КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Прототип системы OntoSeek 1 страница
|
|
|
|
Разработка и реализация прототипа системы «содержательного» доступа к WWW-ресурсам OntoSeek - результат 2-летней работы, выполненной в кооперации Corinto (Consorzio di Ricerca Nazionale Tecnologia Oggetti - National Research Consortium for Object Technology) и Ladseb-CNR (National Research Council - Institute of Systems Science and Biomedical Engineering), как части проекта по поиску и повторному использованию программных компонентов [Guarino, et al., 1999].
Система OntoSeek разработана для содержательного извлечения информации из доступных в режиме on-line «желтых» страниц (yellow pages) и каталогов. В рамках системы совместно используются механизмы поиска по содержанию, управляемые соответствующей онтологией (ontology-driven content-matching mechanism), и достаточно мощный формализм представления.
При создании OntoSeek были приняты следующие проектные решения:
• использование ограниченного числа ЕЯ-терминов для точного описания ресурсов на фазе кодирования;
• полная «терминологическая свобода» в запросах за счет управляемого онтологией семантического отображения их на описания ресурсов;
• интерактивное ассистирование пользователю в процессе формулировки запроса, его обобщения и/или конкретизации, а также приняты во внимание:
♦ текущее состояние исследований в области Интернет-архитектур;
♦ необходимость достижения высокой точности и приемлемой эффективности на больших массивах данных;
♦ важность хорошей масштабируемости и портабельности принимаемых решений.
Система работает как с гомогенными, так и с гетерогенными каталогами продуктов. Понятно, что второй вариант сложнее. Поэтому в системе OntoSeek для представления запросов и описания ресурсов используется модификация простых концептуальных графов Дж. Совы [Sowa, 1984], которые обладают существенно более мощными выразительными возможностями и гибкостью по сравнению с обычно используемыми списками типа «атрибут-значение». Для концептуальных графов проблема контекстного отождествления редуцируется до управляемого онтологией поиска в графе. При этом узлы и дуги сопоставимы, если онтология «показывает», что между ними существует заданное отношение. Вместе с тем, поскольку система базируется на использовании лингвистической онтологии, узлы концептуального графа должны быть привязаны к соответствующим лексическим единицам, причем для этого должны выполняться определенные семантические ограничения.
На этапе планирования проекта вместо разработки собственной лингвистической онтологии были проанализированы доступные Интернет-ресурсы и выбрана онтология Sensus [Knight et al., 1994], которая обладает простой таксономической структурой, имеет объем около 50 000 узлов, в основном выделенных из тезауруса WordNet [Beckwith et al., 1990], а также доступна для исследовательских целей в свободном режиме.
Функциональная структура системы OntoSeek представлена на рис. 9.10.
На фазе кодирования описание ресурсов конвертируется в концептуальный граф. Для этого «поверхностные» узлы и дуги, отмеченные пользователем, с помощью лексического интерфейса трансформируются в смыслы, заданные в словаре. Таким образом, «граф слов» транслируется в «граф смыслов», причем каждому понятию последнего сопоставляется соответствующий узел онтологии. После семантической валидации концептуального графа на основе использования онтологии он запоминается в БД.
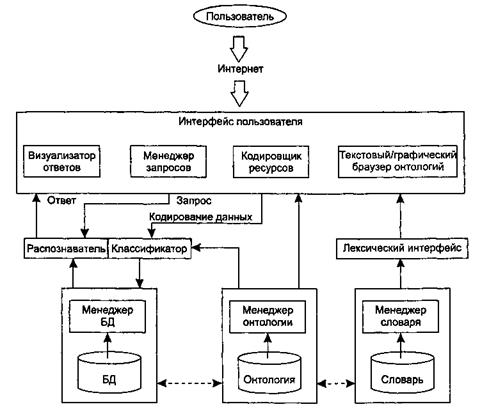
Рис. 9.10. Функциональная структура системы OntoSeek
Наиболее интересным моментом этапа кодирования ресурсов в системе OntoSeek является формализм представления помеченных концептуальных графов (ПКГ), который базируется на том, что заданы словари существительных и глаголов, а собственно ПКГ определяется как связный ориентированный граф, удовлетворяющий следующим синтаксическим ограничениям:
• Дуги могут быть помечены только существительными из словаря (любой граф, содержащий дугу, помеченную транзитивной конструкцией вида [<URLl>man] → (love) → [women], может быть конвертирован в базисный ПКГ вида [<URLl>man] ← (agent) ← [love] → (patient) → [women]).
• В общем случае узлы помечаются строками вида concept [instance], где concept существительное или глагол из словаря, а необязательная ссылка: instance - управляющий идентификатор.
• Для каждого графа существует в точности один узел, называемый «головой». Этот узел маркируется URL в угловых скобках, идентифицирующим файл описания ресурса, который описывает данный граф, и маркерной строки, представляющей понятие онтологии.
Понятно, что прежде, чем использовать этот граф, должна быть устранена полисемия, что может позволить однозначно отразить существующие метки в понятия онтологии. После выполнения этой процедуры семантическая интерпретация ПКГ происходит следующим образом:
• каждый узел, помеченный «словом» А, представляет класс экземпляров соответствующего концепта. При наличии в описании идентификатора экземпляра узел определяет синглетон, содержащий этот экземпляр. Если А - глагол, узел фиксирует его номинализацию (например, узел с пометкой «love» определяет класс событий «любить»);
• каждая дуга с пометкой С из узла А в узел В определяет соответствующее непустое отношение;
• в целом граф с «головой» А и URL U определяют класс экземпляров А, описываемых ресурсом, помеченным U.
Процесс поиска осуществляется следующим образом. Пользователь представляет свой запрос тоже в виде концептуального графа, который после устранения лексической неоднозначности и семантической валидации передается компоненте отождествления, работающей с БД. Здесь ищутся графы, удовлетворяющие запросу и ограничениям, заданным в онтологии, после чего ответ представляется пользователю в виде HTML-отчета.
Семантика графа запроса и процедура его построения аналогичны рассмотренной выше процедуре кодирования ресурсов, но имеет следующие отличия:
• на месте URL может быть задана переменная;
• переменными может быть помечено произвольное число узлов.
Так, например, запрос вида [<Х> саr] → (part) → [radio] вернет множество URL на документы, описывающие автомобили с радиоприемниками в качестве части, а запрос вида [саr] → (part) → [<Х> radio] - множество URL на документы, описывающие радиоприемник как часть автомобиля. И более того, композиция этих запросов вида [<Х> саr] → (part) → [<Y> radio] может быть использована для получения документов обоих типов.
Таким образом, предполагается, что граф запроса Q отождествляется с графом описания ресурса R, если:
• Q изоморфен подграфу графа R;
• пометки графа R соответствуют пометкам графа Q;
• «голова» графа R соответствует узлу, помеченному переменной в графе Q.
Последнее условие необходимо, если мы хотим «сосредоточиться» на ресурсах, соответствующих запросу в точности.
Реализация системы OntoSeek выполнена в парадигме «клиент-сервер». Архитектурным ядром ее является сервер онтологий, обеспечивающий для приложений интерфейсы доступа и/или манипулирования данными модели онтологии, а также поддержки БД концептуальных графов. Заметим, что последняя может строиться и пополняться не только в интерактивном режиме, но и за счет скомпилированных описаний ПКГ, представленных на языке XML. Компонента БД в системе OntoSeek выделена в отдельный блок, что позволяет легко заменить при необходимости используемую СУБД.
Проект начался зимой 1996 г. - на заре эры языка Java. Поэтому прототип был реализован на языке C++. В настоящее время авторы предполагают провести реинжиниринг системы на основе использования новейших Интернет-технологий.
Таким образом, использование онтологий для интеллектуальной работы с Интернет-ресурсами является в настоящее время «горячей» точкой исследований и практических применений.
Специалистам в этой области хорошо известны Интернет-сайты организаций и проектов, связанных с созданием и использованием онтологий, но даже у них при выборе онтологии, «подходящей» для конкретного приложения, возникают определенные проблемы. Основные из них: отсутствие стандартного набора свойств, характеризующих онтологию с точки зрения ее пользователя; уникальность логической структуры представления релевантной информации на каждом «онтологическом» сайте; высокая трудоемкость поиска подходящей онтологии.
Учитывая вышесказанное, в заключение данного параграфа рассмотрим пример интеллектуального агента, который демонстрирует онтологический подход к поиску на Web и выбору для использования собственно онтологий.
(ONTO)2 - агент поиска и выбора онтологий
Целью разработки интеллектуального WWW-брокера выбора онтологий на Web [Vega et al, 1999] было решение проблемы ассистирования при выборе онтологий. Для этого потребовалось сформировать перечень свойств, которые позволяют охарактеризовать онтологию с точки зрения ее будущего пользователя и предложить единую логическую структуру соответствующих описаний; разработать специальную ссылочную онтологию (Reference Ontology), в рамках которой представлены описания существующих на Web онтологий; реализовать интеллектуального агента (ONTO)2, использующего ссылочную онтологию в качестве источника знаний для поиска онтологий, удовлетворяющих заданному множеству ограничений.
Для решения первой из перечисленных задач авторы (ONTO)2 детально проанализировали онтологии, представленные на Web, и построили таксономию свойств, используемых для описания онтологий (табл. 9.2). Для удобства дальнейшего использования все свойства сгруппированы в категории идентификации, описания и функциональности.
Как следует из приведенной таксономии, идентификация дает информацию об онтологии, как таковой, ее разработчиках и дистрибьюторах; описание - общую информацию, аннотацию онтологии, некоторые детали проектирования и реализации, требования к аппаратуре и программному обеспечению, ценовые характеристики и перечень применений; функциональность - представление о том, как использовать онтологию в приложениях.
При решении задачи разработки ссылочной онтологии авторы (ONTO)2 использовали уже обсуждавшуюся выше технологию METHONTOLOGY и инструментарий ODE [Blazquez et al., 1998]. При этом, в соответствии с общими тенденциями по созданию разделяемых онтологий и, по-видимому, в силу того, что один из авторов обсуждаемой работы (Gomez-Perez) является провайдер-агентом международного проекта по построению разделяемых баз знаний [Benjamins et al, 1998], Reference Ontology была «имплантирована» в онтологию Product инициативы (КА)2.
В качестве источников знаний для построения ссылочной онтологии была использована уже обсуждавшаяся таксономия свойств, концептуальная модель (КА)2 и свойства, выделенные в рамках разработки онтологии исследовательских тем (Research-Topic) инициативы (КА)2. Критерии, которые применялись при имплантации ссылочной онтологии в онтологию (КА)2, - следующие:
• модульность (онтология должна была быть модульной, чтобы обеспечить гибкость и различные варианты использования);
• специализация (концепты определялись таким образом, чтобы обеспечить их классификацию по общим свойствам и гарантировать наследование таких свойств);
• разнообразие (знания представлялись в онтологии таким образом, чтобы использовать преимущества множественного наследования и облегчить добавление новых концептов);
• минимизация семантических расстояний (аналогичные концепты группировались и представлялись как подклассы одного класса на базе одних и тех же примитивов);
• максимизация связей между таксономиями;
• стандартизация имен (везде, где это было возможно, для именования отношений использовалась конкатенация имен концептов, которые ими связывались).
Анализ концептуальной модели (КА)2 онтологии с точки зрения перечисленных выше критериев и ссылочной онтологии показал, что:
• некоторые важные классы отсутствуют (например, классы Server и Languages, которые должны быть подклассами класса Computer-Support в онтологии Product);
• некоторые важные отношения опущены (например, отношение Distributed-by между понятиями продукта и организации);
• некоторые важные свойства не представлены (например, Research-Topic-Web-pages, Type-of-Ontology и некоторые другие).
Таблица 9.2. Таксономия свойств, используемых для описания онтологий
| Основные характеристики | ||
| Идентификация Описание Функцио- нальность | Онтологии Разработчиков Дистрибьюторов Общая информация Обзорная информация Информация о проектировании Требования ценовые Использование | Имя, сайт-сервер, сайт-зеркало, Web-страницы, доступность FAQ, ЕЯ-описание, дата окончания разработки ФИО, Web-страницы, e-mail, контактное лицо, телефон, факс, почтовый адрес ФИО, Web-страницы, e-mail, контактное лицо, телефон, факс, почтовый адрес Тип онтологии; предметная область; назначение; онтологические обязательства; список концептов верхнего уровня; статус реализации; наличие on-line и «бумажной» документации Количество концептов, представляющих классы; количество концептов, представляющих экземпляры; количество аксиом; количество отношений; количество функций; количество классов концептов на первом, втором и третьем уровнях; количество классов на листьях; среднее значение фактора ветвления; среднее значение фактора глубины; максимальная глубина Методология разработки; формальный уровень методологии; подход к разработке; уровень формализации спецификации; типы источников знаний; достоверность источников знаний; техники приобретения знаний; формализм; список онтологии, с которыми осуществлена интеграция; перечень языков, в рамках которых доступна онтология К аппаратуре; программному обеспечению цена; стоимость сопровождения; оценка характеристики стоимости необходимой аппаратуры; оценка стоимости необходимого программного обеспечения Количество приложений; список основных приложений Описание использованных инструментальных средств; качество документации; обучающие курсы; on-line помощь; руководства по использованию; возможность модульного использования; возможность добавления новых знаний |
Поэтому был проведен реинжиниринг (КА)2 онтологии, который позволил расширить ее новыми концептами, отношениями и свойствами, с одной стороны, и специализировать уже представленные знания таким образом, чтобы использовать их для сравнения различных онтологий.
Для реализации интеллектуальных WWW-брокеров поиска онтологий была предложена архитектура Onto Agent, представленная на рис. 9.11.
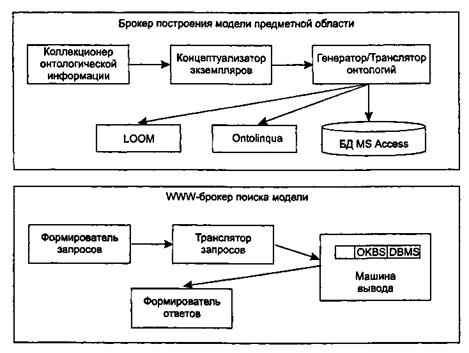
Рис. 9.11. Архитектура Onto Agent
В рамках данной архитектуры выделяются брокер построения модели предметной области (Domain Model Builder Broker) и WWW-брокер поиска модели (WWW Domain Model Retrieval Broker).
Первый из них ориентирован на формирование концептуальной структуры онтологий, которые будут в поле зрения будущей экспертизы.
Этот модуль включает:
• Коллекционера онтологической информации (Ontology Information Collector) - WWW-интерфейс, ориентированный на сбор информации от распределенных по сети агентов (программных агентов и собственно пользователей).
• Концептуализатора экземпляров (An Instance Conceptualizer) - преобразователь данных от WWW-интерфейса в экземпляр онтологии, специфицированный на уровне формализма представления знаний.
• Генератора/Транслятора онтологий (Ontology Generator/Translator) - компоненты отображения концептуального представления онтологий на целевые языки реализации, что обеспечивает доступ к ним из удаленных приложений.
Целью второго модуля является обеспечение доступа к накопленной информации и представление ее наилучшим для пользователя образом. Этот модуль включает:
• Формирователя запросов (A Query Builder) - компоненту построения запросов с использованием словаря брокера и при необходимости переформулирования и/или уточнения запросов пользователя.
• Транслятор запросов (A Query Translator) - преобразователя запроса в представление, совместимое с языком реализации онтологии.
• Машину вывода (An Inference Engine) - блок поиска ответа на запрос.
• Формирователя ответов (An Answer Builder) - компоненту, которая служит для представления информации, найденной машиной вывода.
По сути дела, рассмотренные выше компоненты составляют технологию построения WWW-брокеров для поиска информации на основе онтологий. А примером ее использования является интеллектуальный (ONTO)2 агент. Его брокер построения модели предметной области работает со ссылочной онтологией, а входной запрос строится как соответствующая HTML-форма. Брокер поиска ответов реализован в настоящее время как Java-апплет и как автономное Java-приложение. Результаты поиска онтологий, удовлетворяющих запросу, возвращаются пользователю в виде HTML-формы.
Оценивая представленный подход в целом, можно отметить, что он хорошо коррелирует по своим идеям и целям с уже обсуждавшейся системой Ontobroker. Однако в случае (ONTO)2 агента для хранения формализаций онтологий используется база данных, а для поиска - стандартные средства на основе SQL. Самостоятельную ценность данного проекта представляет ссылочная онтология, которая может использоваться не только для целей поиска, но и для стандартизации описаний онтологий вообще.
Все вышесказанное показывает, что использование агентов и особенно интеллектуальных агентов при сборе, поиске и анализе информации имеет ряд преимуществ, основные из которых сводятся к следующему [Pagina H., 1996]:
• они могут обеспечить пользователю доступ ко всем Интернет-сервисам и сетевым протоколам;
• отдельный агент может быть занят одной или несколькими задачами параллельно;
• преимущества агентов в том, что они могут осуществлять поиск по заданию пользователя после его отключения от сети;
• мобильность (если она присутствует) позволяет агентам искать информацию сразу на сервере, что увеличивает скорость и точность поиска, уменьшая загрузку сети;
• они могут создавать собственную базу информационных ресурсов, которая обновляется и расширяется с каждым поиском;
• возможность агентов сотрудничать друг с другом позволяет использовать накопленный опыт;
• агенты могут использовать модель пользователя для корректировки и уточнения запросов;
• они могут адаптироваться под предпочтения и желания пользователя и, изучив их, искать полезную информацию заранее;
• агенты способны искать информацию, учитывая контекст. Они могут вывести этот контекст из запроса, например, построив модель мира пользователя;
• агенты могут искать информацию интеллектуально, например, используя словари, тезаурусы и онтологии, а также средства вывода релевантной информации, не представленной явно ни в запросе, ни в найденных документах.
Именно поэтому с применением и развитием агентных технологий на основе методов и средств искусственного интеллекта связываются самые серьезные перспективы перехода от пространств данных к пространствам знаний в глобальных и локальных сетях.
Заключение
Итак, уважаемый читатель, вы завершаете чтение книги по базам знаний интеллектуальных систем. Авторы отдают себе отчет в том, что за ее рамками остались целые континенты планеты Искусственный Интеллект, которые еще ждут своих исследователей, толкователей, методистов и, конечно, читателей. Но дорогу осилит идущий... И, наверное, именно это, а также понимание, что в данный момент в нашей стране практически нет литературы, которая не то чтобы закрыла тему, но хотя бы зафиксировала полученные в одном из ее важнейших разделов результаты, подвигло нас на работу по написанию этой книги.
Материал данного учебника показывает, что в настоящее время в области баз знаний интеллектуальных систем уже имеется серьезный теоретический базис, существует достаточно широкий спектр соответствующих методов и технологий разработки. Многие из них поддержаны адекватным программным инструментарием. И основная цель авторов была в том, чтобы сделать эту информацию достоянием читателей. Понятно, что в силу многих причин, в частности ограничений на объем издания, дать полномасштабное и логически замкнутое описание теории, методов проектирования и средств реализации баз знаний, а также соответствующих систем, основанных на знаниях, в одной книге практически невозможно. Отчасти поэтому список рекомендованной литературы у нас значительно шире, чем это обычно бывает в учебниках. Кроме того, в списке литературы достаточно много ссылок на релевантные тематике Интернет-ресурсы, что, по нашему мнению, должно привить читателю вкус к самостоятельному плаванию в океанах уже (или еще) доступной в сети информации.
Вместе с тем, авторы надеются, что читатели этой книги не будут воспринимать представленные в ней материалы как истину в последней инстанции, но будут относиться к ним творчески, а иногда и критически. Ведь не секрет, что для построения и использования баз знаний, на которых основываются современные интеллектуальные системы, требуются исследовательские коллективы, работающие вместе долго и имеющие опыт разработки такого рода систем. Для получения действительно хороших результатов необходимы дорогостоящие людские и материальные ресурсы - специалисты, лицензионные инструментарии, документация. Кроме того, разработка их достаточно трудоемкий (годы) и дорогостоящий (десятки, если не сотни тыс. долларов) процесс. Вот почему в настоящее время действующие интеллектуальные системы ориентированы в основном на поддержку работы постоянно работающих групп пользователей для достаточно специализированных задач. Следует отметить и то, что в настоящее время почти нет действительно интеллектуальных систем, удобных для работы широкого круга пользователей в сети Интернет.
Таким образом, разработка теории, методов и технологий представления и использования знаний остается актуальной задачей для дальнейшего развития интеллектуальных систем. Особую актуальность, по нашему мнению, приобретают на современном этапе развития науки и общества в целом Интернет-ориентированные технологии и распределенный искусственный интеллект. Уже сейчас ясно, что применение систем, основанных на знаниях, компонентом которых являются, например, онтологии, а реализация базируется на мультиагентных технологиях, должно привести к рассмотрению и использованию Всемирной паутины как организованного и структурированного пространства знаний.
И в заключение, авторы надеются, что их собственный скромный вклад в методологию, технологию и программные средства создания баз знаний, также отраженный в данной книге, позволит молодым специалистам в области искусственного интеллекта пойти дальше по тернистому пути этой молодой науки, которой так хочется стать индустрией!
Литература
1. Агеев В. Н., 1994. Примеры гипертекстовых и гипермедиа систем (обзор) // Компьютерные технологии в высшем образовании: Сб. статей. М.: Изд-во МГУ. С. 225-229.
2. Аверкин А. Н., Батыршин И. 3., Блишун А. Ф., Силов В. Б., Тарасов В. Б., 1986. Нечеткие множества в моделях управления и искусственного интеллекта // Под ред. Д. А. Доспелова. М.: Наука.
3. Алахвердов В. М., 1986. Когнитивные стили в контурах процесса познания. Когнитивные стили // Под ред. В. Колги. — Таллинн. С. 12-23.
4. Александров Е. А., 1975. Основы теории эвристических решений. М.: Наука.
5. Алексеева И. А., Воинов А. В., Сейсян А. Р., Эткинд А. М., 1989. Психосемантическая реконструкция картины мира подростков, употреблявших токсические вещества // Сб. Конструктивная психология — новое направление развития психологической науки. Под ред. А. Г. Копытова. Красноярский гос. ун-т.
С. 36-41.
6. Алексеевская М. А., Недоступ А. В., 1988. Диагностические игры в медицинских задачах. Вопросы кибернетики // Задачи медицинской диагностики и прогнозирования с точки зрения врача. № 112. С. 128-139.
7. Амамия М., Танака Ю., 1993. Архитектура ЭВМ и ИИ. М.: Мир.
8. Анастази А., 1982. Психологическое тестирование. Т. 1. М. С. 96-162.
9. Андриенко Г. Л., Андриенко Н. В., 1992. Игровые процедуры сопоставления в инженерии знаний // Сборник трудов III конференции по искусственному интеллекту. Тверь. С. 93-96.
10. Аншаков О. М., Скворцов Д. П., Финн Д. К, 1986. Логические средства экспертных систем типа ДСМ // Семиотика и информатика. Вып. 28. С. 5-15.
11. Апресян Ю. Д., 1977. Экспериментальное исследование семантики русского языка. М.: Наука.
12. Апресян Ю.Д., 1974. Лексическая семантика. Семиотические средства языка. М.: Наука.
13. Арбиб М., 1975. Алгебраическая теория автоматов. М.: Статистика.
14. Аткинсон Р., 1980. Человеческая память и процесс обучения // Пер. с англ. М.: Прогресс.
15. Байдун В. В., Бунин А. И., 1990. Средства представления и обработки знаний в системе FRL/PS // Всесоюзная конференция по искусственному интеллекту: тез. докл. Т. 1. Минск. С. 66-71.
16. Бахтин М. М., 1975. Вопросы литературы и эстетики: Исследования разных лет. М.: Художественная литература.
17. Белнап Н., Стил Т., 1981. Логика вопросов и ответов. М.: Прогресс.
18. Берков В. Ф., 1972. Вопрос как форма мысли. Минск, Изд-во БГУ.
19. Берн Э., 1988. Игры, в которые играют люди. Люди, которые играют в игры// Пер. с англ. М.: Прогресс.
20. Бойкачев К. К., Конева И. Г., Новик И. 3., 1994. «Сценарий» — инструмент визуальной разработки компьютерных программ // Компьютерные технологии в высшем образовании: Сб. статей. М.: Изд-во МГУ. С. 167-178.
21. Борисов А. Н., Федоров И. П., Архипов И. Ф., 1991. Приобретение знаний для интеллектуальных систем. Рижский технический университет.
22. Борисова Н. В., Соловьева А. А. и др., 1988. Деловая игра «Методика конструирования деловой игры». М.: ИПКИР.
23. Брунер Дж., 1971. Исследование развития познавательной деятельности // Пер. с англ. М.: Педагогика.
24. Бурков В. И. и др., 1980. Деловые игры в принятии управленческих решений. М.: МИСИС.
25. Брукс Ф. П., 1979. Как проектируются и создаются программные комплексы. Мифический человеко-месяц: очерки по системному программированию. М.: Наука.
26. Буч Г., 1992. Объектно-ориентированное проектирование с примерами применения. М.: Конкорд.
27. Веккер Л. М., 1976. Психические процессы // В 3-х томах. Т. 2. Л.: ЛГУ.
28. Величковский Б. М., 1982. Современная когнитивная психология. М.: МГУ.
29. Величковский Б. М., Капица М. С, 1987. Психологические проблемы изучения интеллекта // Интеллектуальные процессы и их моделирование. М.: Наука. С. 120-141.
30. Вертгеймер М., 1987. Продуктивное мышление // Пер с нем. М.: Прогресс.
31. Винер Н., 1958. Кибернетика или управление и связь в животном и машине. М.: Сов. радио.
32. Виноград Т., 1976. Программа, понимающая естественный язык // Пер. с англ. М.: Мир.
33. Воинов А., Гаврилова Т., 1994. Инженерия знаний и психосемантика: Об одном подходе к выявлению глубинных знаний // Известия РАН Техническая кибернетика. № 5. С. 5-13
34. Волков А. М., Ломнев B.C., 1989. Классификация способов извлечения опыта экспертов // Известия АН СССР. Техническая кибернетика. № 5. С. 34-45.
35. Вольфенгаген В. Э., Воскресенская О. В., Горбанев Ю. Г., 1979. Система представления знаний с использованием семантических сетей // Вопросы кибернетики: Интеллектуальные банки данных. М.: АН СССР. С. 49-69.
36. Гаврилова Т. А., 1984. Представление знаний в экспертной диагностической системе АВТАНТЕСТ // Изв. АН СССР. Техническая кибернетика. № 5. С. 165-173.
37. Гаврилова Т. А., 1988. Как стать инженером по знаниям // Доклад на Всесоюзной конференции по искусственному интеллекту. М.: ВИНИТИ. С. 332-338.
38. Гаврилова Т. А., Минкова С. П., Карапетян Г. С, 1988. Экспертные системы для оценки качества деятельности летного состава // Тез. докладов научно-практической школы-семинара «Программное обеспечение и индустриальная технология интеллектуализации разработки и применения ЭВМ». — Ростов н/Д, ВНИИПС. С. 23-25.
|
|
|
|
|
Дата добавления: 2015-07-02; Просмотров: 649; Нарушение авторских прав?; Мы поможем в написании вашей работы!