КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Коммутаторы АТМ
|
|
|
|
Классификация коммутаторов АТМ
Обобщенная модель базового коммутатора представлена на рис. 4.8. Нулевые потери, наименьшая задержка и завышая пропускная способность, равная 1 или 100%; достигаются в идеальном коммутаторе, который коммутирует пакеты с любого количества активных линий привязки на входе (ЛП вх) за один коммутационный цикл (КЦ), равный L пак /V кс где L пак — длина пакета в битах; VД, — скорость передачи пакетов в канале связи.
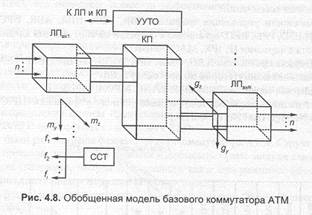
Обеспечивается одновременная доставка до N пакетов на любой из ЛП вых, хранящих их перед посылкой в канал связи в буфере неограниченной емкости. На практике, однако, буферы имеют конечную емкость, а построение КП, реализующего указанный режим доставки при больших N, оказывается нецелесообразным: во временных коммутаторах из-за большой скорости передачи пакетов через КП (Vвн), а в пространственных — из-за высокой аппаратной сложности. Поэтому практические разработки основываются, как правило, на компромисса между сложностью КП, емкостью и местом расположения буферов. Таким образом, наибольшие конструктивные отличия приходятся на принцип построения КП и буферную архитектуру, которые поэтому удобно принять в качестве главных классификационных признаков. Рассмотрим их более подробно.
По принципу построения КП разбивают на две группы: с общим или коллективным ресурсом (однопутевые) и с пространственным разделением (многопутевые). Общий ресурс в однопутевых КП представляет собой одновходовую или многовходовую общую память (ОП) либо коллективную среду передачи— мультиплексированную по времени шину с линейной (параллельной) или кольцевой (последовательной) конфигурацией.
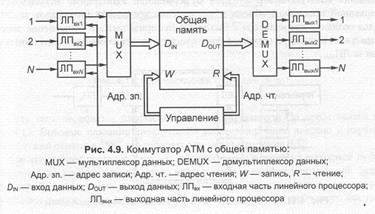
В коммутаторе с ОП (рис. 4.9) все поступающие на его вход пакеты мультиплексируются в один поток, который поступает в общую память для хранения. В памяти пакеты организуются в раздельные очереди на выход, по одной на каждый выходной канал. Одновременно путем поочередного извлечения пакетов из выходных очередей формируется выходной поток, который затем демультиплексируется и пакеты передаются по выходным каналам. В рассматриваемом варианте архитектуры должны быть удовлетворены два основных конструктивных требования. Во-первых, время, необходимое процессору для того, чтобы определить, в какую очередь поставить поступивший пакет и выработать соответствующие управляющие сигналы, должно быть достаточно мало, чтобы процессор ус- певал справляться с потоком «поступающих пакетов». Во-вторых, самое важное требование относится к коллективной памяти, к ее размеру и скорости записи/ считывания, которая должна быть достаточно велика, чтобы можно было обслуживать одновременно весь входной и выходной трафик. Если число портов равно N, а скорость обмена через порт Vкс, то скорость записи/считывания должна быть 2 N (например, для 32-канального коммутатора с канальной скоростью порядка 150 Мбит/с скорость записи/считывания должна составлять, по крайней мере, 9,6 Убит/с). Подобно коммутаторам с общей памятью коммутаторы с коллективной средой основаны на мультиплексировании всех поступающих пакетов в один поток и последующем демультиплексировании общего потока на отдельные потоки, по одному на каждый выходной канал.
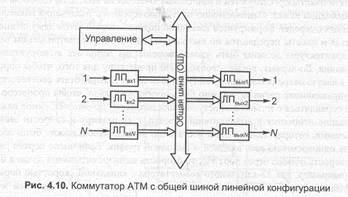
коммутаторах с коллективной средой, представляющей собой общую шину с линейной конфигурацией (рис. 4.10), все пакеты проходят по единому пути— широковещательной шине с временным разделением, а демультиплексирование осуществляется адресными фильтрами в выходных интерфейсах.
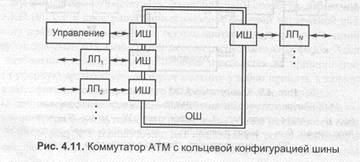
коммутаторах с кольцевой конфигурацией шины (рис. 4.11) сегменты пакетов (коммутационные слова) транслируются по кольцу в течение циклически повторяющихся временных интервалов, закрепленных за портами кольца. Для создания коммутатора с входной буферизацией необходимо использование маркерной процедуры обмена и закрепление временных интервалов за ЛП вх; а для создания коммутатора с выходной буферизацией — применение вместо маркерной процедуры адресной фильтрации и закрепление временных интервалов за ЛП вых.
Отличие этого типа коммутаторов от коммутаторов с коллективной памятью состоит в том, что в данном типе архитектуры осуществляется полностью раздельное использование памяти выходными очередями, так что последние могут быть организованы по принципу «первым пришел — первым обслужен» (FIFO).
Основу многопутевых КП составляют: однокаскадные (ОСС) и многокаскадные (МСС) соединительные сети. ОСС в свою очередь делятся на тасующие сети, сети типа «воронки» и расширенные коммутационные матрицы, а МСС — на одномаршрутные («баньяны») и много маршрутные сети.
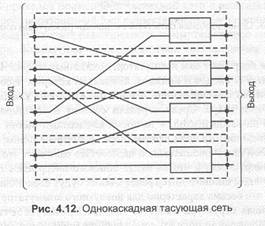
Однокаскадные тасующие сети основаны на принципе тасующей перестановки (рис. 4.12). Для того чтобы связать данный вход с произвольным выходом, необходим механизм обратной связи (штриховые линии на рис. 4.12). Очевидно, что ячейка может пройти через сеть несколько раз, прежде чем достигнет пункта назначения. Поэтому такие сети называются также рециркуляционными. Сети такого типа требуют небольшого числа коммутационных элементов, но эффективность их невелика.
Сеть типа «воронки», или «нокаутный» коммутатор АТМ представлена на pиc. 4.13. Впервые название «нокаутный» коммутатор было введено в научно- технический обиход в 1987 г. в лаборатории Белла компании АТТ.
Архитектурное решение данного коммутатора основано на выходной буферизации. Однако могут иметь место и некоторые элементы центральной буферизации. В «нокаутном» коммутаторе время доступа к памяти с выходными очередями должно быть очень мало. С целью уменьшения требуемого быстродействия памяти (и снижения сложности системы) в нокаутной «среде передачи» используется каскад концентрации, вносящий некоторую вероятность потери ячейки. Поэтому при проектировании нокаутного коммутатора требуется рассчитывать не только очереди, но также и коэффициент концентрации данной среды передачи.
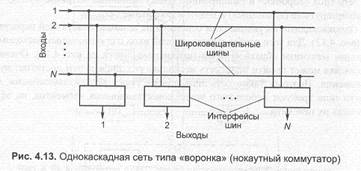
Рассмотрим подробнее сам коммутатор, показанный на рис. 4.13. Нокаутный коммутатор имеет N входов и выходов, каждый из которых работает с равными скоростями. Ячейки фиксированной длины прибывают на каждый вход в peгyлярном временном кадре. Среда передачи состоит из N широковещательную шин, по одной на каждый вход, в то время как каждый выход имеет доступ z ячейкам, поступающим по всем входам, через интерфейс шины, соединенный с каждой отдельной широковещательной шиной. Это означает, что среда передачи является неблокирующей, и что на входе шинного интерфейса потерь ячеек не происходит. В таком шинном интерфейсе ячейки будут соревноваться за единственный выход, что весьма характерно для нокаутного коммутатора.
Данная шинная структура имеет то главное преимущество, что каждая шина соединена только с одним входом, что обеспечивает простую реализацию и высокие скорости передачи, сравнительно с вариантом шины, разделяемой между несколькими входами. Действительно, если необходимо совместное использование шины входами, между всеми ими должна быть обеспечена хорошая синхронизация, которая, однако, не устраняет необходимости дополнительно учитывать отражения сигналов, особенно существенные при очень высоких скоростях в интерфейсе шины.
В каком-либо шинном интерфейсе может произойти ситуация поступлению нескольких ячеек, предназначенных единственному выходу. В худшем случае на
единственный выход направятся все N ячеек. Таким образом, необходимо наличие буфера для ячеек в интерфейсе шины. Если требуется гарантировать нулевые потери ячеек в фазе передачи в буфер, то память должна работать (записывать) со скоростью, в N раз превышающую скорость каждого входа. В нокаутном коммутаторе такая скорость уменьшена за счет «интеллектуальности» шинного интерфейса, который работает как концентратор с ненулевой вероятностью потери ячейки. Нокаутный коммутатор может расширяться до большого количества входов и выходов. Такое расширение достигается посредством введения L дополнительных входов к каждому концентратору выходного интерфейса. Этот способ расширения отличается от способов, где используются многоярусные соединительные сети. Благодаря тому, что все шинные интерфейсы коммутатора соединены с каждой шиной, они могут легко считывать широковещательную ячейку. Прием такой широковещательной ячейки идентичен процессу приема одиночной ячейки. Чтобы реализовать в пакетном фильтре распознавание также и широковещательных ячеек, к этим ячейкам добавляется специальное поле идентификации маршрутизации.
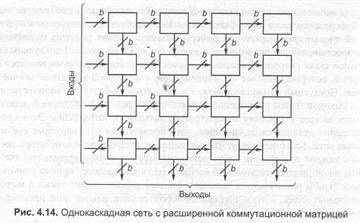
На рис. 4.14 приведен пример однокаскадной сети с расширенной коммутационной матрицей, образованной bxb коммутационными элементами. Теоретически, этот подход позволяет реализовывать коммутационную сеть любого желаемого размера. Коммутационные элементы, составляющие расширенную матрицу, должны иметь b добавочных входов и b добавочных выходов. Через добавочные выходы сигнал передается в следующий столбец матрицы. Добавочные входы соединены с обыкновенными выходами элемента того же столбца, находящегося в соседней сверху строке. Достоинство расширенной матрицы — малая задержка, ибо ячейка попадает в буфер при прохождении сети лишь один раз. Следует заметить, что задержка зависит от расположения входа. Рост числа коммутационных элементов и дополнительных входов ограничивает размер расширенной матрицы. Можно реализовать такие сети размером 64x64 или 128х128, однако для больших размеров предпочтительнее многокаскадные сети.
В многокаскадных одно маршрутных сетях существует только один путь, связывающий данный выход и данный вход. Эти сети называются также «баньянами». Сети-баньяны имеют н е д ост а т о к, состоящий в возможности возникновения внутренней блокировки, так как одна и та же внутренняя линия может входить в маршруты, начинающиеся у разных входов. Сети-баньяны разделяются на несколько подгрупп. В
L-слойных баньянах между собой соединяются только Элементы смежных каскадов. Каждый путь через сеть проходит ровно через каскадов. Класс этот далее подразделяется на регулярные и иррегулярные баньяны. Регулярные баньяны состоят из одинаковых коммутационных элементов, в иррегулярных же могут использоваться элементы различных типов.
Обобщенные дельта-сети относятся к классу иррегулярных баньянов. Регулярные баньяны экономичнее в реализации. Один из подклассов регулярных баньянов — SW-баньяны. Последние могут быть построены рекурсивно, начиная с базового коммутационного элемента, имеющего F входов и S выходов. Простейшая такая сеть (называемая однослойным баньяном) состоит из единственного коммутирующего элемента. L-слойный SW-баньян получается при соединении нескольких L-1-слойных SW-баньянов с дополнительным каскадом, состоящим из коммутационных FxS-элементов. Эти дополнительные элементы соединяются с SW-баньянами регулярным образом.
Одним из видов SW-баньянов являются дельта-сети. L-слойная сеть, состоящая из коммутационных FxS-элементов, имеет S x L выходов. Выходы могут быть пронумерованы
L-значными числами в S-ичной системе счисления. Каждая цифр обозначает нужный выход коммутационного элемента в соответствующем каскаде. Это дает простой способ маршрутизации, называемой самомаршрутизацией.
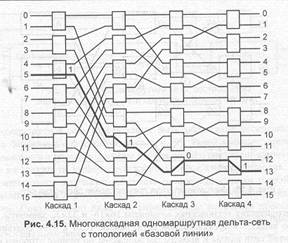
В прямоугольной дельта-сети коммутационные элементы имеют равное число выходов и входов (5 = L). Следовательно, число входов в сеть равно числу выходов из нее. Такие сети называются также дельта-Б-сетями. На рис. 4.15 показана четырехкаскадная дельта-2-сеть с топологией «базовой линии». Жирная линия указывает путь от входа 5 к выходу 13 (двоичный адрес 1101).
Особый класс дельта-сетей образуют бидельта-сети. Они остаются дельта-сетями, если поменять ролями входы и выходы. Все бидельта-сети топологически эквивалентны и преобразуются одна в другую переименованием элементов и
линий.
В многомаршрутных сетях существует множество путей, связывающих данный вход с нужным выходом. Это позволяет уменьшить количество внутренних блокировок или вообще избежать их. В большинстве много маршрутных сетей нужный путь выбирается в фазе установления соединения, и все ячейки данного соединения передаются по этому пути. Если коммутационные элементы сети имеют буферы типа «первым пришел — первым обслужен» (FIFO), то целостность последовательности ячеек автоматически сохраняется и их переупорядочение не требуется.
Многомаршрутные сети могут быть свернутые и развернутые. На рис. 4.16 изображена трехкаскадная свернутая сеть. В ней все входы и выходы расположены на одной стороне и внутренние линии сети работают в двустороннем режиме (каждая линия на рис. 4.16 изображает двунаправленную физическую линию связи). В свернутых сетях могут существовать короткие пути. Так, если входная и выходная линии соединены с одним и тем же коммутационным элементом, то ячейки могут «отражаться» сразу в этом элементе, не проходя путь до последнего (отражающего) каскада. Число коммутирующих элементов, через которые должна пройти ячейка, зависит от расположения входной и выходной линий. Количество каналов трехкаскадной сети, поступаемой из коммутирующих (bxb)-элементов равно (b/2)х(b/2)xb. L-слойный SW-баньян получается при соединении нескольких L — 1-слойных SW-баньянов с дополнительным каскадом, состоящим из коммутационных FxS-элементов. Эти дополнительные элементы соединяются с SW-баньянами регулярным образом.
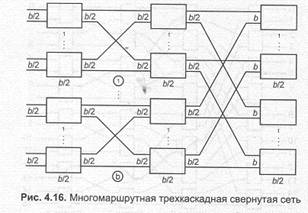
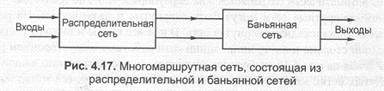
При сегодняшних технологиях возможны 16х16- и 32x32-элементы, что дает количество каналов в трехкаскадной сети, равное 1024 и 8192 соответственно, В развернутой сети входы и выходы расположены по разные стороны сети. Ос- новой таких сетей также служат bxb-элементы. На рис. 4.17 показана коммутационная сеть, состоящая из баньянной сети с буферами и предшествующей распределительной сети. Задача распределительной сети — как можно более правильное распределение ячеек по всем выходам баньянной сети. Этот подход позволяет уменьшить внутреннюю блокировку. Однако целостность последовательности ячеек при этом нарушается, и, следовательно, на выходе необходим механизм переупорядочивания ячеек.
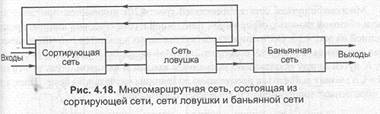
Иная возможная реализация развернутой сети включает, кроме баньяна, сортирующую сеть и сеть-ловушку (рис. 4.18). Сортирующая сеть выстраивает прибывающие ячейки в монотонную последовательность в зависимости от их адресации. Ячейки с одинаковой адресацией обнаруживаются сетью-ловушкой, и все, кроме одной, отправляются назад, на вход сортирующей сети. Для обеспечении целостности последовательности ячеек, ячейки, пришедшие в сортирующую сеть повторно, получают более высокий приоритет. Все ячейки, поступающие на вход баньянной сети, передаются по назначению без внутренней блокировки.
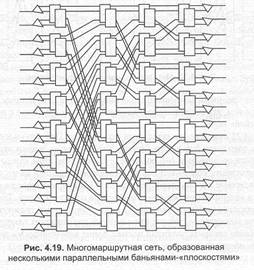
Многомаршрутная сеть может также быть образована несколькими параллельными баньянами-«плоскостями» (рис. 4.19). Такой принцип принято называть вертикальным расслоением. Все ячейки одного соединения проходят через одну и ту же плоскость, выбираемую в фазе установления соединения. Входящая ячейка направляется в нужную плоскость распределительным устройством. На выходе коммутатора статистический мультиплексор собирает ячейки из всех плоскостей. Показано, что даже две параллельные плоскости практически исключают блокировку. Добавление каскадов к данной сети-баньяну принято называть горизонтальны расслоением.
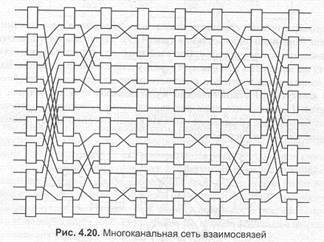
Многомаршрутная сеть взаимосвязей (рис. 4.20) получается при добавлении сети «базовой линии» с обращенной топологией к сети «базовой линии», представленной на рис. 4.15. Состоящая из коммутационных элементов bxb многомаршрутная сеть взаимосвязей NxN содержит 2xlnN/1nb каскадов. В данной сети существует N путей между произвольно выбранным входом и выходом. Путь от i-гo вход (i = 1, N) может выбираться произвольно до границы «начальной» сети. Далее, в сети с обращенной топологией путь определен однозначно.
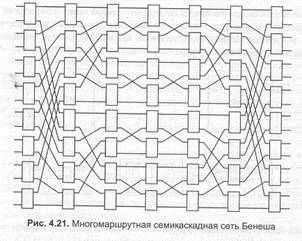
Сети Бенеша очень напоминают многомаршрутные сети взаимосвязей. Разница состоит в том, что последний каскад «прямой» сети совпадает с первым каскадом «обратной» сети.
На рис. 4.21 показана семикаскадная сеть Бенеша. При использовании коммутационных элементов bxb в сети Бенеша NxN — между любым входом и выходом возможна организация N / b различных путей. При этом каждый путь однозначно определяется содержащимся в нем элементом центрального каскада.
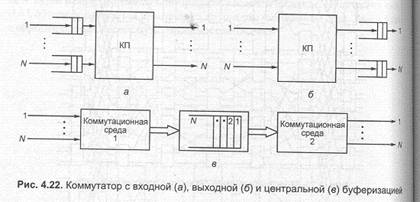
В соответствии с конкретной реализацией КП разрабатывается буферная архитектура и алгоритмы разрешения конфликтов и доступа к ней. Так, в коммутаторе, построенном на блокирующем КП, целесообразно буферизовать пакеты перед началом коммутации, так как нет гарантии прохождения пакета через КП за один КЦ. Такие системы получили наименование коммутаторов с входной буферизацией и обозначаются как системы IQ-типа (Input Queueing). Укрупненная блок-схема коммутатора с входной буферизацией приведена на рис. 4.22, а.
В коммутаторе, построенном на неблокирующем КП используют выходную буферизацию. Такие системы получили название коммутаторов с выходной буферизацией и обозначаются как системы OQ-типа (Output Queueing). Пример коммутатора с выходной буферизацией приведен на рис. 4.22, б.
Процедуры организации очередей на входе и на выходе обозначаются латинскими аббревиатурами IQ и OQ. Промежуточная или центральная буферизация, используемая обычно в пространственных коммутаторах или в коммутаторах с общей памятью соответственно, по сути означает реализацию IQ- и OQ-процесса или их сочетания. Коммутатор с центральной буферизацией приведен на рис. 4.22, в.
При входной буферизации (IQ) каждый вход располагает своим буфером, который позволяет ему хранить поступающие пакеты до того момента, пока логика арбитража не определит, что данный буфер может быть обслужен. Затем коммутационная среда передачи доставит пакеты АТМ из входных очередей на выход без внутренних столкновений. Логика арбитража, которая решает, какой входобслуживать, может варьироваться от простой, типа циклического опроса, до достаточно сложной, например, учитывающей уровни заполнения входных буферов. Коммутационные элементы с входной буферизацией страдают от так омываемых блокировок в голове очереди. Действительно, предположим, что пакет на входе i выбран для передачи на выход р. Если вход j также имеет пакет для передачи на выход р, этот пакет будет задерживаться вместе со всеми следующими за ним пакетами. Предположим, что второй пакет в очереди ко входу j направляется на выход q, для которого в настоящий момент во входных очереди пакетов не имеется. Но этот пакет не может быть обслужен, так как пакет, cтoящий в очереди перед ним, блокирует передачу.
При выходной буферизации принят подход, согласно которому пакеты, поступающие на различные входы и предназначенные для транспортирования на один и тот же выход, могут быть переданы (скоммутированы) в течение времени обслуживания одного пакета. Однако на выходе может быть обслужен только один паки, что вызывает соревнование между пакетами на выходе. Это может быть устранено организацией очередей. При выходной буферизации на каждом выходе располагается свой буфер, который позволяет хранить несколько пакетов, которые могут по. ступить в течение времени обслуживания одного пакета. Возможен случай одно. временного поступления на все входы пакетов, предназначенных к передаче а один и тот же выход. Для гарантии того, что ни один пакет не будет потерян в коммутационной среде передачи до того, как пакеты поступят в выходную очередь, передача пакетов должна производиться в N раз быстрее скорости на входах. Система же должна быть в состоянии записать N пакетов в очередь в течение времени обслуживания одного пакета. В коммутационной среде передачи наличия логики: арбитража не требуется, так как все пакеты могут быть транспортированы в свою выходную очередь. Управление выходными очередями основано на простой дисциплине «первым
пришел-первым обслужен» (FIFO), с тем чтобы гарантировать, что пакеты будут переданы в правильной последовательности.
При центральной буферизации буферы для организации очередей не выделяются отдельным входам или выходам, а разделяются между всеми входами и выходами. Ячейки, предназначенные для одного и того же выхода, могут находиться более чем в одном буфере. Внутри КП должен быть обеспечен механизм для определения, какие пакеты предназначены для каких выходов. Процедура чтения и записи из общей очереди не является простой дисциплиной «первым пришел — первым обслужен», так как пакеты для различных направлений перемешаны в общей очереди. В этом случае необходима достаточно сложная система управления памятью. Возможно применение следующих стратегий:
1. Случайный выбор: линия, обслуживаемая первой, выбирается случайно. Такая стратегия довольно проста в реализации и не требует больших дополнительных ресурсов.
2. Циклический выбор: буферы обслуживаются в циклическом порядке. Этот обход также просто реализуется.
3. Выбор, зависящий от состояния: первой обслуживается ячейка из самой длинной очереди. Для этого требуется механизм сравнения очередей в буферах.
4. Выбор, зависящий от задержки: глобальная FIFO-стратегия, которая требует рассмотрения всех буферов, питающих данный выход. Эта стратегия требует дополнительных возможностей для запоминания относительного порядка поступления «соревнующихся» ячеек.
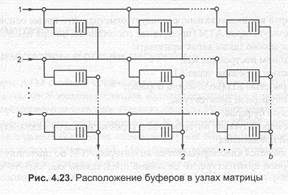
В случае промежуточной буферизации буферы могут располагаться в узлах матрицы ОСС (рис. 4.23) или внутри и между каскадами МСС. Эта схема позволяет избежать столкновения ячеек, идущих к одному выходу. Если более чем в одном буфере находятся ячейки, предназначенные для одного и того же выхода, логический контроль выбирает буфер, обслуживаемый первым. Эта система расположения буферов имеет недостаток, состоящий в том, что для каждого узла матрицы необходим свой буфер, и невозможно разделение буферов. Поэтому эффективность такой организации буферной памяти ниже, чем при организации очередей на выходе.
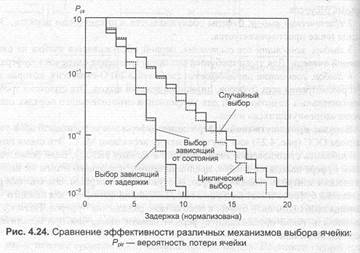
Сравнение эффективности различных механизмов выбора иллюстрирую рис. 4.24. Стратегия случайного выбора ведет к наибольшей вариации времени задержки. Незначительное улучшение дает циклический выбор. Оптимальную стратегию для минимизации времени задержки дает выбор, учитывающий время задержки ячеек в очереди. Минимальные потери ячеек достигаются реализацией стратегии выбора, зависящей от состояния очередей, когда первой обслуживают ячейка из самой длинной очереди. Эффективность этой стратегии в отношении минимизации вариации времени задержки чуть ниже, но все же вполне приемлема
Резюмируя все вышесказанное, следует отметить, что кроме основных характеристик коммутаторов АТМ (пропускная способность, потеря пакетов, задержки пакетов), их можно также характеризовать:
— принципом построения КП;
— скоростью передачи через КП;
— размерностью КП (количество портов);
— типом буферной архитектуры;
— емкостью буферов;
— типом используемых интерфейсов (скорость передачи в каналах);
— сферой применения.
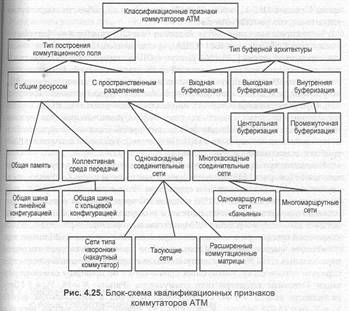
Что же касается классификации коммутаторов АТМ по принципу построения КП и буферной архитектуре, то ее можно представить так, как это показано ни рис. 4.25.
|
|
|
|
|
Дата добавления: 2015-06-25; Просмотров: 1633; Нарушение авторских прав?; Мы поможем в написании вашей работы!