КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Ключевые положения
|
|
|
|
Цель работы
ИССЛЕДОВАНИЕ АЛГОРИТМОВ ЭФФЕКТИВНОГО КОДИРОВАНИЯ ИСТОЧНИКОВ ДИСКРЕТНЫХ СООБЩЕНИЙ
Методические указания
к выполнению лабораторной работы по дисциплинам
«Информационные радиосистемы»,
«Теория связи»
Составитель преп. Балута М.Ю.
Редактор проф. Иващенко П.В.
Одесса – 2012
1.1 Изучение информационных характеристик источников дискретных сообщений и принципов эффективного кодирования сообщений.
1.2 Изучение алгоритмов и исследование особенностей эффективного кодирования Хаффмана и Шеннона-Фано.
2.1 Количественная мера информации
В основу определения количественной меры информации в теории и технике связи положены вероятностные характеристики сообщений. Количество информации I (a) в сообщении a с вероятностью его появления P (a) определяется
I (a) = 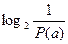 = –log2 P (a). (1)
= –log2 P (a). (1)
Логарифмическая мера обладает свойством аддитивности (количество информации, которое содержится в нескольких независимых сообщениях, равно сумме количеств информации, содержащихся в каждом сообщении). Т.к. 0 < P (a) 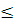 1, то величина I (a) является неотрицательной и конечной. Если P (a) = 1, то количество информации равно нулю (сообщение об известном событии никакой информации не несет).
1, то величина I (a) является неотрицательной и конечной. Если P (a) = 1, то количество информации равно нулю (сообщение об известном событии никакой информации не несет).
Информация измеряется в двоичных единицах (дв. ед.) или битах (1 дв.ед. – это количество информации в сообщении, вероятность которого P (a) = 0,5).
2.2 Информационные харакетристики источников сообщений.
Источник дискретных сообщений выдает сообщения знаками. Знаки составляют алфавит источника. Число различных знаков называют объемом алфавита МА. Зная вероятности знаков, по формуле (1) можно определить количество информации, содержащейся в каждом из знаков.
Знание количества информации в отдельных знаках недостаточны для решения задач передачи информации по каналам связи, требуется оценивать информационные свойства источника сообщений в целом. Одной из важных характеристик источника является его энтропия.
Энтропия источника H (A) – это среднее количество информации в одном знаке источника А. Если знаки независимы, то среднее количество информации определяется как математическое ожидание количества информации в одном знаке
H (A) = 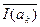 =
= 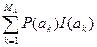 = –
= – 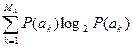 . (2)
. (2)
Энтропия выражает меру неопределенности состояния источника до выдачи сообщения, она является информационной характеристикой источника.
Из выражения (2) следует, что энтропия неотрицательна. Энтропия равна нулю только тогда, когда вероятность одного из знаков равна 1, а остальные имеют нулевую вероятность. Энтропия достигает максимального значения в случае, когда все знаки равновероятны и независимы:
H max(A) = log2 MA. (3)
В общем случае для энтропии справедливо выражение H (A) £ log2 MA.
Очень часто 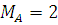 . Тогда H max(A) = 1 дв. ед. Следовательно, при передаче информации двоичными символами, каждый двоичный символ не может переносить более чем 1 дв. ед. информации.
. Тогда H max(A) = 1 дв. ед. Следовательно, при передаче информации двоичными символами, каждый двоичный символ не может переносить более чем 1 дв. ед. информации.
Важной характеристикой источника является его избыточность. Избыточность – это свойство источника выдавать информацию большим числом знаков, нежели можно было бы. Источник использовал бы минимальное число знаков для выдачи некоторого количества информации, если бы энтропия была максимальной, а у реальных источников H (A) < H max(A). Следовательно, источник использует избыточное число знаков для выдачи информации.
Основные причины избыточности:
- различные вероятности отдельных знаков;
- наличие статистических связей между знаками сообщений.
Количественно избыточность источника оценивают коэффициентом избыточности
K изб = 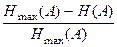 = 1 –
= 1 – 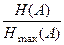 . (4)
. (4)
Производительность источника R и, бит/с – это среднее количество информации, которое выдает источник в единицу времени
R и = 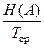 , (5)
, (5)
где T ср – средняя длительность одного знака, определяемая как
T ср = 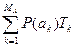 , (6)
, (6)
где Tk – длительность k -го знака.
2.3 Эффективное кодирование сообщений.
При кодировании сообщений источника каждому знаку ставится в соответствие кодовая комбинация из двоичных символов (рис. 1).
 |
Кодирование и декодирования выполняются на основе кода (кодовой таблицы). Широко распространены стандартные (примитивные) коды (МТК-2, ASCII и др.). Это равномерные коды. Их длина n – это минимальное целое, удовлетворяющее условию n ³ log2 MA.
В теории информации ставится и успешно решается задача эффективного кодирования сообщений. Эффективным называют кодирование сообщений, при котором минимизируется скорость цифрового сигнала R на выходе кодера при фиксированной производительности источника Rn (рис. 1).
Эффективные коды – это неравномерные коды – в кодовой таблице встречаются комбинации различной длины: знакам, которые встречаются чаще, присваиваются более короткие комбинации, а знакам, которые встречаются реже – оставшиеся более короткие.
Для неравномерных кодов вводится характеристика – средняя длина кодовых комбинаций
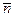 =
= 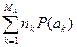 . (7)
. (7)
Теорема кодирования Шеннона для канала без помех указывает на возможность создания эффективного кода у которого средняя длина кодовой комбинации не может быть меньше энтропии, но может приближаться к ней сверху сколь угодно близко (R может приближаться к Rn скольугодно близко).
Для оценки эффективности кода вводится коэффициент эффективность кода
m = 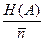 . (8)
. (8)
Используется также коэффициент сжатия эффективным кодом по сравнению с равномерным кодом
h = 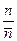 . (9)
. (9)
Эффективный код должен быть префиксным. Префиксным называется код, у которого ни одна из коротких кодовых комбинаций не является началом более длинных комбинаций. Тем самым префиксный код обеспечивает однозначную разделимость на кодовые комбинации при декодировании без введения при кодировании разделительных знаков.
2.4 Алгоритм построения кода Хаффмана. Код Хаффмана используется для кодирования независимых знаков. Для построение кода Хаффмана требуется таблица частот (вероятностей) знаков в сообщении. На основании этой таблицы строится дерево кодирования Хаффмана по следующему алгоритму:
1. Все знаки располагаются в порядке убывания их вероятностей сверху вниз (каждому знаку соответствует свой узел дерева).
2. Два знака с наименьшими вероятностями ветками объединяются в составной знак с суммарной вероятностью объединяемых знаков (далее два участвовавших в объединении знака не рассматриваются, а составной знак рассматривается наравне с остальными в списке знаков).
3. Одной ветке, например верхней, присваивается символ “1”, другой ветке – “0” (или наоборот).
4. Шаги, начиная со второго, повторяются до тех пор, пока в списке знаков не останется только один. Он и будет считаться корнем дерева.
Для определения кодовой комбинации для каждого из знаков необходимо пройти путь от корня дерева к исходным узлам (знакам), накапливая биты (0 или 1) при перемещении по ветвям дерева.
Пример 1. Задан источник дискретных сообщений с объемом алфавита MA = 6 и вероятностями знаков: P (А)=0,3; P (Е)=0,25; P (В)=0,22; P (Г)=0,1; P (Д)=0,08; P (Б)=0,05. Построить дерево кодирования Хаффмана и составить кодовую таблицу.
Построим дерево кодирования Хаффмана (рис. 2)

Рисунок 2– Дерево кодирования Хаффмана
На основании кодового дерева составим кодовую таблицу: А – 11; Е – 10; В – 00; Г – 010; Д – 0111; Б – 0110.
2.5 Алгоритм построения кода Шеннона-Фано. Код Шеннона-Фано используется для кодирования независимых знаков. Для построения кода Шеннона-Фано требуется таблица частот (вероятностей) знаков в сообщении.
1. Все знаки располагаются в порядке убывания их вероятностей сверху-вниз.
2. Вся группа знаков делится на две подгруппы, суммарные вероятности знаков которых приблизительно равны.
3. Всем знакам верхней подгруппы присваивается “0”, нижней – “1”.
4. Шаги, начиная со второго (применительно к образовавшимся подгруппам), повторяются до тех пор, пока в подгруппах останется по одному знаку.
Кодовая комбинация образуется из последовательности бит, соответствующих группам, в которых участвовал при разбиении данный знак и выписывается слева-направо.
Пример 2. Задан источник дискретных сообщений с объемом алфавита MA = 6 с вероятностями знаков: P (А)=0,3; P (Е)=0,25; P (В)=0,22; P (Г)=0,1; P (Д)=0,08; P (Б)=0,05. Построить таблицу разбиений на подгруппы по алгоритму Шеннона-Фано и составить код.
В таблице 1 проиллюстрируем принцип алгоритма Шеннона-Фано.
Таблица 1 – алгоритм Шеннона-Фано
| Знак ak | Вероятность P (ak) | Подгруппы | Кодовые комбинации | ||
| I | II | III | IV | ||
| А | 0,3 | ||||
| Е | 0,25 | ||||
| В | 0,22 | ||||
| Г | 0,1 | ||||
| Д | 0,08 | ||||
| Б | 0,05 |
Недостатки алгоритмов Хаффмана и Шеннона-Фано:
- если до начала кодирования сообщений не известны вероятности знаков, то требуется два прохождения по передаваемой последовательности: одно для составления таблицы вероятностей и кода, второе для кодирования;
- необходимость передачи по каналу связи таблицы кода вместе со сжатым сообщением, что приводит к уменьшению суммарного эффекта сжатия;
- для двоичного источника сообщений с энтропией меньше 1 дв. ед.непосредственное применение кода Хаффмана или Шеннона-Фано не дает эффекта;
- избыточность сообщения на выходе кодера равна нулю только в случае, когда вероятности кодируемых знаков являются целыми отрицательными степенями двойки (1/2; 1/4; 1/8 и т.д).
В большинстве случаев, средняя длина кодовой комбинации при сжатии кодом Шеннона-Фано такая же, как и при сжатии кодом Хаффмана. Но существуют случаи, когда в отличие от кода Хаффмана, кодирование кодом Шеннона-Фано не будет оптимальным.
|
|
|
|
|
Дата добавления: 2015-06-27; Просмотров: 361; Нарушение авторских прав?; Мы поможем в написании вашей работы!