КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Обратное распространение ошибки
|
|
|
|
Одним из самых распространенных алгоритмов обучения нейросетей прямого распространения является алгоритм обратного распространения ошибки ( BackPropagation, BP). Этот алгоритм был переоткрыт и популяризован в 1986 г. Румельхартом и МакКлелландом из группы по изучению параллельных распределенных процессов в Массачусетском технологическом институте. Здесь я хочу подробно изложить математическую суть алгоритма, так как очень часто в литературе ссылаются на какой-то факт или теорему, но никто не приводит его доказательства или источника. Честно говоря, то же самое относится к Теореме об отображении нейросетью любой функциональной зависимости, на которой основываются все попытки применить нейросети к моделированию реальных процессов. Я бы хотел посмотреть на ее доказательство, но еще нигде его не смог найти. Вот, чтобы у Вас не возникало такого чувства неудовлетворенности в полноте понимания работы нейросети, я решил привести этот алгоритм полностью, хотя честно сознаюсь, что не совсем понимаю его логику.
Итак, это алгоритм градиентного спуска, минимизирующий суммарную квадратичную ошибку:
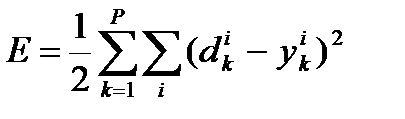 .
.
Здесь индекс i пробегает все выходы многослойной сети.
Основная идея ВР состоит в том, чтобы вычислять чувствительность ошибки сети к изменениям весов. Для этого нужно вычислить частные производные от ошибки по весам. Пусть обучающее множество состоит из Р образцов, и входы k-го образца обозначены через {xi k}. Вычисление частных производных осуществляется по правилу цепи: вес входа i-го нейрона, идущего от j-го нейрона, пересчитывается по формуле:
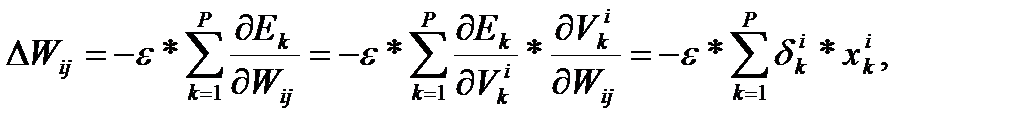
где e - длина шага в направлении, обратном к градиенту.
Если рассмотреть отдельно k-тый образец, то соответствующиее изменение весов равно:
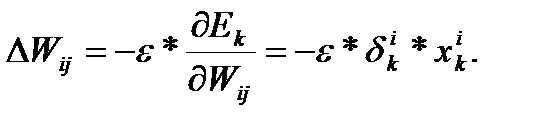
Множитель dik вычисляется через аналогичные множители из последующего слоя, и ошибка, таким образом, передается в обратном направлении.
Для выходных элементов получим:
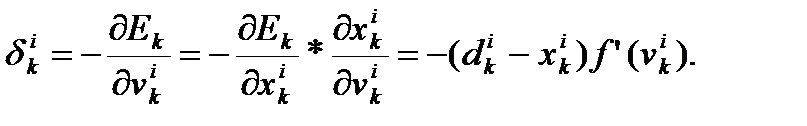
Для скрытых элементов множитель dik определяется так:
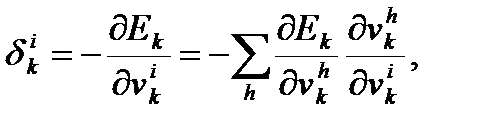
где индекс h пробегает номера всех нейронов, на которые воздействует i-ый нейрон.

Чтобы наглядно представить себе алгоритм обратного распространения ошибки, можно посмотреть следующий рисунок 7:
Рис. 7
|
|
|
|
|
Дата добавления: 2015-06-04; Просмотров: 406; Нарушение авторских прав?; Мы поможем в написании вашей работы!