КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Метод Хаффмена
1. Буквы алфавита выписываются столбцом в порядке убывания вероятностей.
2. Находится сумма вероятностей последних двух букв.
3. Вероятности букв, не участвующих в объединении, и полученная суммарная вероятность снова располагаются столбцом в порядке убывания.
Второй и третий этапы повторяются до тех пор, пока суммарная вероятность не будет равна единице.
Построение кода Хаффмена для ансамбля из 8 букв приведено в Табл. 2.
Таблица 1
| Буквы | 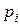
| Деление букв на группы | Код Шеннона-Фано |
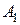
| 0,20 | ||
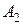
| 0,20 | ||
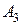
| 0,15 | ||
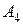
| 0,13 | ||

| 0,12 | ||
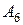
| 0,10 | ||
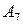
| 0,07 | ||

| 0,03 |
Кодовое дерево строится следующим образом (Табл. 3). Сначала находятся буквы с наименьшими вероятностями 0,07 () и 0,03 (), а затем от них проводятся линии к точке, изображающей «укрупненный» символ с суммарной вероятностью 0,10. На рисунке эта процедура обозначена цифрой I. Затем берутся две наименьшие вероятности со значением 0,10 и получают новый «укрупненный» символ с вероятностью 0,20 (процедура II). Теперь наименьшие вероятности имеют символы 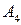 (0,13) и
(0,13) и 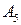 (0,12). Соединяя их линиями формируют новый символ с суммарной вероятностью 0,25 (процедура III).
(0,12). Соединяя их линиями формируют новый символ с суммарной вероятностью 0,25 (процедура III).
Эти процедуры повторяются до тех пор, пока линии от основных и «укрупненных» символов не соединятся в точке с суммарной вероятностью, равной 1. Верхнюю линию обозначают цифрой «1», а нижнюю «0». Любая кодова комбинация представляет собой последовательность «1» и «0», которые встречаются на пути от вершины дерева с вероятностью 1 к точке, изображающей нужную букву.
Сравнение рассмотренных методик построения эффективных кодов позволяет сделать вывод, что методика Хаффмена более удобна для практического использования. В общем случае код Хаффмена экономичнее кода Шеннона-Фано.
Нетрудно заметить, что сокращение средней длины кодовой комбинации эффективного кода по сравнению с равномерными кодами достигается благодаря присвоению более вероятным буквам коротких кодовых комбинаций, а менее вероятным буквам – более длинных кодовых комбинаций. Таким образом, эффективность рассматриваемых кодов связана с различием в числе символов кодовых комбинаций. Это приводит к определенным трудностям при декодировании. Конечно, для различия кодовых комбинаций можно ставить разделительный символ, но при этом существенно снижается эффект, который достигается использованием неравномерных кодов, так как средняя длина кодовой комбинации, по существу, увеличивается на одни символ. Более разумным является обеспечение однозначного декодирования без введения разделительных символов. Для этого эффективный код строят так, чтобы ни одна комбинация кода не совпадала с первыми символами более длинной кодовой комбинации. Коды, удовлетворяющие этому условию, называются префиксными.
Коды, представляющие первичные алфавиты с неравновероятными символами, имеющие минимальную среднюю длину кодового слова, называются оптимальными неравномерными кодами (ОНК).
Максимально эффективными будут те ОНК, у которых энтропия дискретного источника H(A) численно равна среднему числу двоичных символов на букву 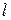 :
:
 (4)
(4)
или с учетом (1) и (3)
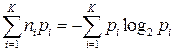 (5)
(5)
Очевидно, что это равенство будет иметь место только тогда, когда
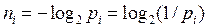 (6)
(6)
Величина точно равна H(A), если вероятности 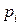 представляют собой целочисленные отрицательные степени двойки. Если это не выполняется, то
представляют собой целочисленные отрицательные степени двойки. Если это не выполняется, то 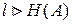 и согласно основной теореме кодирования Шеннона для каналов без шумов средняя длина кодовой комбинации приближается к энтропии источника сообщений по мере укрупнения кодируемых блоков.
и согласно основной теореме кодирования Шеннона для каналов без шумов средняя длина кодовой комбинации приближается к энтропии источника сообщений по мере укрупнения кодируемых блоков.
Для оценки эффективности ОНК предназначены следующие характеристики.
1. Коэффициент статического сжатия.
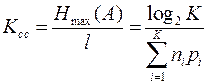 (7)
(7)
Он характеризует уменьшение количества двоичных символов на букву алфавита при применении ОНК по сравнению с применением методов нестатистического кодирования.
2. Коэффициент относительной эффективности.
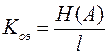 (8)
(8)
Этот коэффициент показывает, насколько устраняется статистическая избыточность передаваемого сообщения.
Методы устранения избыточности позволяют эффективно использовать пропускную способность канала связи. Они полезны также в тех случаях, когда требуется хранить большой объем информации в различных запоминающих устройствах. Экономия в пропускной способности канала или в объеме запоминающего устройства приводит к снижению стоимости, сокращению размеров и веса аппаратуры. Рассмотренные методы кодирования получили применение при передаче факсимильных сообщений.
|
|
Дата добавления: 2015-06-27; Просмотров: 350; Нарушение авторских прав?; Мы поможем в написании вашей работы!