КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Сценарій виконання індивідуального практичного завдання
|
|
|
|
Спершу необхідно створити текстовий файл з даними журналу для імпорту у новоспечений проект Deductor Academic. Після створення файлу Markhyvka.txt (рис. 5.1) та наповнення його даними для аналізу, запускаємо середовище та імпортуємо файл даних за допомогою майстра імпорту даних. 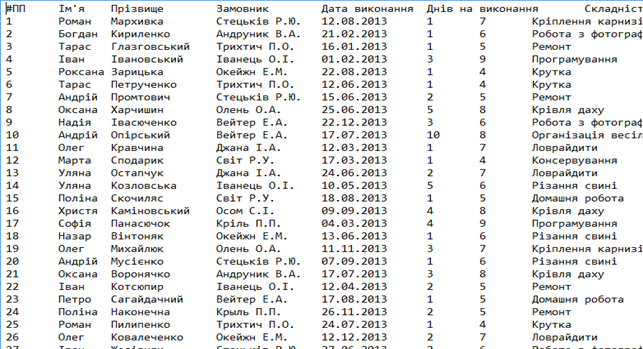
Один із кроків майстра імпорту продемонстрований на рисунку 5.2.
Рис 5.1. Текстовий файл Markhyvka.txt із частиною даних
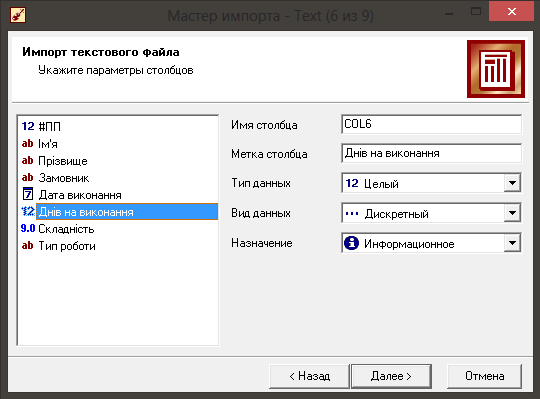 |
Рис. 5.2. Крок визначення даних у майстрі імпорту.
Після виконання процесу імпорту, дані будуть відображені у вигляді 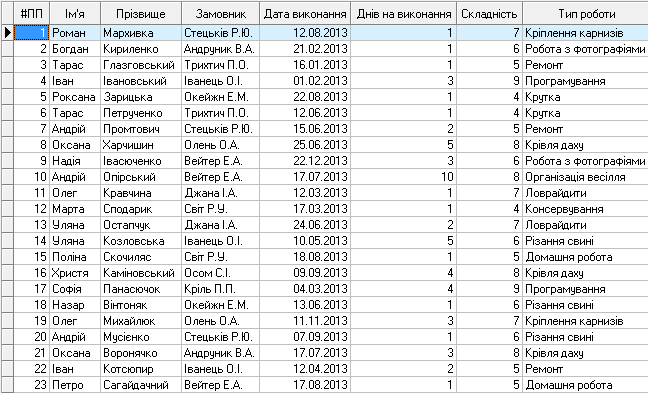
таблиці і показані на рисунку 5.3.
Рис. 5.3. Візуалізація імпортованих файлів у вигляді таблиці.
Далі задаються властивості сформованого проекту. Це продемонстровано на рисунку 5.4.
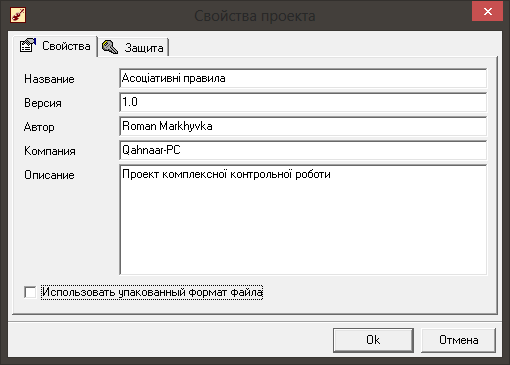 |
Рис. 5.4. Налаштування властивостей проекту.
Далі відбуватиметься обробка даних за допомогою алгоритму APriori, що лежить в основі побудови асоціативних правил в середовищі Deductor. Отже спершу заходимо у майстер обробки та у розділі Data Mining шукаємо
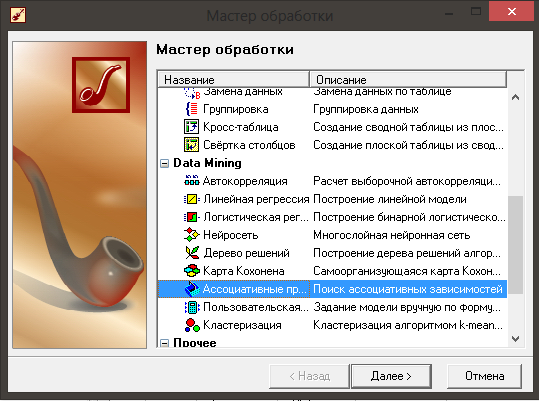 |
підпункт, асоціативні правила. Це показано на рисунку 5.5.
Рис. 5.5. Місцезнаходження пункту вибору для пошуку асоціативних правил.
Далі необхідно налаштувати стовпці для побудови асоціативних правил. Але спершу необхідно визначити, яке правило ми будемо будувати. У моєму випадку правило звучатиме так: якщо замовник подасть запит на виконання певної роботи, то з якою ймовірністю він подасть запит і на виконання іншої роботи. Тому стовпцем транзакцій буде стовпець Замовника, а елементами – Тип роботи. Далі на наступному кроці необхідно задати порогові значення підтримки та достовірності майбутніх правил. У моєму випадку підтримка знаходитиметься у діапазоні значень 5%-45%, а достовірність – 5-90%. Низьке значення підтримки говорить про те, що ми намагатимемося віднайти правила, які не є очевидними на перших погляд (ці налаштування показані на рисунку
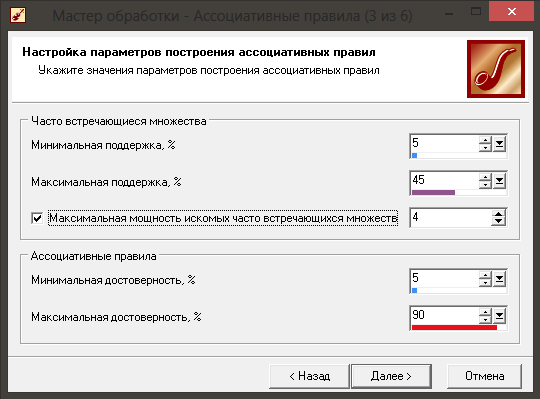 |
5.6.).
Рис. 5.6. Налаштування підтримки та достовірності правил
Далі запускаємо процес обробки даних та пошуку правил. Із рисунку продемонстрованому нижче видно, що було віднайдено 47 множин, із яких виділено 62, що поділяються на 4 основні потужності.
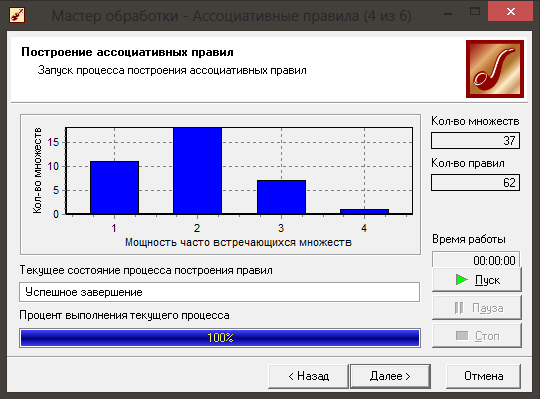 |
Рис. 5.7. Побудова асоціативних правил.
Далі задаємо ім’я та мітку нового вузла сценарію, та заповнюємо
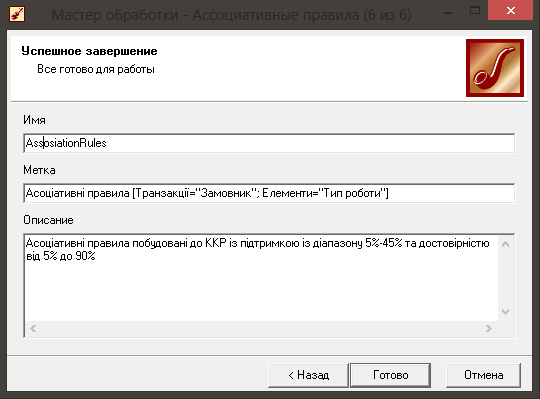 |
невеликий опис даної обробки даних (рис. 5.8.).
Рис. 5.8. Задання кінцевих параметрів процесу обробки даних.
|
|
|
|
|
Дата добавления: 2015-05-24; Просмотров: 417; Нарушение авторских прав?; Мы поможем в написании вашей работы!