КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Пример использование запроса SELECT для выборки нужных данных
|
|
|
|
В соответствии с технологической схема обработки информации (см. рис.8), на основании логической схемы базы данных (см. табл. 4, 5), следующие запросы позволяют:
1. Сформировать перечень коммунальных услуг по адресу ул. Центральная 2, кв. 1,SELECT Адрес, Вид услуги, Тариф FROM Таблица 4 WHERE Адрес= «Ул. Центральная 2 Кв.1»;
-в результате имеем результат представленный в табл. 7.
Таблица 7. Результат выполнения запроса о перечне коммунальных услуг.
| Адрес | Вид услуги | Тариф |
| Ул. Центральная 2 Кв.1 | Отопление | 1,54 |
| Ул. Центральная 2 Кв.1 | Водоотведение | 1,03 |
SELECT Адрес, Ф.И.О., Категория льготы FROM Таблица 5 WHERE Адрес= «Ул. Центральная 2 Кв.1»;
в результате имеем результат представленный в табл. 8.
Таблица 8. Результат выполнения запроса об определении квартиросъемщика и наличии льготы
| Адрес | Ф.И.О. | Категория Льготы |
| Ул. Центральная 2 Кв.1 | Попов В. Е. | Нет |
SELECT Адрес, Площадь, Кол-во человек FROM Таблица 5 WHERE Адрес= «Ул. Центральная 2 Кв.1»;
в результате имеем результат представленный в табл. 9.
Таблица 9. Результат выполнения запроса об определении дополнительных данных для расчета коммунальных услуг
| Адрес | Площадь | Кол-во человек |
| Ул. Центральная 2 Кв.1 |
Технологии «файл-сервер» и «клиент-сервер»
«Клиент-сервер» — это модель взаимодействия компьютеров в сети. Как правило, компьютеры не являются равноправными. Каждый из них имеет свое, отличное от других назначение, играет свою роль. Некоторые компьютеры в сети владеют и распоряжаются информационно-вычислительными ресурсами, такими как процессоры, файловая система, почтовая служба, служба печати, база данных. Другие же имеют возможность обращаться к этим службам, пользуясь услугами первых. Компьютер, управляющий тем или иным ресурсом, принято называть сервером этого ресурса, а компьютер, который может им воспользоваться, — клиентом. Конкретный сервер определяется видом ресурса, которым он владеет. Так, если ресурсом являются базы данных, то речь идет о сервере баз данных, назначение которого — обслуживать запросы клиентов, связанные с обработкой данных; если ресурс — это файловая система, то говорят о файловом сервере, или файл-сервере. В сети один и тот же компьютер может выполнять роль как клиента, так и сервера.
|
|
|
Этот же принцип распространяется и на взаимодействие программ. Если одна из них выполняет некоторые функции, предоставляя другим соответствующий набор услуг, то такая программа выступает в качестве сервера. Программы, которые пользуются этими услугами, принято называть клиентами. Так, ядро реляционной SQL-ориентированной СУБД часто называют сервером базы данных, или SQL-сервером, а программу, обращающуюся к нему за услугами по обработке данных, — SQL-клиентом.
Первоначально СУБД имели централизованную архитектуру. В ней сама СУБД и прикладные программы, которые работали с базами данных, функционировали на центральном компьютере (большая ЭВМ или мини-компьютер). Там же располагались базы данных. К центральному компьютеру были подключены терминалы, выступавшие в качестве рабочих мест пользователей. Все процессы, связанные с обработкой данных: поддержка ввода, осуществляемого пользователем, формирование, оптимизация и выполнение запросов, обмен с устройствами внешней памяти и т. д., — выполнялись на центральном компьютере, что предъявляло жесткие требования к его производительности. Особенности СУБД первого поколения напрямую связаны с архитектурой систем больших ЭВМ и мини-компьютеров и адекватно отражают все их преимущества и недостатки. Однако нас больше интересует современное состояние многопользовательских СУБД, для которых архитектура «клиент-сервер» стала фактическим стандартом. Сравним технологию «клиент-сервер» с технологией «файл-сервер» (рис. 25).
|
|
|
В файл-серверной системе данные хранятся на файловом сервере (например, Novell NetWare или Windows NT Server), а их обработка осуществляется на рабочих станциях, на которых, как правило, функционирует одна из так называемых «настольных СУБД» — Access, FoxPro, Paradox и т. п.
Приложение на рабочей станции отвечает за формирование пользовательского интерфейса, логическую обработку данных и за непосредственное манипулирование данными. Файловый сервер предоставляет услуги только самого низкого уровня — открытие, закрытие и модификацию файлов, а не базы данных. База данных существует только в «мозгу» рабочей станции.
Таким образом, непосредственным манипулированием данными занимается несколько независимых и не согласованных между собой процессоров. Кроме того, для осуществления любой обработки (поиск, модификация, суммирование и т. п.) все данные необходимо передать по сети с сервера на рабочую станцию.
В клиент-серверной системе функционируют (как минимум) два приложения — клиент и сервер, делящие между собой те функции, которые в файл-серверной архитектуре целиком выполняет приложение на рабочей станции. Хранением и непосредственным манипулированием данными занимается сервер баз данных, в качестве которого может выступать Microsoft SQL Server, Oracle, Sybase и т. п.
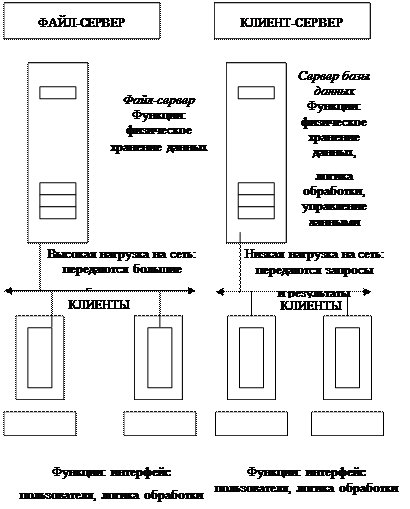

Рис. 25. Технологии «файл-сервер» (слева)
и «клиент-сервер» (справа)
Формированием пользовательского интерфейса занимается клиент; для построения интерфейса можно использовать целый ряд специальных инструментов, а также большинство настольных СУБД. Логика обработки данных может выполняться как на клиенте, так и на сервере. Клиент посылает на сервер запросы, сформулированные, как правило, на языке SQL. Сервер обрабатывает эти запросы и передает клиенту результат (разумеется, клиентов может быть много).
|
|
|
Таким образом, непосредственным манипулированием данными занимается один процессор. При этом обработка данных происходит там же, где данные хранятся — на сервере, что исключает необходимость передачи больших объемов данных по сети.
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 437; Нарушение авторских прав?; Мы поможем в написании вашей работы!