КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Объектно–ориентированная модель 1 страница
|
|
|
|
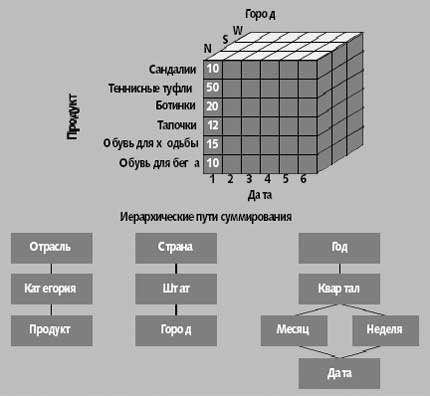
Многомерная модель данных
Основные понятия:
агрегируемость
историчность
прогнозируемость данных
Достоинства: повышение наглядности и информативности; удобство и эффективность аналитической обработки больших объемов информации
Недостатки: громоздкость (что делает ее не пригодной для организации БД небольших объемов)
Основные понятия:
Измерение – множество однотипных данных, помещенных на одну из граней гиперкуба
Ячейка – поле, значение которого однозначно определяется фиксированным набором измерений
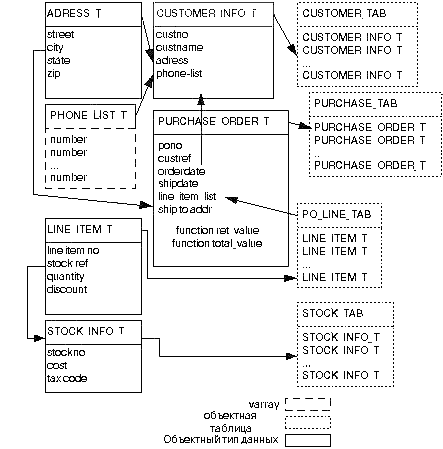
Моделью данных, привлекающей нарастающее внимание с конца 80-х гг., является объектная, или объектно–ориентированная модель. Основными понятиями, с которыми оперирует эта модель, являются следующие:
объекты, обладающие внутренней структурой и однозначно идентифицируемые уникальным внутрисистемным ключом;
классы, являющиеся по сути типами объектов;
операции над объектами одного или разных типов, называемые «методами»;
инкапсуляция структурного и функционального описания объектов, позволяющая разделять внутреннее и внешнее описания;
наследуемость внешних свойств объектов на основе соотношения «класс-подкласс».
Данная модель связана с развитием Интернет–технологий. Эта модель характеризуется следующими свойствами: базовыми примитивами являются объекты и литералы; каждый объект имеет уникальный идентификатор, а литерал его не имеет; объекты и литералы различаются по типу; объект на который можно установить ссылку называется экземпляром и хранит определенный набор данных; состояние объекта определяется набором значений; поведение объекта определяется набором операций, которые могут быть выполнены над ними. Также к свойствам можно отнести инкапсуляция, полиморфизм, наследование.
База данных в объектно–ориентированной модели представляет хранилище объектов, которые можно использовать совместно различными пользователями и приложениями.
Достоинства:
возможность для пользователя системы определять свои сколь угодно сложные типы данных (используя имеющийся синтаксис и свойства наследуемости и инкапсуляции);
наличие наследуемости свойств объектов;
повторное использование программного описания типов объектов при обращении к другим типам, на них ссылающимся.
Недостатки:
эта модель не исследована столь тщательно математически, как реляционная;
отсутствие общеупотребимых стандартов, позволяющих связывать конкретные объектно–ориентированные системы с другими системами работы с данными;
очень остро стоит проблема идентификации объекта (Существует несколько подходов к идентификации объектов в данной модели. Самый простой – выделение ему уникального номера, который никогда не может повторяться, даже если объект с определенным номером был удален.);
невозможно перенести объекты в другую базу данных (Решением этой проблемы предложено с использованием составного идентификатора (1 часть – имя БД, 2 часть – имя объекта: в СУБД Versant).
Инфологическое моделирование данных на основе модели «Cущность–связь». ER–диаграммы
| На сегодняшний день не существует единого общепринятого стандарта для модели «Сущность–связь», но существует набор общих конструкций, которые лежат в основе большинства вариантов этой модели. На использовании разновидностей ER-моделиосновано большинство современных подходов к проектированию баз данных (главным образом, реляционных). Модель была предложена Ченом. Моделирование предметной области базируется на использовании графических диаграмм, включающих небольшое число разнородных компонентов. В связи с наглядностью представления концептуальных схем баз данных ER-модели получили широкое распространение в системах CASE, поддерживающих автоматизированное проектирование реляционных баз данных. Среди множества разновидностей ER-моделейодна из наиболее развитых применяется в системе CASE фирмы ORACLE. Основными понятиями ER-моделиявляются сущность, связь и атрибут. Сущность - это реальный или представляемый объект, информация о котором должна сохраняться и быть доступна. В диаграммах ER-модели сущность представляется в виде прямоугольника, содержащего имя сущности. При этом имя сущности - это имя типа, а не некоторого конкретного экземпляра этого типа. Для большей выразительности и лучшего понимания имя сущности может сопровождаться примерами конкретных объектов этого типа. Связь - это графически изображаемая ассоциация, устанавливаемая между двумя сущностями. Эта ассоциация всегда является бинарной и может существовать между двумя разными сущностями или между сущностью и ей же самой (рекурсивная связь). В любой связи выделяются два конца (в соответствии с существующей парой связываемых сущностей), на каждом из которых указывается имя конца связи, степень конца связи (сколько экземпляров данной сущности связывается), обязательность связи (т.е. любой ли экземпляр данной сущности должен участвовать в данной связи). Класс сущностей – это совокупность сущностей, которая описывается структурой, либо форматом сущностей, составляющих этот класс. Экземпляр сущности – представляет собой конкретную сущность. Атрибуты сущности – это свойства сущности, которые описывают характеристики сущности. В данной модели предполагается, что все экземпляры некоторого класса сущностей имеют одинаковые атрибуты (поля объекта). Композитные атрибуты – адрес, страна, район и т.д. Многозначный атрибут – студент имеет базовое образование. Композитный атрибут может быт многозначным. Идентификаторы – это атрибуты, с помощью которых экземпляры именуются или идентифицируются. Идентификатором сущности может быть один или несколько атрибутов. Идентификаторы могут быть уникальными или не уникальными. Если идентификатор указывает на один экземпляр сущности, то его значение называется уникальным. Если идентификатор не является уникальным, то его значение определяется некоторым множеством экземпляров сущности. Связи – это взаимоотношения сущностей выраженная связями. Модель «Сущность-Связь» включает в себя классы связей и экземпляры связей. Классы связей – это взаимоотношения между классами сущностей. Класс связей Студент имеет базовое образование. Экземпляры связей – это взаимоотношения между экземплярами сущностей. Экземпляр связи Сидоров имеет общее среднее образование. Типы связей: 1). Связь один к одному (1:1)– одиночный экземпляр сущности одного типа связан с одиночным экземпляром сущности другого типа. В каждый момент времени каждому представителю (экземпляру) сущности А соответствует 1 или 0 представителей сущности В: Студент может не "заработать" стипендию, получить обычную или одну из повышенных стипендий. |

2). Связь один ко многим (1:М) – один экземпляр сущности связан со многими экземплярами другой сущности.
Одному представителю сущности А соответствуют 0, 1 или несколько представителей сущности В.
Квартира может пустовать, в ней может жить один или несколько жильцов.

3). Связь многие ко многим (М:N) – несколько экземпляров одной сущности связаны с несколькими экземплярами другой сущности.
Модель «Сущность-Связь» или ER-диаграммы включают в себя изображения сущностей в виде прямоугольников (или прямоугольников с закругленными углами), а связей в виде ромбиков (или ромбиков с закругленными углами), которые соединяются с сущностями с помощью линий, дуг (знак «/» на дугах (линиях) – означает обязательную связь между объектами).
На ER-диаграммах атрибуты обозначаются эллипсами. Если атрибутов у сущности много, то чтобы не загружать ER-диаграмму, атрибуты помещают в прямоугольник, в котором идет перечисление всех атрибутов сущности.
Связи между сущностями одного и того же класса называются рекурсивными.
Слабые сущности определяют такие сущности, которые могут существовать в базе данных в том случае, если в ней присутствуют сущности некоторого другого типа. Сущности не являющиеся слабой являются сильной. Слабые сущности изображаются в виде прямоугольника с закругленными углами.
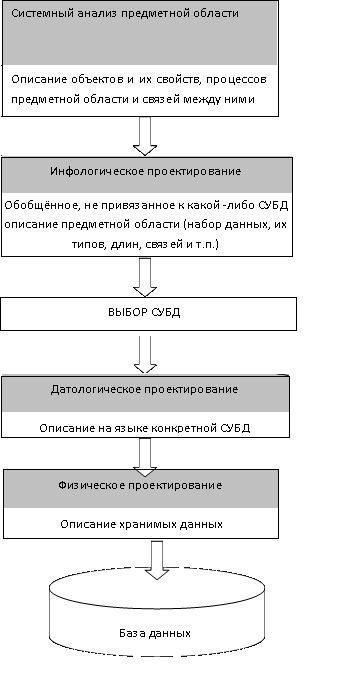
Этапы проектирования баз данных
Законы проектирования баз данных: 1.Системный анализ предметной области 2.Инфологическое проектирование 3.Выбор СУБД 4.Датологическое проектирование 5.Физическое проектирование
I Системный анализ предметной области
На первом этапе проектирования баз данных рассматриваются цели и задачи с помощью которой они будут решатся. Анализируются информационные потребности будущих пользователей баз данных. Рассматриваются формы входных и выходных потоков, которые будут составлять основу баз данных. Затем уточняются алгоритмы и процедуры обработки данных хранимой в базе данных. Формируются требования, которым должна удовлетворять проектируемая база данных и определяется примерный список объектов предметной области, свойства которых будут использоваться при разработке базы данных.
II Инфологическое проектирование
На второй стадии проектирования выполняется моделирование данных. Моделирование данных– это процесс создания логической структуры данных. Существует два подхода к моделированию данных: Модель «Сущность-связь» Семантическая объектная модель Эти модели представляют собой языки для описания структуры данных и их связей в представлениях пользователей. Моделирование данных, подобно блок-схемам, отражают логику программы. Модель «Сущность-Связь» Сущность – это объект, идентифицируемый в рабочей среде пользователя за которым пользователь хотел бы наблюдать. Класс сущностей – это совокупность сущностей, которая описывается структурой, либо форматом сущностей, составляющих этот класс. Экземпляр сущности – представляет собой конкретную сущность. Атрибуты сущности – это свойства сущности, которые описывают характеристики сущности. Идентификаторы – это атрибуты, с помощью которых экземпляры именуются или идентифицируются. Если идентификатор указывает на один экземпляр сущности, то его значение называется уникальным. Если идентификатор не является уникальным, то его значение определяется некоторым множеством экземпляров сущности. Связи – это взаимоотношения сущностей выраженная связями. Модель «Сущность-Связь» включает в себя классы связей и экземпляры связей. Классы связей – это взаимоотношения между классами сущностей. Экземпляры связей – это взаимоотношения между экземплярами сущностей. Типы связей: Связь один к одному (1:1) – одиночный экземпляр сущности одного типа связан с одиночным экземпляром сущности другого типа. Связь один ко многим (1:М) – один экземпляр сущности связан со многими экземплярами другой сущности. Связь многие ко многим (М:N)– несколько экземпляров одной сущности связаны с несколькими экземплярами другой сущности. Модель «Сущность-Связь» или ER-диаграммы включают в себя изображения сущностей в виде прямоугольников (или прямоугольников с закругленными углами), а связей в виде ромбиков (или ромбиков с закругленными углами). На ER-диаграммах атрибуты обозначаются эллипсами. Если атрибутов у сущности много, то чтобы не загружать ER-диаграмму, атрибуты помещают в прямоугольник, в котором идет перечисление всех атрибутов сущности. Семантическая объектная модель Данная модель используется для моделирования данных на этапе инфологического моделирования. Семантический или смысловой объект– это объект, который в определенной степени моделирует смысл пользовательских данных. Они более точно моделируют представления пользователей. У семантических объектов есть имя, а также есть имя и у класса, отличающего его от других объектов и классов. Семантическая модель имеет набор атрибутов. Атрибуты описывают те характеристики объекта, которые необходимы для удовлетворения информационных потребностей в аспекте решаемых задач. Для моделирования данных в семантических объектах используется объектные диаграммы. Такие диаграммы используются разработчиками баз данных для описания и визуального представления структуры объектов. Объекты в них отражаются в вертикально ориентированных прямоугольниках. Имя объекта указывается внутри прямоугольника в верхней его части, а затем следует список атрибутов по порядку их значимости для этого объекта. Для описания типов семантических объектов используются следующие понятия: Однозначный атрибут- атрибуты с максимальным кардинальным числом равным 1. Многозначный атрибут– атрибут, имеющий максимальное кардинальное число большее 1. Необъектный атрибут– это простой или групповой атрибут. Типы объектов: простые, композитные, составные, гибридные, ассоциативные, родитель.
III Выбор СУБД
При выборе СУБД руководствуются следующими соображениями: аппаратное обеспечение, на котором в дальнейшем будет работать проектируемая база данных; системное программное обеспечение, с которым будет в последствии работать проектируемая база данных и соответствующее ей приложения; методология и подходы, к программированию реализованные в той или иной СУБД; модель данных, которая встроена в конкретную СУБД; Выбор СУБД полностью определяется на II этапе построения базы данных, т. к. оно зависит от той модели данных, которая встроена в выбранную СУБД.
IV Датологическое проектирование
После того, как выбор СУБД завершён, необходимо приступить к проектированию датологической модели базы данных. При формировании датологической схемы, каждая из определённых в концептуальной схеме сущностей отображается в таблицу, которая является одним отношением. При этом следует учитывать ограничения на размер таблиц, которые накладывает конкретная СУБД.
V Физическое проектирование
На этом этапе необходимо на конкретной СУБД, которую выбрали ранее, реализовать базу данных по той информации, которую собрали, обработали и подготовили (на предыдущих этапах проектирования базы данных). Описываются модули, их назначение, а также структура модулей.
Этапы и содержание жизненного цикла БД:
I. проектирование
 1). Анализ системной предметной области и запросов будущих пользователей в БД 2). Интеграция пользовательских представлений с целью построения инфологической модели предметных областей. 3). Выбор средства реализации, т.е. конкретных СУБД для разработки БД 4). Датологическое проектирование 5). Физическое проектирование
II. создание
1). Генерация БД 2). Подготовка среды хранения данных 3). Ввод и контроль данных 4). Загрузка и корректировка БД
III.эксплуатация
1). Реорганизация БД реструктуризация БД реформация БД 2). Организация доступа к БД поиск и обновление данных вывод отчетов разграничение доступа при необходимости инициирование и завершение работы с СУБД 3). Контроль состояния БД сбор и анализ статистики использования БД контроль целостности БД копирование и восстановление БД (по необходимости)
Этапы проектирования базы данных: 1). Анализ системной предметной области и запросов будущих пользователей в БД 2). Интеграция пользовательских представлений с целью построения инфологической модели предметных областей. 3). Выбор средства реализации, т.е. конкретных СУБД для разработки БД 4). Датологическое проектирование 5). Физическое проектирование
II. создание
1). Генерация БД 2). Подготовка среды хранения данных 3). Ввод и контроль данных 4). Загрузка и корректировка БД
III.эксплуатация
1). Реорганизация БД реструктуризация БД реформация БД 2). Организация доступа к БД поиск и обновление данных вывод отчетов разграничение доступа при необходимости инициирование и завершение работы с СУБД 3). Контроль состояния БД сбор и анализ статистики использования БД контроль целостности БД копирование и восстановление БД (по необходимости)
Этапы проектирования базы данных:
|
На этапе проектирования базы данных разработчик должен определить, из каких таблиц должна состоять база данных, какие данные нужно поместить в каждую таблицу и как связать таблицы.
Следовательно, в результате проектирования определяются логическая структура базы данных, т. е. состав реляционных таблиц, их структура и межтабличные связи.
Для создания базы данных необходимо располагать описанием выбранной предметной области, охватывающим реальные объекты и процессы, а также определить все необходимые источники информации для удовлетворения предполагаемых запросов пользователей и потребности в обработке данных. На основе такого описания определяются состав и структура данных предметной области, которые должны находиться в базе и обеспечивать выполнение необходимых запросов и задач пользователей. Структура данных предметной области может отображаться информационно-логической моделью, на основе которой легко создается реляционная база данных.
Этапы проектирования и создания базы данных:
- построение информационно-логической модели данных предметной области;
- определение логической структуры реляционной базы данных;
- конструирование таблиц базы данных;
- создание схемы данных;
- ввод данных в таблицы (создание записей);
- разработка необходимых форм, запросов, макросов, модулей, отчетов;
- разработка пользовательского интерфейса.
В процессе разработки модели данных необходимо выделить информационные объекты, соответствующие требованиям нормализации данных, и определить связи между ними. Полученная модель позволит создать реляционную базу данных без дублирования, в которой обеспечиваются однократный ввод данных при первоначальной загрузке и корректировках, а также целостность данных при внесении изменений.
При разработке модели данных используются два подхода.
Сначала определяются основные задачи, для решения которых строится база, выявляются потребности задач в данных и соответственно определяются состав и структура информационных объектов.
Сразу устанавливаются типовые объекты предметной области.
Наиболее рационально сочетание этих подходов, так как на начальном этапе, как правило, нет исчерпывающих сведений обо всех задачах. Использование такой технологии тем более оправдано, что гибкие средства создания реляционной базы данных допускают на любом этапе разработки внесение изменений и модифицирование ее структуры без ущерба для введенных ранее данных.
Процесс выделения информационных объектов предметной области, отвечающих требованиям нормализации, может производиться на основе интуитивного или формального подхода. Теоретические основы формального подхода разработаны известным американским ученым Дж. Мартином и изложены в его монографиях по организации баз данных.
При интуитивном подходе легко выявить информационные объекты, соответствующие реальным объектам, однако получаемая при этом информационно-логическая модель, как правило, требует дальнейших преобразований, в частности преобразования много-многозначных связей между объектами. При таком подходе в случае отсутствия достаточного опыта возможны существенные ошибки. Последующая проверка выполнения требований нормализации обычно показывает необходимость уточнения информационных объектов.
Рассмотрим формальные правила выделения информационных объектов:
- на основе описания предметной области выявить документы и их атрибуты, подлежащие хранению в базе данных;
- определить функциональные зависимости между атрибутами;
- выбрать все зависимые атрибуты и указать для каждого все его ключевые атрибуты, т. е. атрибуты, от которых он зависит;
- сгруппировать атрибуты, одинаково зависимые от ключевых атрибутов. (Полученные группы зависимых атрибутов вместе с их ключевыми атрибутами образуют информационные объекты.)
При определении логической структуры реляционной базы данных на основе модели каждый информационный объект адекватно отображается реляционной таблицей, а связи между этими таблицами соответствуют связям между информационными объектами.
В процессе создания БД сначала конструируются таблицы, соответствующие информационным объектам построенной модели данных. Далее может создаваться схема данных, в которой фиксируются существующие логические связи между таблицами, соответствующие связям информационных объектов. В схеме данных могут быть заданы параметры поддержания целостности базы данных, если модель была разработана в соответствии с требованиями нормализации. Целостность данных означает, что в БД установлены и корректно поддерживаются взаимосвязи между записями разных таблиц при загрузке, добавлении и удалении записей в связанных таблицах, а также при изменении значений ключевых полей.
После формирования схемы данных осуществляется ввод непротиворечивых данных из документов предметной области.
На основе созданной базы формируются необходимые запросы, формы, макросы, модули, отчеты, производящие требуемую обработку данных и их представление.
С помощью встроенных средств и инструментов базы данных создается пользовательский интерфейс, позволяющий управлять процессами ввода, хранения, обработки, обновления и представления информации
Инфологическое моделирование данных на основе семантической объектной модели. Семантические объектные диаграммы
Семантическая объектная модельиспользуется для моделирования данных. Команда разработчиков опрашивает пользователей, анализирует предоставленные ими отчеты, формы и запросы и на их основе строит пользовательскую модель данных. Эта модель данных в дальнейшем воплощается в структуре базы данных. В случае использования семантической модели объектной модели конструируемая модель будет содержать семантические объекты и связанные с ними конструкции. Семантическая объектная модельбыла впервые представлена в 1988г. и опубликована Коддом, Хаммером и Мак-Леодом. Слово семантический означает смысловой, а семантический объект - это объект, который в определенной степени моделирует смысл пользовательских данных. Семантические объекты моделируют восприятие пользователя более точно, чем модель «сущность-связь». Семантический объект - это представление некоторой вещи, идентифицируемой в рабочей среде пользователя. Семантический объект – это именованная совокупность атрибутов, которая в достаточной степени описывает отдельный феномен. Подобно сущностям, семантические объекты группируются в классы. У объектного класса есть имя, которое отличает его от других классов и соответствует именам вещей, представляемых этим классом. Подобно сущностям объект имеет набор атрибутов. Каждый атрибут описывает одну из характеристик представляемого феномена. Объекты представляют отдельные феномены, то есть в восприятии пользователей они являются чем–то независимым и самостоятельным, что требует учета. Феномены – это сущности, информация о которых необходима. Семантические объекты имеют атрибуты, описывающие их характеристики. Есть три типа атрибутов. Простые атрибуты состоят из одного элемента. Групповые атрибуты являют собой совокупности атрибутов. Семантические объектные атрибуты – это атрибуты, которые устанавливают связь между двумя семантическими объектами. Чтобы лучше попять эти определения взгляните на рисунке, который представляет пример семантической объектной диаграммы и просто объектной диаграммы. Такие диаграммы используются командами разработчиков для описания визуального представления структуры объектов. Объекты изображаются в вертикально ориентированных прямоугольниках. Имя объекта указывается вверху, а атрибуты записываются по порядку после имени объекта.
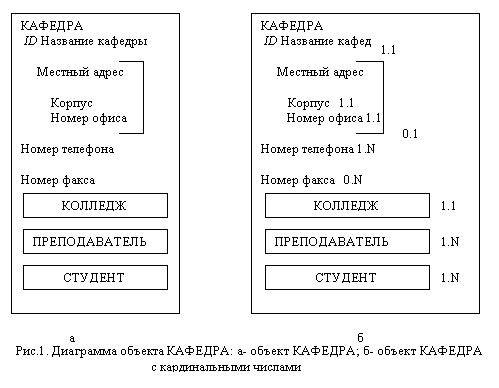 Объект КАФЕДРА содержит пример каждого из трех типов атрибутов. Атрибуты Название кафедры, Номер телефона и Номер факса являются простыми: каждый из них представляет один элемент данных. Местный адрес – групповой атрибут, состоящий из простых атрибутов Корпус и Номер офиса. Наконец, КОЛЛЕДЖ, ПРЕПОДАВАТЕЛЬ и СТУДЕНТ – это семантические объектные атрибуты, то есть эти объекты связаны с объектом КАФЕДРА и логически содержатся в нем. Смысл этих объектных атрибутов, или объектных ссылок состоит в том, что когда пользователь думает об определенной кафедре, он имеет в виду не только название кафедры, локальный адрес, номер телефона и помер факса этой кафедры, но также колледж, в котором она находится, профессоров, преподающих в ней, и студентов, занимающихся па ней. Постольку КОЛЛЕДЖ, ПРЕПОДАВАТЕЛЬ и СТУДЕНТ также являются объектами, полная модель данных содержит диаграммы и для них. Объект КОЛЛЕДЖ несет в себе атрибуты колледжа, объект ПРЕПОДАВАТЕЛЬ – атрибуты членов профессорско-преподавательского состава, а объект СТУДЕНТ содержит атрибуты студентов. Кардинальное число атрибута Каждый атрибут семантического объекта имеет минимальное и максимальное кардинальные числа. Минимальное кардинальное число показывает количество экземпляров атрибута, которые должны существовать, чтобы объект был допустимым. Обычно это число равно 0 или 1. Если оно равно 0, атрибут не обязан иметь значение, а если 1, то атрибут обязан иметь значение. Максимальное кардинальное число показывает максимальное количество экземпляров атрибута, которое может иметь объект. Обычно оно равно 1 или N. Если оно равно 1, атрибут может иметь не более одного экземпляра, если оно равно N, атрибут может иметь много экземпляров, и предельное количество не задано. Кардинальность изображается в виде нижнего индекса атрибута в формате N.М, где N – минимальное кардинальное число, а М – максимальное, На рис 1 кардинальность атрибута Номер телефона равна 1.N, то есть кафедра, обязана иметь минимум один номер телефона, но в принципе номеров у нее может быть много. Кардинальность 0.1 у атрибута Номер факса означает, что кафедра может не иметь факса, а может иметь, но только один. В семантической объектной модели нет однонаправленных связей между объектами. Если один объект содержит в себе другой объект, то другой объект должен содержать первый объект. Такие объектные атрибуты называются парными. С помощью таких атрибутов отображаются связи между объектами в данной модели. Домен атрибута – это описание множества его значений. Домен простого атрибута состоит из физического и семантического описания. Физическое описание показывает тип данных (число или строка), длину данных и др. ограничения. Семантическое описание указывает функцию, или назначение данного атрибута; оно отличает этот атрибут от других атрибутов с тем же физическим описанием. Для описания типов семантических объектов используют следующие понятия: однозначный атрибут – атрибут с максимальным кардинальным числом равны 1; многозначный атрибут – атрибут с максимальным кардинальным число больше 1; необъектный атрибут – простой или групповой атрибут. Типы объектов: Простые – семантический объект, имеющий только однозначные простые или групповые атрибуты; Композитные – семантические объекты, содержащие 1 или несколько многозначных атрибутов, простых или групповых, но не имеющих объектных атрибутов; Составные – имеют минимум один объектный атрибут; Гибридные – комбинация композитных и составных объектов; Ассоциативные – каждый такой объект связывает 2 или более объектов и описывает характер связи, а также содержит данные относящиеся к этой связи; Родитель – семантический объект, который порождает др. семантический объект.
Объект КАФЕДРА содержит пример каждого из трех типов атрибутов. Атрибуты Название кафедры, Номер телефона и Номер факса являются простыми: каждый из них представляет один элемент данных. Местный адрес – групповой атрибут, состоящий из простых атрибутов Корпус и Номер офиса. Наконец, КОЛЛЕДЖ, ПРЕПОДАВАТЕЛЬ и СТУДЕНТ – это семантические объектные атрибуты, то есть эти объекты связаны с объектом КАФЕДРА и логически содержатся в нем. Смысл этих объектных атрибутов, или объектных ссылок состоит в том, что когда пользователь думает об определенной кафедре, он имеет в виду не только название кафедры, локальный адрес, номер телефона и помер факса этой кафедры, но также колледж, в котором она находится, профессоров, преподающих в ней, и студентов, занимающихся па ней. Постольку КОЛЛЕДЖ, ПРЕПОДАВАТЕЛЬ и СТУДЕНТ также являются объектами, полная модель данных содержит диаграммы и для них. Объект КОЛЛЕДЖ несет в себе атрибуты колледжа, объект ПРЕПОДАВАТЕЛЬ – атрибуты членов профессорско-преподавательского состава, а объект СТУДЕНТ содержит атрибуты студентов. Кардинальное число атрибута Каждый атрибут семантического объекта имеет минимальное и максимальное кардинальные числа. Минимальное кардинальное число показывает количество экземпляров атрибута, которые должны существовать, чтобы объект был допустимым. Обычно это число равно 0 или 1. Если оно равно 0, атрибут не обязан иметь значение, а если 1, то атрибут обязан иметь значение. Максимальное кардинальное число показывает максимальное количество экземпляров атрибута, которое может иметь объект. Обычно оно равно 1 или N. Если оно равно 1, атрибут может иметь не более одного экземпляра, если оно равно N, атрибут может иметь много экземпляров, и предельное количество не задано. Кардинальность изображается в виде нижнего индекса атрибута в формате N.М, где N – минимальное кардинальное число, а М – максимальное, На рис 1 кардинальность атрибута Номер телефона равна 1.N, то есть кафедра, обязана иметь минимум один номер телефона, но в принципе номеров у нее может быть много. Кардинальность 0.1 у атрибута Номер факса означает, что кафедра может не иметь факса, а может иметь, но только один. В семантической объектной модели нет однонаправленных связей между объектами. Если один объект содержит в себе другой объект, то другой объект должен содержать первый объект. Такие объектные атрибуты называются парными. С помощью таких атрибутов отображаются связи между объектами в данной модели. Домен атрибута – это описание множества его значений. Домен простого атрибута состоит из физического и семантического описания. Физическое описание показывает тип данных (число или строка), длину данных и др. ограничения. Семантическое описание указывает функцию, или назначение данного атрибута; оно отличает этот атрибут от других атрибутов с тем же физическим описанием. Для описания типов семантических объектов используют следующие понятия: однозначный атрибут – атрибут с максимальным кардинальным числом равны 1; многозначный атрибут – атрибут с максимальным кардинальным число больше 1; необъектный атрибут – простой или групповой атрибут. Типы объектов: Простые – семантический объект, имеющий только однозначные простые или групповые атрибуты; Композитные – семантические объекты, содержащие 1 или несколько многозначных атрибутов, простых или групповых, но не имеющих объектных атрибутов; Составные – имеют минимум один объектный атрибут; Гибридные – комбинация композитных и составных объектов; Ассоциативные – каждый такой объект связывает 2 или более объектов и описывает характер связи, а также содержит данные относящиеся к этой связи; Родитель – семантический объект, который порождает др. семантический объект.
|
Проектирование реляционных баз данных. Метод нормальных форм
Процесс проектирования представляет собой процесс нормализации схем отношений, причем каждая следующая нормальная формаобладает свойствами лучшими, чем предыдущая. Каждой нормальной форме соответствует некоторый определенный набор ограничений, и отношение находится в некоторой нормальной форме, если удовлетворяет свойственному ей набору ограничений. Примером набора ограничений является ограничение первой нормальной формы- значения всех атрибутов отношения атомарны. Поскольку требование первой нормальной формы является базовым требованием классической реляционной модели данных, мы будем считать, что исходный набор отношений уже соответствует этому требованию. В теории реляционных баз данных обычно выделяется следующая последовательность нормальных форм: первая нормальная форма (1NF); вторая нормальная форма (2NF); третья нормальная форма (3NF); нормальная форма Бойса-Кодда (BCNF); четвертая нормальная форма (4NF); пятая нормальная форма, или нормальная форма проекции-соединения (5NF или PJ/NF); доменно–ключевая нормальная форма.Основные свойства нормальных форм: каждая следующая нормальная форма в некотором смысле лучше предыдущей; при переходе к следующей нормальной форме свойства предыдущих нормальных свойств сохраняются. В основе процесса проектирования лежит метод нормализации, декомпозиция отношения, находящегося в предыдущей нормальной форме, в два или более отношения, удовлетворяющих требованиям следующей нормальной формы. Наиболее важные на практике нормальные формы отношений основываются на фундаментальном в теории реляционных баз данных понятии функциональной зависимости. Для дальнейшего изложения нам потребуются несколько определений. Определение 1. Функциональная зависимость В отношении R атрибут Y функционально зависит от атрибута X (X и Y могут быть составными) в том и только в том случае, если каждому значению X соответствует в точности одно значение Y: R.X (r) R.Y. Определение 2. Полная функциональная зависимость Функциональная зависимость R.X (r) R.Y называется полной, если атрибут Y не зависит функционально от любого точного подмножества X. Определение 3. Транзитивная функциональная зависимость Функциональная зависимость R.X -> R.Y называется транзитивной, если существует такой атрибут Z, что имеются функциональные зависимости R.X -> R.Z и R.Z -> R.Y и отсутствует функциональная зависимость R.Z --> R.X. (При отсутствии последнего требования мы имели бы "неинтересные" транзитивные зависимости в любом отношении, обладающем несколькими ключами.) Определение 4. Неключевой атрибут Неключевым атрибутом называется любой атрибут отношения, не входящий в состав первичного ключа (в частности, первичного). Определение 5. Взаимно независимые атрибуты Два или более атрибута взаимно независимы, если ни один из этих атрибутов не является функционально зависимым от других. Нормализация – это формальный метод анализа отношений на основе их первичного ключа (или потенциальных ключей) и существующих функциональных зависимостей. Он включает ряд правил, которые использоваться для проверки отдельных отношений таким образом, чтобы вся база данных могла быть нормализована до желаемой степени. Чаще всего нормализация осуществляется в виде нескольких последовательно выполняемых этапов, каждый из которых соответствует определенной нормальной форме, обладающей известными свойствами. В ходе нормализации формат отношений становится все более ограниченным (строгим) и менее восприимчивым к аномалиям обновления. При работе с реляционной моделью данных важно понимать, что для создания отношений приемлемого качества обязательно только выполнение требований первой нормальной формы(1НФ). Все остальные формы могут использоваться по желанию проектировщиков. Но для того чтобы избежать аномалий обновления нормализацию рекомендуется выполнять как минимум до третьей нормальной формы (3НФ). Аномалии модификации:Аномалия удаления – т.е., удаляя факты, относящиеся к одной сущности, мы непроизвольно удаляем факты, относящиеся к другой сущности. Аномалия ввода - мы хотим записать в базу данных факт, однако мы не можем ввести эти данные в отношение, пока хотя бы один факт не будет записан в это отношение.
Первая нормальная форма (1НФ)
Таблица находится в первой нормальной форме (1НФ) если: ячейки таблицы должны содержать одиночные значения и в качестве значений не допускаются ни повторяющиеся группы, ни массивы. Все записи в одном столбце (атрибуте) должны иметь один и тот же тип. Каждый столбец должен иметь уникальное имя, но порядок следования столбцов в таблице несуществен. В таблице не может быть двух одинаковых строк, порядок следования строк в таблице несуществен. Отношения на след. рисунке находятся в первой нормальной форме, однако они могут иметь аномалии модификации. Чтобы удалить эти аномалии, мы разбиваем отношения на два или более новых отношений.

|
Вторая нормальная форма (2НФ)
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 3088; Нарушение авторских прав?; Мы поможем в написании вашей работы!