результат поиска в терабайтных массивах информации осуществляется достаточно быстро и как устроено ранжирование документов при выдаче - все это обычно остается за кадром. Тем не менее без правильного планирования стратегии поиска, знакомства с основными положениями теории ИПС (Информационно-Поисковых Систем), насчитывающей уже двадцатилетнюю историю, трудно эффективно использовать даже такие скорострельные сервисы, как AltaVista или Lycos.
Информационно-поисковые системы появились на свет достаточно давно. Теории и практике построения таких систем посвящено множество статей, основная масса которых приходится на конец 70-х - начало 80-х годов. Среди отечественных источников следует выделить научно-технический сборник "Научно-техническая информация. Серия 2", который выходит до сих пор. На русском языке издана так же и "библия" по разработке ИПС - "Динамические библиотечно-информационные системы" Ж. Солтона [1], в которой рассмотрены основные принципы построения информационно-поисковых систем и моделирования процессов их функционирования. Таким образом, нельзя сказать, что с появлением Internet и бурным вхождением его в практику информационного обеспечения появилось нечто принципиально новое, чего не было раньше. Если быть точным, то ИПС в Internet - это признание того, что ни иерархическая модель Gopher, ни гипертекстовая модель World Wide Web еще не решают проблему поиска информации в больших объемах разнородных документов. И на сегодняшний день нет другого способа быстрого поиска данных, кроме поиска по ключевым словам. При использовании иерархической модели Gopher приходится довольно долго бродить по дереву каталогов, пока не встретишь нужную информацию. Эти каталоги должны кем-то поддерживаться, и при этом их тематическое разбиение должно совпадать с информационными потребностями пользователя. Учитывая анархичность Internet и огромное количество всевозможных интересов у пользователей Сети, понятно, что кому-то может и не повезти и в сети не будет каталога, отражающего конкретную предметную область. Именно по этой причине для множества серверов Gopher, называемого GopherSpace была разработана информационно-поисковая программа Veronica (Very Easy Rodent-Oriented Net-wide Index of Computerized Archives).
Аналогичное развитие событий наблюдается и в World Wide Web. Собственно еще в 1988 году в специальном выпуске журнала "Communication of the ACM" [2] среди прочих проблем разработки гипертекстовых систем и их использования Франк Халаз назвал в качестве первоочередной задачи для следующего поколения систем этого типа назвал проблему организации поиска информации в больших гипертекстовых сетях. До сих пор многие идеи, высказанные в той статье, не нашли еще своей реализации. Естественно, что система, предложенная Бернерсом-Ли [3] и получившая такое широкое распространение в Internet, должна была столкнуться с теми же проблемами, что и ее локальные предшественники. Реальное подтверждение этому было продемонстрировано на второй конференции по World Wide Web осенью 1994 года, на которой были представлены доклады о разработке информационно-поисковых систем для Web, а система World Wide Web Worm, разработанная Оливером МакБрайном из Университета Колорадо, получила приз как лучшее навигационное средство. Следует также отметить, что все-таки долгая жизнь суждена отнюдь не чудесным программам талантливых одиночек, а средствам, являющимся результатом планового и последовательного движения научных и производственных коллективов к поставленной цели. Рано или поздно этап исследований заканчивается, и наступает этап эксплуатации систем, а это уже совсем другой род деятельности. Именно такая судьба ожидала два других проекта, представленных на той же конференции: Lycos, поддерживаемый компанией Microsoft, и WebCrawler, ставший собственностью America On-line.
Разработка новых информационных систем для Web не завершена. Причем как на стадии написания коммерческих систем, так и на стадии исследований. За прошедшие два года снят только верхний слой возможных решений. Однако многие проблемы, которые ставит перед разработчиками ИПС Internet, не решены до сих пор. Именно этим обстоятельством и вызвано появление проектов типа AltaVista компании Digital [4], главной целью которого является разработка программных средств информационного поиска для Web и подбор архитектуры для информационного сервера Web.
Архитектура современных ИПС для WWW
Прежде чем описать проблемы построения информационно-поисковых систем Web и пути их решения рассмотрим типовую схему такой системы. В различных публикациях, посвященных конкретным системам, например [5,6], приводятся схемы, которые отличаются друг от друга только способом применения конкретных программных решений, а не принципом организации различных компонентов системы. Поэтому рассмотрим эту схему на примере, взятом из работы [6] (рис. 1).
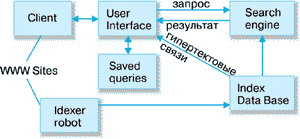
Рисунок 1. Типовая схема информационно-поисковой системы.
Client (клиент) на этой схеме - это программа просмотра конкретного информационного ресурса. Наиболее популярны сегодня мультипротокольные программы типа Netscape Navigator. Такая программа обеспечивает просмотр документов WWW, Gopher, Wais, FTP-архивов, почтовых списков рассылки и групп новостей Usenet. В свою очередь все эти информационные ресурсы являются объектом поиска информационно-поисковой системы.
User interface (пользовательский интерфейс) - это не просто программа просмотра, в случае информационно-поисковой системы под этим словосочетанием понимают также способ общения пользователя с поисковым аппаратом: системой формирования запросов и просмотров результатов поиска.
Search engine (поисковая машина) - служит для трансляции запроса на информационно-поисковом языке (ИПЯ), в формальный запрос системы, поиска ссылок на информационные ресурсы Сети и выдачи результатов этого поиска пользователю.
Index database (индекс базы данных) - индекс, который является основным массивом данных ИПС и служит для поиска адреса информационного ресурса. Архитектура индекса устроена таким образом, чтобы поиск происходил максимально быстро и при этом можно было бы оценить ценность каждого из найденных информационных ресурсов сети.
Queries (запросы пользователя) - сохраняются в его (пользователя) личной базе данных. На отладку каждого запроса уходит достаточно много времени, и поэтому чрезвычайно важно запоминать запросы, на которые система дает хорошие ответы.
Index robot (робот-индексировщик) - служит для сканирования Internet и поддержания базы данных индекса в актуальном состоянии. Эта программа является основным источником информации о состоянии информационных ресурсов сети.
WWW sites - это весь Internet или точнее - информационные ресурсы, просмотр которых обеспечивается программами просмотра.
Рассмотрим теперь назначение и принципу построения каждого из этих компонентов более подробно и определим, в чем отличие данной системы от традиционной ИПС локального типа.
|
|
|
|
|
Дата добавления: 2015-03-29; Просмотров: 1530; Нарушение авторских прав?; Мы поможем в написании вашей работы!