КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Логическая организация баз данных
|
|
|
|
В настоящее время известны три логические модели БД:
1) иерархическая;
2) сетевая;
3) реляционная.
Иерархическая модель данных представляет собой дерево графа, в вершинах которого располагаются записи. Между записями существуют отношения предок/потомок, связывающие каждый конкретный узел с его составляющими. Каждая из вершин связана только с одной вершиной вышележащего уровня.

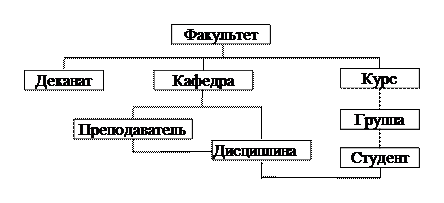
Поиск данных в такой структуре выполняется всегда по одной из ветвей, начиная с корневого элемента, т.е. должен быть указан полный путь движения по ветви. Так для поиска и выборки одного или нескольких экземпляров записи типа “Студент” необходимо указать корневой элемент “Факультет” и элементы “Курс”, “Группа”. Достоинствами данной СУБД являлась простота модели данных, а также высокое быстродействие.
Если структура данных оказывалась сложнее, чем традиционная иерархия, то простота организации иерархической базы данных становилась ее недостатком. Например, если рассмотреть работу торговой компании, то один заказ может участвовать в нескольких отношениях предок/потомок: с заказчиком, с менеджером или торговой точкой, отпустившей товар, а также с самим товаром. Однако иерархия допускает наличие только одного отношения между ее записями. В связи с этим для таких приложений была разработана сетевая модель данных, допускавшая множественные отношения типа предок/потомок.
Сетевая модель данных также использует графический способ представления данных, и схема отображается также в виде графа. Однако по сравнению с иерархической моделью никаких ограничений на количество связей, входящих в каждую вершину, не накладывается, что позволяет отображать связи между объектами предметной области практически любой степени сложности, в частности кольцевые структуры.
Однако в процессе создания и эксплуатации сетевых СУБД выявились существенные недостатки. Так, изменение структуры базы данных означало перестройку всего приложения. Наборы отношений и структуру записей следовало задавать наперед. Для того чтобы получить данные, программисту необходимо было писать программу навигации по базе данных, что могло занять от нескольких дней до нескольких недель, а данные к тому времени могли устареть.
Реляционная модель данных (РМД) была попыткой упростить структуру базы данных. В ней отсутствовали явные указатели на предков и потомков, а все данные были представлены в виде простых таблиц, разбитых на строки и столбцы, на пересечении которых находятся данные. В таблицах данные распределяются по столбцам, которые называют полями, и строкам, которые называют записями. Все таблицы названы соответствующими именами.
В каждой таблице БД должен существовать первичный ключ – одно или несколько полей, однозначно определяющие каждую запись таблицы. Значение первичного ключа должно быть уникальным, то есть в таблице не должно быть двух или более записей с одинаковым значением первичного ключа. С помощью ключевых полей таблицы связывают между собой в единую структуру. Именно от английского слова relation (связь) и произошло название реляционные базы данных.
Связи между таблицами
Связь между таблицами организуется на основе общего поля, причем в одной из таблиц оно обязательно должно быть ключевым, то есть на стороне “один” должно выступать ключевое поле, содержащее уникальные, неповторяющиеся значения. Значения на стороне “многие” могут повторяться.
Различают три вида связей между таблицами:
· один-к-одному;
· один-ко-многим:
· многие-ко-многим.
Связь один-к-одному связывает две таблицы по их ключевым полям. Это может применяться в тех случаях, когда для одного ключевого поля существует два больших блока информации, отличающиеся по смыслу. Например, паспортные данные студента (первый блок) и его успеваемость (второй блок). В этом случае создаются две таблицы, и затем они связываются по ключевому полю, предположим, по номеру зачетной книжки. При этом одной записи в таблице-потомке соответствует одна запись в таблице-предке.

Связь один-ко-многим является самой распространенной в реляционных базах данных. Приведем простой пример.
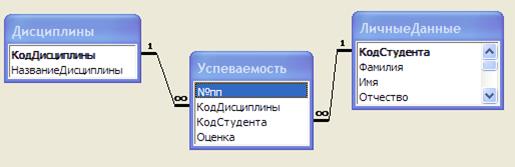
Рассмотрим таблицу ЛичныеДанные. Здесь поле КодСтудента является ключевым. Это понятно, поскольку у каждого студента должен быть свой уникальный код, идентифицирующий его однозначно. Если мы рассмотрим таблицу Успеваемость, то увидим, что в ней КодСтудента не может быть уникальным, поскольку в этой таблице хранится информация об успеваемости нескольких студентов. На схеме данных эти поля соединяются линией связи. С одной стороны эта линия маркирована значком 1, с другой стороны — значком “бесконечность”. Это графический метод изображения связи “один ко многим”.
Связь многие-ко-многим реализуется при помощи промежуточной таблицы со связями один-ко-многим.
Про подобные таблицы говорят, что они связаны реляционными отношениями. Соответственно, системы управления, способные работать со связанными таблицами, называют системами управления реляционными базами данных, а схему данных в технической литературе могут называть схемой реляционных отношений.
К числу наиболее распространенных реляционных СУБД относятся dBASE, FoxBASE, FoxPro, Clipper, Clarion, Paradox и др.
|
|
|
|
|
Дата добавления: 2015-05-09; Просмотров: 1083; Нарушение авторских прав?; Мы поможем в написании вашей работы!