КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
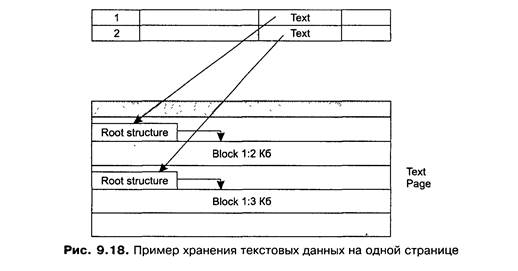
Страницы журнала транзакций
|
|
|
|
В отличие от версии 6.5 в новой версии под журнал транзакций отводится всегда отдельный файл. В предыдущей версии журнал транзакций являлся системной таблицей и хранился в системном сегменте LOG. Несмотря на настоятельные рекомендации располагать журнал транзакций и файлы базы данных на разных физических устройствах, СУБД автоматически не контролировала этот факт. В новой версии журнал транзакций всегда хранится в отдельном файле.
Архитектура разделяемой памяти
По причинам объективно существующей разницы в скорости работы процессоров, оперативной памяти и устройств внешней памяти (эта разница в скорости существовала, существует и будет существовать всегда) буферизация страниц базы данных в оперативной памяти — единственный реальный способ достижения удовлетворительной эффективности СУБД.
Операционные системы создают специальные системные буферы, которые служат для кэширования пользовательских процессов. Однако стратегия буферизации, применяемая в операционных средах, не соответствует целям и задачам СУБД, поэтому для оптимизации обработки данных одной из главных задач СУБД является создание эффективной системы управления процессом буферизации.
Разделяемая память, управляемая СУБД, состоит из нескольких типов буферов:
Q Буферы страниц данных, которые содержат копии страниц данных, с которыми работает СУБД.
Q Буферы страниц журнала транзакций, которые отражают процесс выполнения транзакции — последовательности операций над БД, переводящей БД из одного непротиворечивого состояния в другое непротиворечивое состояние.
Q Системные буферы, которые содержат общую информацию о БД, о пользователях, о физической структуре БД, о базе метаданных.
Информация в буферах взаимосвязана, и требуется эффективная система поддержки единой работы всех частей разделяемой памяти.
Если бы запись об изменении базы данных реально немедленно записывалась во внешнюю память, это привело бы к существенному замедлению работы системы.
Поэтому записи в журнал тоже буферизуются: при нормальной работе очередная страница выталкивается во внешнюю память журнала только при полном заполнении записями.
Но реальная ситуация является более сложной. Имеются два вида буферов — буфер журнала и буфер страниц оперативной памяти, которые содержат связанную информацию. И те и другие буферы могут выталкиваться во внешнюю память. Проблема состоит в выработке некоторой общей политики выталкивания, которая обеспечивала бы возможности восстановления состояния базы данных после сбоев.
Буфера не выделяются для каждого пользовательского процесса, они выделяются для всех процессов сервера БД. Это позволяет увеличить степень параллелизма при исполнении клиентских процессов.
Разделяемая память наиболее эффективно используется вспомогательными процессами сервера, иногда называемыми демонами, которые используются для синхронизации взаимодействующих процессов на сервере.
На этом мы закончили рассмотрение физических моделей, применяемых в базах данных. Физические модели большей частью скрыты от пользователей. Однако в SQL существует команда создания индексных файлов. При этом по умолчанию стандартно создаются индексные файлы для первичных ключей, для вторичных ключей индексные файлы создаются дополнительной командой CREATE INDEX, которая имеет следующий формат:
CREATE [UNIQUE] INDEX <имя_индекса> ON <имя_таблицы> (<имя_столбца>[<признак упорядочения^ |
[,<имя_столбца>[<признак упорядочения>...]) <имя_индекса > - уникальный идентификатор в системе. <Признак упорядочениям>::={ASC | DESC}
Здесь ASC — признак упорядочения по возрастанию, DESC — признак упорядочения по убыванию значений соответствующего столбца в индексе.
Индекс может быть удален командой DROP, которая имеет следующий формат:
DROP INDEX <имя индекса>
ГЛАВА 10 Распределенная обработка данных
При размещении БД на персональном компьютере, который не находится в сети, БД всегда используется в монопольном режиме. Даже если БД используют несколько пользователей, они могут работать с ней только последовательно, и поэтому вопросов о поддержании корректной модификации БД в этом случае здесь не стоит, они решаются организационными мерами — то есть определением требуемой последовательности работы конкретных пользователей с соответствующей БД. Однако даже в некоторых настольных БД требуется учитывать последовательность изменения данных при обработке, чтобы получить корректный результат: так, например, при запуске программы балансного бухгалтерского отчета все бухгалтерские проводки — финансовые операции должны быть решены заранее до запуска конечного приложения.
Однако работа на изолированном компьютере с небольшой базой данных в настоящий момент становится уже нехарактерной для большинства приложений. БД отражает информационную модель реальной предметной области, она растет по объему и резко увеличивается количество задач, решаемых с ее использованием, и в соответствии с этим увеличивается количество приложений, работающих с единой базой данных. Компьютеры объединяются в локальные сети, и необходимость распределения приложений, работающих с единой базой данных по сети, является несомненной.
Действительно, даже когда вы строите БД для небольшой торговой фирмы, у вас появляется ряд специфических пользователей БД, которые имеют свои бизнес-функции и территориально могут находиться в разных помещениях, но все они должны работать с единой информационной моделью организации, то есть с единой базой данных.
Параллельный доступ к одной БД нескольких пользователей, в том случае если БД расположена на одной машине, соответствует режиму распределенного доступа к централизованной БД. (Такие системы называются системами распределенной обработки данных.)
Если же БД распределена по нескольким компьютерам, расположенным в сети, и к ней возможен параллельный доступ нескольких пользователей, то мы имеем дело с параллельным доступом к распределенной БД. Подобные системы называются системами распределенных баз данных. В общем случае режимы использования БД можно представить в следующем виде (см. рис. 10.1).
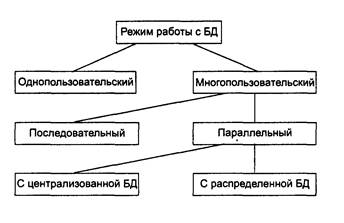
Рис. 10.1. Режимы работы с базой данных
Определим терминологию, которая нам потребуется для дальнейшей работы. Часть терминов нам уже известна, но повторим здесь их дополнительно.
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 547; Нарушение авторских прав?; Мы поможем в написании вашей работы!