КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Основные этапы проектирования БД. Концептуальное, логическое и физическое проектирование БД
|
|
|
|
Информационные системы. Классификация информационных систем. Место баз данных в информационных системах.
База данных представляет собой тщательно разработанное и сконструированное хранилище сведений, которое, в свою очередь, есть часть некоего целого, называемого информационной системой. Информационная система (ИС) предназначена для сбора, хранения и извлечения данных. Она также обеспечивает структурирование данных и управление ими. Законченная информационная система является совокупностью обслуживающего персонала, оборудования, управляющего программного обеспечения, базы (или нескольких баз) данных, прикладных программ и процедур.
Информационные системы, обладая некой общностью в организации, подходах к процессу разработки и эксплуатации, тем не менее, подразделяются на определенные классы по различным признакам.
Информационные системы могут классифицироваться по разным признакам. Рассмотрим наиболее часто используемые способы классификации.
Классификация по масштабу. По масштабу информационные системы подразделяются на следующие группы (рисунок 1.1):
• одиночные:
• групповые:
• корпоративные.
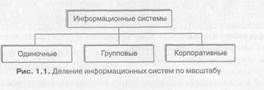
Одиночные информационные системы реализуются, как правило, на автономном персональном компьютере, компьютерная сеть не используется. Такая система может содержать
несколько простых приложений, связанных общим информационным фондом, и рассчитана на работу одного пользователя или группы пользователей, разделяющих по времени одно рабочее место. Подобные приложения создаются с помощью так называемых настольных или локальных систем управления базами данных (СУБД). Среди локальных СУБД наиболее известными являются Clarion. Clipper, FoxPro, Paradox, dBase и Microsoft Access.
Групповые информационные системы ориентированы на коллективное использование информации членами рабочей группы и чаще всего строятся на базе локальной вычислительной сети. При разработке таких приложений используются серверы баз данных, называемые также SQL-серверами, для рабочих групп. Существует довольно большое количество различных SQL-серверов, как коммерческих, так и свободно распространяемых. Среди них наиболее известны такие серверы баз данных, как Oracle, DB2. Microsoft SQL Server. InterBase. Sybase. Inforqix. MySQL.
Корпоративные информационные системы являются развитием систем для рабочих групп, они ориентированы на крупные компании и могут поддерживать территориально разнесенные узлы или сети. В основном они имеют иерархическую структуру из нескольких уровней. Для таких систем характерна архитектура клиент-сервер со специализацией серверов или же многоуровневая архитектура. При разработке таких систем могут использоваться те же серверы баз данных, что и при разработке групповых информационных систем. Однако в крупных информационных системах наибольшее распространение получили серверы Oracle, DB2 и Microsoft SQL Server.
Для групповых и корпоративных систем существенно повышаются требования к надежности функционирования и сохранности данных. Эти свойства обеспечиваются поддержкой целостности данных, ссылок и транзакций в серверах баз данных.
Классификация по сфере применения. По сфере применения информационные системы обычно подразделяются на четыре группы (рисунок 1.2):
• системы оперативной обработки транзакций (OLTP);
• системы оперативной аналитической обработки данных (OLAP);
• информационно-справочные системы;
• офисные информационные системы.
Системы обработки транзакций, в свою очередь, по оперативности обработки данных, разделяются на пакетные информационные системы и оперативные информационные системы. В информационных системах организационного управления преобладает режим оперативной обработки транзакций (OLTP - OnLine Transaction Processing), для отражения актуального состояния предметной области и любой момент времени, а пакетная обработка занимает весьма ограниченную часть.
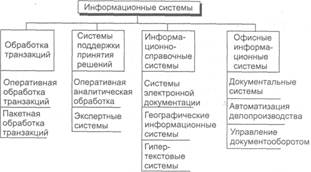
Рисунок 1.2. Деление информационных систем по сфере применения
Типичными примерами OLTP-приложений являются системы складского учета, системы
заказов билетов, банковские системы, выполняющие операции по переводу денег, и т.п.
Основная функция подобных систем заключается в выполнении большого количества коротких
транзакций. Сами транзакции выглядят относительно просто, например, "снять сумму денег со
счета А, добавить эту сумму на счет В".
Для OLTP-систем, в общем случае, характерно следующее:
• во-первых, транзакций очень много;
• во-вторых, выполняются они одновременно - к системе может быть подключено
несколько тысяч одновременно работающих пользователей:
• в-третьих, при возникновении ошибки, транзакция должна целиком откатиться и
вернуть систему к состоянию, которое было до начала транзакции - не должно быть
ситуации, когда деньги сняты со счета А, но не поступили на счет В.
Практически все запросы к базе данных в OLTP-приложениях состоят из команд вставки, ф обновления, удаления. Запросы на выборку в основном предназначены для предоставления пользователям возможности выбора из различных справочников. Большая часть запросов, таким образом, известна заранее еще на этапе проектирования системы. Таким образом, критическим для OLTP-приложений является скорость и надежность выполнения коротких операций обновления данных.
Важными требованиями для OLTP-систем являются:
• высокая производительность обработки транзакций:
• гарантированная доставка информации при удаленном доступе к БД по
телекоммуникациям.
Другим типом приложений являются, так называемые. * системы оперативной аналитической обработки данных (OLAP - On-Line Analitical Processing). Это обобщенный термин, характеризующий принципы построения систем поддержки принятия решений (Decision Support System - DSS), хранилищ данных (Data Warehouse), систем интеллектуального анализа данных (Data Mining). Такие системы предназначены для нахождения зависимостей между данными. Например, можно попытаться определить, как связан объем продаж товаров с характеристиками потенциальных покупателей, для проведения анализа "что если...". OLAP- приложения оперируют с большими массивами данных, уже накопленными в OLTP- приложениях, взятыми их электронных таблиц или из других источников данных. Такие системы характеризуются следующими признаками:
• добавление в систему новых данных происходит относительно редко крупными
блоками (например, раз в квартал загружаются данные по итогам квартальных продаж из OLTP-
приложения).
• данные, добавленные в систему, обычно никогда не удаляются.
• перед загрузкой данные проходят различные процедуры "очистки", связанные с тем,
что в одну систему могут поступать данные из многих источников, имеющих различные
форматы представления для одних и тех же понятий, данные могут быть некорректны,
ошибочны.
• запросы к системе являются нерегламентированными и. как правило, достаточно
сложными. Очень часто новый запрос формулируется аналитиком для уточнения результата,
полученного в результате предыдущего запроса.
• скорость выполнения запросов важна, но не критична.
Данные OLAP-приложений обычно представлены в виде одного или нескольких гиперкубов, измерения которого представляют собой справочные данные, а в ячейках самого гиперкуба хранятся собственно данные. Например, можно построить гиперкуб, измерениями которого являются: время (в кварталах, годах), тип товара и отделения компании, а в ячейках хранятся объемы продаж. Такой гиперкуб будет содержать данных о продажах различных типов товаров по кварталам и подразделениям. Основываясь на этих данных, можно отвечать на вопросы вроде "у какого подразделения самые лучшие объемы продаж в текущем году?", или "каковы тенденции продаж отделений Юго-Западного региона в текущем год) по сравнению с предыдущим годом?"
Обширный класс информационно-справочных систем основан на гипертекстовых документах и мультимедиа. Наибольшее развитие такие информационные системы получили в сети Интернет.
Класс офисных информационных систем нацелен на перевод бумажных документов в электронный вид, автоматизацию делопроизводства и управление документооборотом.
Классификация по способу организации (архитектуре). По способу организации групповые и корпоративные информационные системы подразделяются на следующие классы (рисунок 1.3):
• системы на основе архитектуры файл-сервер;
• системы на основе архитектуры клиент-сервер;
• системы на основе многоуровневой архитектуры;
системы на основе Интернет/интранет-технологий.
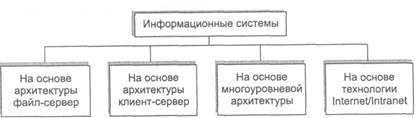
Рисунок 1.3. Деление информационных систем по способу организации
Имеется 2 подхода к проектированию БД:
1.Классический, основанный на нормализации.
Создается одно или несколько базовых отношений. Они анализируются для определенного уровня нормализации. К ним применяется декомпозиция для приведения в нормализующее состояние.
2.Семантическое проектирование БД, основанное на подробном анализе предметной области.
В реальной жизни эти подходы применяются совместно.
Создание концептуальной модели можно представить в виде нескольких этапов:
· Определение типов сущностей
· Определение типов связей
· Определение атрибутов и связывание их с типами сущностей и связей
· Определение доменов атрибутов
· Определение атрибутов, являющихся потенциальными и первичными ключами
· Создание диаграммы «сущность - связь»
· Обсуждение концептуальной модели с конечными пользователями
Логическое проектирование – процесс конструктирования общей информационной модели предприятия независимо от особенностей СУБД и других физических условий.
Логическая модель учитывает выбранную модель данных. Результатом этого этапа должна стать корректная, полная и точная модель.
Логическое проектирование включает в себя следующие этапы:
- Определение набора отношений исходя из концептуальной модели БД
- Проверка модели с помощью правил нормализации
- Проверка модели в отношении модели пользователей
- Создание полной атрибутивной диаграммы в рамках технологии IEDFIX
- Определение требующейся поддержки целостности
- Обсуждение логической модели с конечными пользователями
Физическое проектирование:
- Перенос логической модели данных в среду целевой СУБД (Разработка таблиц БД и установка определенной целостности. Определяются имена таблиц, имена атрибутов, определение первичных ключей, выбор доменов. Все ограничения, которые отмечены в логической модели должны быть по возможности учтены при построении таблиц.)
- Проектирование физического представления БД
- Разработка механизмов защиты
- Организация мониторинга и настройка системы
- Методология IDEF1X проектирования БД.
IDEF1X-диаграмма строится из трех основных блоков – сущностей, атрибутов, связей.
Сущность – множество индивидуальных объектов-экземпляров, причем все объекты различны.
Атрибут - свойство объекта, характеризующее его экземпляр.
Связь - функциональная зависимость между сущностями.
Определение сущностей.
1. Извлечение информации из интервью и выделение сущностей.
Каждая сущность должна обладать уникальным идентификатором. Каждый экземпляр сущности должен однозначно идентифицироваться и отличаться от всех других экземпляров данного типа сущности. Каждая сущность должна обладать свойствами:
а) иметь уникальное имя с одной и той же интерпретацией, причем одна и та же интерпретация не может применяться к различным именам, если только они не являются псевдонимами;
б) обладать одним или несколькими атрибутами, которые либо принадлежат сущности, либо наследуются через связь;
в) обладать одним или несколькими атрибутами, которые однозначно идентифицируют каждый экземпляр сущности;
г) обладать любым количеством связей с другими сущностями.
На диаграмме сущность изображается прямоугольником с указанием ее имени и номера слева над прямоугольником(например «Группа/1») и атрибутов.
2. Идентификация атрибутов.
Атрибуты сущности разделены на атрибуты составляющие первичный ключ и прочие (не входящие в первичный ключ). Каждая сущность должна обладать хотя бы одним возможным ключом.
Возможный ключ – один или несколько атрибутов, чьи значения однозначно определяют каждый экземпляр сущности. При существовании нескольких возможных ключей, один обозначается как первичный ключ - атрибут или набор атрибутов, уникально идентифицирующий экземпляр сущности, остальные как альтернативные – атрибут или группа атрибутов, не совпадающих с первичным ключом и уникально идентифицирующая экземпляр сущности.
Все атрибуты ключа должны удовлетворять свойству однозначной идентификации (правило наименьшего ключа). При определении должен ли наследуемый атрибут быть частью ключа, надо выяснить необходим ли этот атрибут для однозначной идентификации.
Правило полной функциональной зависимости – первичный ключ состоит из множества атрибутов, все неключевые атрибуты должны функционально зависеть от всего первичного ключа.
Правило нетранзитивной зависимости – каждый неключевой атрибут должен функционально зависеть только от ключевых атрибутов.
Ни одна из частей ключа не должна иметь значение NULL.
Если несколько наборов атрибутов могут уникально идентифицировать сущность, то выбор одного из них осуществляется разработчиком базы данных на основании анализа предметной области.
Правила выбора первичного ключа из списка предполагаемых ключей таковы:
а) он должен уникальным образом идентифицировать экземпляр сущности;
б) он не может принимать значение NULL;
в) он не должен изменяться со временем, ибо при изменении ключа меняется и экземпляр сущности;
г) он должен быть как можно более коротким для индексирования данных.
Независимая сущность - каждый экземпляр сущности может быть однозначно идентифицирован без определения его отношений с другими сущностями.
Зависимая сущность - и однозначная идентификация экземпляра сущности зависит от его отношения к другой сущности. На диаграмме она изображается прямоугольником с закругленными углами.
Экземпляры независимой сущности могут быть уникально идентифицированы без определения ее связей с другими сущностями. Экземпляры зависимой сущности, наоборот, не могут быть идентифицированы без определения ее связей с другими сущностями.
Определение зависимостей между сущностями.
Связь – ассоциация между сущностями, при которой, как правило, каждый экземпляр одной сущности, называемой родительской сущностью, ассоциирован с произвольным (в том числе нулевым) количеством экземпляров второй сущности, называемой сущностью – потомком, а каждый экземпляр сущности – потомка ассоциирован в точности с одним экземпляром сущности – родителя. Таким образом, экземпляр сущности – потомка может существовать только при существовании сущности – родителя.
Связь изображается линией между сущностями, и ей дается уникальное для данной пары сущностей имя в виде оборота глагола, например, «состоит», «является» и т.д. Имя связи всегда формируется с точки зрения родителя.
Связь – это понятие логического уровня, которому соответствует внешний ключ на физическом уровне.
Связь идентифицирующая -если экземпляр дочерней сущности идентифицируется через ее связь с родительской сущностью. Атрибуты, составляющие первичный ключ родительской сущности, при этом входят в первичный ключ дочерней сущности. Дочерняя сущность при этом является всегда зависимой. Изображается сплошной линией и заканчивается точкой со стороны дочерней сущности.
Неидентифицирующая связь - экземпляр дочерней сущности идентифицируется иначе, чем через связь с родительской сущностью. Атрибуты, составляющие первичный ключ родительской сущности, при этом входят в состав неключевых атрибутов дочерней сущности. Такая связь изображается пунктирной линией с точкой у дочерней сущности.
Связи дополняются указанием мощности, определяющей, какое количество экземпляров сущности – потомка может существовать для каждого экземпляра сущности – родителя. Если мощность не задана, то предполагается нуль, один и более экземпляров.
Связь категоризации.
Некоторые сущности определяют целую категорию объектов одного типа.
В IDEF1X диаграммах создается сущность для определения категории и для каждого элемента категории, а затем вводится для них связь категоризации.
Супертип – родительская сущность категоризации. Подтип – дочернии.
СОТРУДНИК может содержать данные о преподавателях и инженерах.Общая часть атрибутов (табельный номер, ФИО, адрес, телефон, дата рождения), включая первичный ключ, помещается в сущность сотрудник, а различная часть помещается в сущность-подтип.
В сущности- супертипе вводится атрибут-дискриминатор (Тип_служащего), позволяющий различать конкретные экземпляры сущности-подтипа.В зависимости от того, все ли возможные сущности-подтипы включены в модель, категорийная связь бывает полной или неполной. Если супертип содержит данные о прочих служащих, то связь полной категоризации.
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 1718; Нарушение авторских прав?; Мы поможем в написании вашей работы!