КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Команды DML
|
|
|
|
О командах DDL
CREATE - используется для создания новых таблиц, столбцов и индексов.
DROP - используется для удаления столбцов и индексов.
ALTER - используется для добавления в таблицы новых столбцов и изменения определенных столбцов.
SELECT - наиболее часто используемая команда, применяется для получения набора данных из таблицы базы данных. Команда SELECT имеет следующий синтаксис:
SELECT список_полей1 FROM имя_таблицы [WHERE критерий ORDER BY список_полей2 [ASC | DESC]]
Операторы, находящие внутри квадратных скобок не обязательны, а вертикальная черта означает, что должна присутствовать одна из указанных фраз, но не обе.
Для примера создадим простейший запрос на получение данных из полей "name" и "phone" таблицы "friends":
SELECT name, phone FROM friends
Если необходимо получить все поля таблицы, то не обязательно их перечислять, достаточно поставить звездочку (*):
SELECT * FROM friends
Для исключения из выводимого списка повторяющихся записей, используется ключевое слово DISTINCT:
SELECT DISTINCT name FROM friends
Если необходимо получить отдельную запись, то используется оператор WHERE. Например, нам надо получить из таблицы "friends" номер телефона "Сергей Иванов":
SELECT * FROM friends WHERE name = ' Сергей Иванов'
или наоборот, нам надо узнать кому принадлежит телефон 293-89-13:
SELECT * FROM friends WHERE phone = 293-89-13'
Помимо этого можно использовать подстановочные символы, таким образом, создавая шаблоны поиска. Для этого используется оператор LIKE. Оператор LIKE имеет следующие операторы подстановки:
* - соответствует строке состоящей из одного или более символов;
_ - соответствует одному любому символу;
[] - соответствует одному символу из определенного набора;
Например, для получения записей из поля "name" содержащих слово "Сергей", запрос будит выглядеть следующим образом:
SELECT * FROM friends WHERE name LIKE '*Сергей*'
Для определения порядка, в котором возвращаются данные, используется оператор ORDER BY. Без этого оператора порядок возвращаемых данных невозможно предсказать. Ключевые слова ASC и DESC позволяют определить направление сортировки. ASC - упорядочивает по возрастанию, а DESC - по убыванию.
Например, запрос на получение списка записей из поля "name" в алфавитном порядке будет выглядеть следующим образом:
SELECT * FROM friends ORDER BY name
Обратим внимание на то, что ключевое слово ASC указывать не обязательно, поскольку оно используется по умолчанию.
INSERT - данная команда служит для добавления новой записи в таблицу. Записывается она следующим образом:
INSERT INTO имя_таблицы VALUES (список_значений)
Обратим внимание на то, что типы значений в списке значений должны соответствовать типам значений полей таблицы, например:
INSERT INTO friends VALUES ('Анна Осипова', '495-09-81')
В данном примере в таблицу friends добавляется новая запись с указанными значениями.
UPDATE - эта команда применяется для обновления данных в таблице и чаще всего используется совместно с оператором WHERE. Команда UPDATE имеет следующий синтаксис:
UPDATE имя_таблицы SET имя_поля = значение [WHERE критерий]
Если опустить оператор WHERE, то будут обновлены данные во всех определенных полях таблицы. Для примера, поменяем номер телефона Сергея Иванова:
UPDATE friends SET phone = '255-55-55' WHERE name = 'Сергей Иванов'
DELETE - как вы уже наверное поняли, эта команда служит для удаления записей из таблицы. Как и UPDATE, команда DELETE обычно используется с оператором WHERE, если этот оператор пропустить, то будут удалены все данные из указанной таблицы. Синтаксис команды DELETE выглядит следующим образом:
DELETE FROM имя_таблицы [WHERE критерий]
Для примера, давайте удалим Сергея Иванова из нашей таблицы:):
DELETE FROM friends WHERE name = 'Сергей Иванов')
13. Логические операции при формировании операторов поиска нужных записей в БД.
(При создании или изменении условий поиска допускается использование стандартных логических операторов: NOT - Логическое отрицание условия, AND - Должны выполняться оба условия, OR - Должно выполняться хотя бы одно из условий. Можно задать несколько условий отбора, соединенных логическим оператором или (or), для некоторого поля одним из двух способов: можно ввести все условия в одну ячейку строки Условие отбора, соединив их логическим оператором или (or) или ввести второе условие в отдельную ячейку строки или. Чтобы объединить несколько условий отбора оператором и (and), следует привести их в одной строке. Операторы и и или применяются как отдельно, так и в комбинации. Приоритет логических операторов:
1. Оператор отрицания логического выражения - NOT (высший приоритет).
2. Оператор AND.
3. Оператор OR (низший приоритет).
Также при формировании поиска можно использовать оператор Between позволяет задать диапазон значений. Оператор I n позволяет задавать используемый для сравнения список значений. Оператор Like полезен для поиска образцов в текстовых полях, причем можно использовать шаблоны: * — обозначает любое количество символов;? — любой одиночный символ; # — указывает что в данной позиции должна быть цифра.)
14. Язык SQL. Многотабличные запросы.
(Одна из наиболее важных особенностей запросов SQL - это их способность определять связи между многочисленными таблицами и выводить всю информацию из них в терминах этих связей, внутри одной команды. Этот вид операции называется – соединением (JOIN).
Чтобы понять, как в SQL реализуются многотабличные запросы, рассмотрим запрос, который соединяет данные из двух различных таблиц.
Составить список всех сотрудников, работающих в Минском отделении.
SELECT fname, lname, position, S.tel_no
FROM branch B, staff S
WHERE B.bno = S.bno AND city =‘Минск’;
При отработке запроса СУБД должна произвести ряд действий, связанных с соединением таблиц branch и staff. Так сначала просматривается столбец city с целью фильтрации строк со значениями отличными от значения ‘Минск’, далее для отфильтрованных строк таблицы определяются значения столбца bno как идентификаторов Минских отделений. После этого просматривается таблица staff F с целью выявления строк со значениями в столбце bno соответствующими идентификатору первого выявленного Минского офиса. В найденных строках оставляются значения столбцов указанных после ключевого слова SELECT. Далее эта же таблица просматривается для выявления строк соответствующих “второму” Минскому офису и т. д. до последнего. В итоге формируется таблица результатов с запрошенной информацией.
Отметим некоторые особенности многотабличных запросов. Как видно из примера, в многотабличном запросе часто используются полные имена столбцов, при этом в предложении FROM указываются псевдонимы таблиц, чтобы упростить обращение к столбцам по полному имени, а также обеспечить однозначность ссылок на столбцы. Кроме этого особый смысл может иметь выбор всех столбцов (SELECT *), например:
SELECT staff. *, area, city
FROM staff s, branch b
WHERE b.bno = s.bno;
Помимо объединения двух таблиц SQL допускает также объединение трёх и более таблиц. Ограничений по количеству объединяемых таблиц ни стандарт, ни разработчики СУБД не предусматривают, однако следует иметь в виду, что при увеличении количества объединяемых таблиц в запросе снижается его “читабельность” и скорость выполнения в силу значительного увеличения затрат ресурсов и машинного времени при его обработке.
В приложениях, предназначенных для оперативной обработки транзакций (OLTP), запрос обычно ссылается только на одну или две таблицы. В этих приложениях время ответа является критичной величиной, пользователь, как правило, вводит один или два элемента данных, и ему требуется получить ответ от базы данных в течение одной или двух секунд.
В OLAP-приложениях, предназначенных для поддержки, принятия решений, запрос, как правило, обращается ко многим таблицам и использует сложные отношения, существующие в базе данных. В этих приложениях результаты запроса нужны для принятия важных решений, поэтому вполне приемлемыми считаются запросы, которые выполняются несколько минут и более.
Кроме того, комбинирование результирующих таблиц можно осуществлять с помощью операторов UNION – объединение, INTERSECT – пересечение, EXCEPT (minus) – разность.
При этом на таблицы накладываются определенные ограничения, т.е. таблицы должны быть совместимы по соединению – иметь одну и ту же структуру: одинаковое количество столбцов, в столбцах размещаются данные одного типа и длины.
Обязанность проверять принадлежность данных к одному домену возлагается на пользователя. Общий синтаксис применения операторов комбинирования:
Operator[all][corresponding[by{ column1 [, …]}]]
Пример. Вывести список всех регионов, в которых либо находится отделение компании, либо располагаются сдаваемые в аренду объекты:
(SELECT area
FROM branch
WHERE area IS NOT NULL)
UNION
(SELECT area
FROM property_for_rent
WHERE area IS NOT NULL);
Пример. Вывести список всех городов, в которых находятся и отделение компании и сдаваемые в аренду объекты:
(SELECT city
FROM branch)
INTERSECT
(SELECT city
FROM property_for_rent);
Пример. Вывести список всех городов, в которых находятся отделения компании, но нет сдаваемых в аренду объектов:
(SELECT city
FROM branch)
EXCEPT
(SELECT city
FROM property_for_rent);
Все эти примеры можно реализовать и по-другому, без использования операторов комбинирования запросов. Возможность использования нескольких эквивалентных форм – один из самых существенных недостатков языка SQL.)
15. Технология оперативной обработки транзакции (ОLТР-технология). Информационные хранилища. ОLАР-технология.
(Сегодня среди средств, предлагаемых рынком информационных технологий, по обработке и визуализации данных для принятия управленческих решений в наибольшей мере отвечают OLTP- и OLAP-технологии. OLTP-технология ориентирована на оперативную обработку данных, а более современная OLAP-технология - на интерактивный анализ данных. Системы, разработанные на их основе, позволяют достигнуть понимания процессов, происходящих на объекте управления, путем оперативного доступа к разнообразным срезам данных (представлениям содержимого баз данных, организованным так, чтобы отразить различные аспекты деятельности предприятия). В частности, обеспечивая графическое представление данных, OLAP способна сделать результаты обработки данных легкими для восприятия.
OLTP (Online Transaction Processing) — обработка транзакций в реальном времени. Способ организации БД, при котором система работает с небольшими по размерам транзакциями, но идущими большим потоком, и при этом клиенту требуется от системы максимально быстрое время ответа.
В современных СУБД сериализация транзакций организуется через механизм блокировки, т.е. на время выполнения транзакции СУБД блокирует БД или ее часть, к которым обращается транзакция, блокировка сохраняется до момента фиксации транзакции. Если в процессе параллельной обработки другой транзакцией делается попытка обратиться к блокированным данным, то обработка транзакции приостанавливается и возобновляется только после завершения транзакции, заблокировавшей данные и снятия блокировки. Чем меньше блокируемый объект, тем больше оперативность БД. Транзакция, обновляющая данные на нескольких узлах сети, называется РАСПРЕДЕЛЕННОЙ. Если транзакция работает с БД, расположенной на одном узле, то она называется ЛОКАЛЬНОЙ. С точки зрения пользователя локальная и распределенная транзакция должны обрабатываться одинаково, т.е. СУБД должна организовывать процесс выполнения распределения транзакции так чтобы все входящие в нее локальные транзакции синхронно фиксировались на всех затрагиваемых ими узлах распределенной системы. При этом распределенная транзакция должна фиксироваться лишь в том случае, когда зафиксированы все составляющие ее локальной транзакции, а если прерывается хотя бы одна из локальных транзакций – должна быть прервана и вся распределенная транзакция. Для реализации этих требований на практике СУБД используется механизм двухстадийной фиксации транзакций.
1. Сервер БД, фиксирующий распределенную транзакцию посылает команду «Приготовиться к фиксации» всем узлам сети, зарегистрированным для выполнения транзакций. Если хотя бы один из серверов не дает ответа о готовности, то сервер распределенной БД совершает откат локальной транзакции на всех узлах.
2. Все локальные СУБД готовы к фиксации, т.е. сервер обрабатывает распределенную транзакцию, заканчивает ее фиксацию, посылая команду зафиксировать транзакцию всем локальным серверам.
OLAP (англ. online analytical processing, аналитическая обработка в реальном времени) — технология обработки информации, включающая составление и динамическую публикацию отчётов и документов. Используется аналитиками для быстрой обработки сложных запросов к базе данных. Служит для подготовки бизнес-отчётов по продажам, маркетингу, в целях управления, т. н. data mining — добыча данных (способ анализа информации в базе данных с целью отыскания аномалий и трендов без выяснения смыслового значения записей).
OLAP делает мгновенный снимок реляционной БД и структурирует её в пространственную модель для запросов. Заявленное время обработки запросов в OLAP составляет около 0,1 % от аналогичных запросов в реляционную БД.
OLAP-структура, созданная из рабочих данных, называется OLAP-куб. Куб создаётся из соединения таблиц с применением схемы звезды или схемы снежинки. В центре схемы звезды находится таблица фактов, которая содержит ключевые факты, по которым делаются запросы. Множественные таблицы с измерениями присоединены к таблице фактов. Эти таблицы показывают, как могут анализироваться агрегированные реляционные данные. Количество возможных агрегирований определяется количеством способов, которыми первоначальные данные могут быть иерархически отображены.
Например, все клиенты могут быть сгруппированы по городам или по регионам страны (Запад, Восток, Север и т. д.), таким образом, 50 городов, 8 регионов и 2 страны составят 3 уровня иерархии с 60 членами. Также клиенты могут быть объединены по отношению к продукции; если существуют 250 продуктов по 2 категориям, 3 группы продукции и 3 производственных подразделения, то количество агрегатов составит 16560. При добавлении измерений в схему, количество возможных вариантов быстро достигает десятков миллионов и более.
OLAP-куб содержит в себе базовые данные и информацию об измерениях (агрегатах). Куб потенциально содержит всю информацию, которая может потребоваться для ответов на любые запросы. Из-за громадного количества агрегатов, зачастую полный расчёт происходит только для некоторых измерений, для остальных же производится «по требованию».
Сложность в применении OLAP состоит в создании запросов, выборе базовых данных и разработке схемы, в результате чего большинство современных продуктов OLAP поставляются вместе с огромным количеством предварительно настроенных запросов. Другая проблема — в базовых данных. Они должны быть полными и непротиворечивыми
Первым продуктом, выполняющим OLAP-запросы, был Express (компания IRI). Однако, сам термин OLAP был предложен Эдгаром Коддом, «отцом реляционных БД». А работа Кодда финансировалась Arbor, компанией, выпустившей свой собственный OLAP-продукт — Essbase (позже купленный Hyperion, которая в 2007 г. была поглощена компанией Oracle) — годом ранее.
Другие хорошо известные OLAP-продукты включают Microsoft Analysis Services (ранее называвшиеся OLAP Services, часть SQL Server), Oracle OLAP Option, DB2 OLAP Server от IBM (фактически, EssBase с дополнениями от IBM), SAP BW, SAS OLAP Server, продукты Brio, BusinessObjects, Cognos, MicroStrategy и других производителей.
Наибольшее применение OLAP находит в продуктах для бизнес-планирования и хранилищах данных.
В OLAP применяется многомерное представление агрегированных данных для обеспечения быстрого доступа к стратегически важной информации в целях углубленного анализа. Приложения OLAP должны обладать следующими основными свойствами:
· многомерное представление данных;
· поддержка сложных расчетов;
· правильный учет фактора времени.
Преимущества OLAP:
· повышение производительности производственного персонала, разработчиков прикладных программ. Своевременный доступ к стратегической информации.
· предоставление пользователям достаточных возможностей для внесения собственных изменений в схему.
· приложения OLAP опираются на хранилища данных и системы OLTP, получая от них актуальные данные, что дает сохранение контроля целостности корпоративных данных.
· уменьшение нагрузки на системы OLTP и хранилища данных.
| OLAP | OLTP |
| Хранилище данных должно включать как внутренние корпоративные данные, так и внешние данные | основным источником информации, поступающей в оперативную БД, является деятельность корпорации, а для проведения анализа данных требуется привлечение внешних источников информации (например, статистических отчетов) |
| Объем аналитических БД как минимум на порядок больше объема оперативных. для проведения достоверных анализа и прогнозирования в хранилище данных нужно иметь информацию о деятельности корпорации и состоянии рынка на протяжении нескольких лет | Для оперативной обработки требуются данные за несколько последних месяцев |
| Хранилище данных должно содержать единообразно представленную и согласованную информацию, максимально соответствующую содержанию оперативных БД. Необходима компонента для извлечения и "очистки" информации из разных источников. Во многих крупных корпорациях одновременно существуют несколько оперативных ИС с собственными БД (по историческим причинам). | Оперативные БД могут содержать семантически эквивалентную информацию, представленную в разных форматах, с разным указанием времени ее поступления, иногда даже противоречивую |
| Набор запросов к аналитической базе данных предсказать невозможно. хранилища данных существуют, чтобы отвечать на нерегламентированные запросы аналитиков. Можно рассчитывать только на то, что запросы будут поступать не слишком часто и затрагивать большие объемы информации. Размеры аналитической БД стимулируют использование запросов с агрегатами (сумма, минимальное, максимальное, среднее значение и т.д.) | Системы обработки данных создаются в расчете на решение конкретных задач. Информация из БД выбирается часто и небольшими порциями. Обычно набор запросов к оперативной БД известен уже при проектировании |
| При малой изменчивости аналитических БД (только при загрузке данных) оказываются разумными упорядоченность массивов, более быстрые методы индексации при массовой выборке, хранение заранее агрегированных данных | Системы обработки данных по своей природе являются сильно изменчивыми, что учитывается в используемых СУБД (нормализованная структура БД, строки хранятся неупорядоченно, B-деревья для индексации, транзакционность) |
| Информация аналитических БД настолько критична для корпорации, что требуются большая грануляция защиты (индивидуальные права доступа к определенным строкам и/или столбцам таблицы) | Для систем обработки данных обычно хватает защиты информации на уровне таблиц |
Задачи OLTP-системы – это быстрый сбор и наиболее оптимальное размещение информации в базе данных, а также обеспечение ее полноты, актуальности и согласованности. Однако такие системы не предназначены для максимально эффективного, быстрого и многоаспектного анализа.
Разумеется, по собранным данным можно строить отчеты, но это требует от бизнес-аналитика или постоянного взаимодействия с IT-специалистом, или специальной подготовки в области программирования и вычислительной техники.
Как выглядит традиционный процесс принятия решений в российской компании, использующей информационную систему, построенную на OLTP-технологии?
Менеджер дает задание специалисту информационного отдела в соответствии со своим пониманием вопроса. Специалист информационного отдела, по-своему осознав задачу, строит запрос оперативной системе, получает электронный отчет и доводит его до сведения руководителя. Такая схема принятия критически важных решений обладает следующими существенными недостатками:
· используется ничтожное количество данных;
· процесс занимает длительное время, поскольку составление запросов и интерпретация электронного отчета – операции довольно канительные, тогда как руководителю, может быть, необходимо принять решение незамедлительно;
· требуется повторение цикла в случае необходимости уточнения данных или рассмотрения данных в другом разрезе, а также при возникновении дополнительных вопросов. Причем этот медленный цикл приходится повторять и, как правило, неоднократно, при этом времени на анализ данных тратится ещё больше;
· негативным образом сказывается различие в профессиональной подготовке и областях деятельности специалиста по информационным технологиям и руководителя. Зачастую они мыслят разными категориями и, как следствие, не понимают друг друга;
· неблагоприятное действие оказывает такой фактор, как сложность электронных отчетов для восприятия. У руководителя нет времени выбирать интересующие цифры из отчёта, тем более что их может оказаться слишком много. Понятно, что работа по подготовке данных чаще всего ложится на специалистов информационных отделов. В результате грамотный специалист отвлекается на рутинную и малоэффективную работу по составлению таблиц, диаграмм и т. д., что, естественно, не способствует повышению его квалификации.
Выход из этой ситуации один, и сформулирован он Биллом Гейтсом в виде выражения: "Информация на кончиках пальцев". Исходная информация должна быть доступна ее непосредственному потребителю – аналитику. Именно непосредственно доступна. А задачей сотрудников информационного отдела является создание системы сбора, накопления, хранения, защиты информации и обеспечения ее доступности аналитикам.
Мировая индустрия давно знакома с этой проблемой, и вот уже почти 30 лет существуют OLAP-технологии, которые и предназначены именно для того, чтобы бизнес-аналитики имели возможность оперировать с накопленными данными, непосредственно участвовать в их анализе. Подобные аналитические системы противоположны OLTP-системам в том плане, что они устраняют информационную избыточность ("сворачивают" информацию). Вместе с тем очевидно, что именно избыточность первичной информации определяет эффективность анализа. СППР, объединяя эти технологии, дают возможность решать целый ряд задач:
· Аналитические задачи: вычисление заданных показателей и статистических характеристик бизнес-процессов на основе ретроспективной информации, находящейся в хранилищах данных.
· Визуализацию данных: представление всей имеющейся информации в удобном для пользователя графическом и табличном виде.
· Получение новых знаний: определение взаимосвязи и взаимозависимости бизнес-процессов на основе существующей информации (проверка статистических гипотез, кластеризация, нахождение ассоциаций и временных шаблонов).
· Имитационные задачи: математическое моделирование поведения сложных систем в течение произвольного периода времени. Иными словами, это задачи, связанные с необходимостью ответить на вопрос: "Что будет, если...?"
· Синтез управления: определение допустимых управляющих воздействий, обеспечивающих достижение заданной цели.
· Оптимизационные задачи: интеграция имитационных, управленческих, оптимизационных и статистических методов моделирования и прогнозирования.
Менеджеры предприятия, использующие инструментальные средства OLAP-технологии, даже без специальной подготовки могут самостоятельно и оперативно получать всю необходимую для исследования закономерностей бизнеса информацию, причем в самых различных комбинациях и срезах бизнес-анализа. Бизнес-аналитик имеет возможность видеть перед собой список измерений и показателей бизнес-системы. При столь простом интерфейсе аналитик может строить любые отчеты, перестраивать измерения (скажем, делать кросс-таблицы – накладывать одно измерение на другое). Кроме этого, он получает возможность создавать свои функции на базе существующих показателей, проводить анализ "что, если" – получать результат, задавая зависимости каких-либо показателей бизнес-функций или бизнес-функцию от показателей. При этом максимальный отклик любого отчета не превышает 5 секунд.)
16. Системный каталог и каталог базы данных. Методы просмотра метаданных.
(Словарь данных, или системный каталог является хранилищем информации, содержащей данные в базе данных (данные о данных, метаданные). Наличие словаря данных обуславливает независимость разрабатываемых в рамках автоматизированной информационной системы прикладных программ от данных и наоборот.
В зависимости от используемой СУБД, количество информации в системном каталоге и способы её использования могут изменяться. Обычно в словаре данных хранятся описания структур объектов БД:
— имена, типы и размеры элементов данных (таблицы, поля таблиц);
— имена связей;
— имена, описание структур объектов БД;
— накладываемые на данные ограничения целостности;
— имена пользователей, которые имеют права доступа к объектам БД;
— пользовательские ограничения;
— и другое.
Любая СУБД, в которой создается словарь данных, имеет средства (комплект утилит) для просмотра и работы с метаданными. Так, например, работая с локальным сервером InterBase, средствами утилиты IBConcole можно просмотреть перечень объектов БД и их структуру – пункты меню Database, Veiw Metadata. СУБД, поддерживающие работу со словарем данных, имеют также таблицу, в которой есть описание структуры и словаря. Это делает возможным просмотр метаданных с использованием команды Select.
)
17. Понятие целостности базы данных. Опишите процесс восстановления целостности БД.
(При работе БД должна обеспечиваться целостность данных. Под целостностью данных понимают обеспечения целостности связей между записями в таблицах при удалении записей из первичных таблиц. То есть, при удалении записей из первичных таблиц автоматически должны удаляться связанные с ними записи из вторичных таблиц.
В случае несоблюдения целостности данных со временем в БД накопится большое количество записей во вторичных таблицах связанных с несуществующими записями в первичных таблицах, что приведёт к сбоям в работе БД и её засорению неиспользуемыми данными.
Существует два общих правила целостности БД:
- целостность объектов – требует, чтобы первичные ключи не содержали неопределённых (пустых значений)
- ссылочная целостность – требует, чтобы внешние ключи не содержали несогласованных с родительскими ключами значений.
Основные средства восстановления БД:
1) резервное копирование БД. При этом копия создается в момент, когда состояние БД является целостным, и сохраняется на иных внешних устройствах, чем то, на котором располагается сама база.
Полная резервная копия включает всю БД, частичная – только часть БД, определенную пользователем. Периодичность резервного копирования зависит от интенсивности обновления данных, частоты выполнения запросов, объема базы данных и др.
БД ее можно восстановить по последней резервной копии путем переноса копии на рабочее устройство и повторного проведения всех изменений, зафиксированных после создания данной резервной копии и до момента возникновения сбоя.
2) журнализация изменений БД. Журнал – это особая часть БД, недоступная пользователям СУБД, в которую поступают записи обо всех изменениях основной части БД (например, добавление или удаление строки из таблицы, изменение значения в ячейке таблицы). Для повышения надежности хранения журнала создаются его копии. В большинстве современных реляционных СУБД журнал изменений называется журналом транзакций. В нем регистрируются в хронологическом порядке все изменения, вносимые в БД каждой транзакцией.
При ведении журнала транзакций восстановить базу данных можно одним из двух методов:
1) накат (раскрутка) заключается во внесении в сохраненную копию БД результатов всех завершенных транзакций. При этом транзакции не обрабатываются повторно, а производятся изменения в БД согласно записям в журнале транзакций;
2) откат отменяет изменения, произведенные в БД ошибочными или незавершенными транзакциями. Затем повторно запускаются транзакции, которые выполнялись в момент возникновения сбоя.
)
18. Транзакции. Свойства транзакций (ACID). Способы завершений транзакций.
(Транзакция – неделимая с точки зрения воздействия на БД последовательность операторов манипулирования данными (чтения, удаления, вставки, модификации), такая, что:
1) либо результаты всех операторов, входящих в транзакцию, отображаются в БД;
2) либо воздействие всех операторов полностью отсутствует.
При этом для поддержания ограничений целостности на уровне БД допускается их нарушение внутри транзакции так, чтобы к моменту завершения транзакции условия целостности были соблюдены.
Для обеспечения контроля целостности каждая транзакция должна начинаться при целостном состоянии БД и должна сохранить это состояние целостным после своего завершения. Если операторы, объединенные в транзакцию, выполняются, то происходит нормальное завершение транзакции, и БД переходит в обновленное (целостное) состояние. Если же происходит сбой при выполнении транзакции, то происходит так называемый откат к исходному состоянию БД.
Существуют различные модели транзакций, которые могут быть классифицированы на основании различных свойств, включающих структуру транзакции, параллельность внутри транзакции, продолжительность и т. д.
В настоящий момент выделяют следующие типы транзакций: плоские или классические транзакции, цепочечные транзакции и вложенные транзакции.
Плоские, или традиционные, транзакции, характеризуются четырьмя классическими свойствами: атомарности, согласованности, изолированности, долговечности (прочности) — ACID (Atomicity, Consistency, Isolation, Durability). Иногда традиционные транзакции называют ACID-транзакциями. Упомянутые выше свойства означают следующее:
- Свойство атомарности (Atomicity) выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе.
- Свойство согласованности (Consistency) гарантирует, что по мере выполнения транзакций данные переходят из одного согласованного состояния в другое — транзакция не разрушает взаимной согласованности данных.
- Свойство изолированности (Isolation) означает, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно.
- Свойство долговечности (Durability) трактуется следующим образом: если транзакция завершена успешно, то те изменения в данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах (даже в случае последующих ошибок).
Возможны два варианта завершения транзакции. Если все операторы выполнены успешно и в процессе выполнения транзакции не произошло никаких сбоев программного или аппаратного обеспечения, транзакция фиксируется.
Фиксация транзакции — это действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции.
До тех пор пока транзакция не зафиксирована, допустимо аннулирование этих изменений, восстановление базы данных в то состояние, в котором она была на момент начала транзакции. Фиксация транзакции означает, что все результаты выполнения транзакции становятся постоянными. Они станут видимыми другим транзакциям только после того, как текущая транзакция будет зафиксирована. До этого момента все данные, затрагиваемые транзакцией, будут "видны" пользователю в состоянии на начало текущей транзакции.
Если в процессе выполнения транзакции случилось нечто такое, что делает невозможным ее нормальное завершение, база данных должна быть возвращена в исходное состояние. Откат транзакции — это действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.
Каждый оператор в транзакции выполняет свою часть работы, но для успешного завершения всей работы в целом требуется безусловное завершение всех их операторов. Группирование операторов в транзакции сообщает СУБД, что вся эта группа должна быть выполнена как единое целое, причем такое выполнение должно поддерживаться автоматически.
В стандарте ANSI/ISO SQL определены модель транзакций и функции операторов COMMIT и ROLLBACK. Стандарт определяет, что транзакция начинается с первого SQL-оператора, инициируемого пользователем или содержащегося в программе, изменяющего текущее состояние базы данных. Все последующие SQL-операторы составляют тело транзакции. Транзакция завершается одним из четырех возможных путей (рис. 11.1):
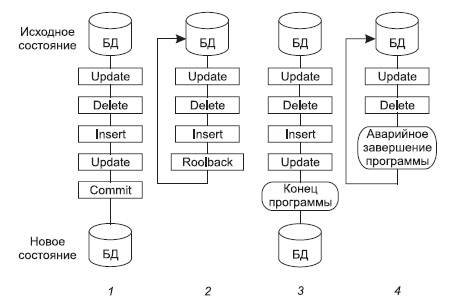
Рис. 11.1. Модель транзакций ANSI/ISO
1. оператор COMMIT означает успешное завершение транзакции; его использование делает постоянными изменения, внесенные в базу данных в рамках текущей транзакции;
2. оператор ROLLBACK прерывает транзакцию, отменяя изменения, сделанные в базе данных в рамках этой транзакции; новая транзакция начинается непосредственно после использования ROLLBACK;
3. успешное завершение программы, в которой была инициирована текущая транзакция, означает успешное завершение транзакции (как будто был использован оператор COMMIT);
4. ошибочное завершение программы прерывает транзакцию (как будто был использован оператор ROLLBACK).
В этой модели каждый оператор, который изменяет состояние БД, рассматривается как транзакция, поэтому при успешном завершении этого оператора БД переходит в новое устойчивое состояние.
В первых версиях коммерческих СУБД была реализована модель транзакций ANSI/ISO. В дальнейшем в СУБД SYBASE была реализована расширенная модель транзакций, которая включает еще ряд дополнительных операций. В модели SYBASE используются следующие четыре оператора:
- Оператор BEGIN TRANSACTION сообщает о начале транзакции. В отличие от модели в стандарте ANSI/ISO, где начало транзакции неявно задается первым оператором модификации данных, в модели SYBASE начало транзакции задается явно с помощью оператора начала транзакции.
- Оператор COMMIT TRANSACTION сообщает об успешном завершении транзакции. Он эквивалентен оператору COMMIT в модели стандарта ANSI/ISO. Этот оператор, как и оператор COMMIT, фиксирует все изменения, которые производились в БД в процессе выполнения транзакции.
- Оператор SAVE TRANSACTION создает внутри транзакции точку сохранения, которая соответствует промежуточному состоянию БД, сохраненному на момент выполнения этого оператора. В операторе SAVE TRANSACTION может стоять имя точки сохранения. Поэтому в ходе выполнения транзакции может быть запомнено несколько точек сохранения, соответствующих нескольким промежуточным состояниям.
- Оператор ROLLBACK имеет две модификации. Если этот оператор используется без дополнительного параметра, то он интерпретируется как оператор отката всей транзакции, то есть в этом случае он эквивалентен оператору отката ROLLBACK в модели ANSI/ISO. Если же оператор отката имеет параметр и записан в виде ROLLBACK B, то он интерпретируется как оператор частичного отката транзакции в точку сохранения B.
Принципы выполнения транзакций в расширенной модели транзакций представлены на рис. 11.2. На рисунке операторы помечены номерами, чтобы нам удобнее было проследить ход выполнения транзакции во всех допустимых случаях.
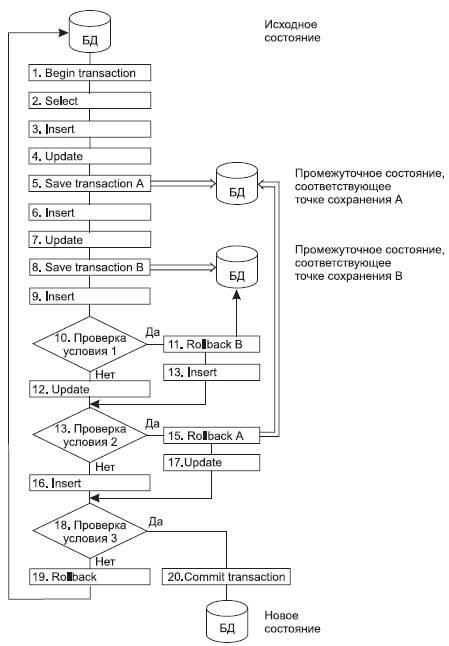
Рис. 11.2. Примеры выполнения транзакций в расширенной модели
Транзакция начинается явным оператором начала транзакции, который имеет в нашей схеме номер 1. Далее идет оператор 2, который является оператором поиска и не меняет текущее состояние БД, а следующие за ним операторы 3 и 4 переводят базу данных уже в новое состояние. Оператор 5 сохраняет это новое промежуточное состояние БД и помечает его как промежуточное состояние в точке А. Далее следуют операторы 6 и 7, которые переводят базу данных в новое состояние. А оператор 8 сохраняет это состояние как промежуточное состояние в точке В. Оператор 9 выполняет ввод новых данных, а оператор 10 проводит некоторую проверку условия 1; если условие 1 выполнено, то выполняется оператор 11, который проводит откат транзакции в промежуточное состояние В. Это означает, что последствия действий оператора 9 как бы стираются и база данных снова возвращается в промежуточное состояние В, хотя после выполнения оператора 9 она уже находилась в новом состоянии. И после отката транзакции вместо оператора 9, который выполнялся раньше из состояния В БД, выполняется оператор 13 ввода новых данных, и далее управление передается оператору 14. Оператор 14 снова проверяет условие, но уже некоторое новое условие 2; если условие выполнено, то управление передается оператору 15, который выполняет откат транзакции в промежуточное состояние А, то есть все операторы, которые изменяли БД, начиная с 6 и заканчивая 13, считаются невыполненными, то есть результаты их выполнения исчезли и мы снова находимся в состоянии А, как после выполнения оператора 4. Далее управление передается оператору 17, который обновляет содержимое БД, после этого управление передается оператору 18, который связан с проверкой условия 3. Проверка заканчивается либо передачей управления оператору 20, который фиксирует транзакцию, и БД переходит в новое устойчивое состояние, и изменить его в рамках текущей транзакции невозможно. Либо, если управление передано оператору 19, то транзакция откатывается к началу и БД возвращается в свое начальное состояние, а все промежуточные состояния здесь уже проверены, и выполнить операцию отката в эти промежуточные состояния после выполнения оператора 19 невозможно.)
19. Транзакции. Журнал транзакций.
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 3175; Нарушение авторских прав?; Мы поможем в написании вашей работы!