КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Распознавание арифметических выражений
|
|
|
|
Семантический анализатор осуществляет перевод в польскую запись арифметических выражений, которые являются корректными с точки зрения синтаксических правил используемого языка программирования. Задача чтения произвольной последовательности символов языка и принятия решения о том, что она представляет собой правильное арифметическое или логическое выражение, решается на этапе синтаксического анализа с применением математического аппарата формальных грамматик.
Формальная грамматика является математической моделью языка и определяет набор правил для получения (генерации) предложений или строк этого языка. Введем ряд обозначений, позволяющих дать определение грамматики.
Пусть длина строки a определяет число символов этой строки и обозначается как |a |. Например, | ab | = 2, длина пустой строки |e| = 0. Если A - некоторый алфавит, то совокупность строк, составленных в этом алфавите и имеющих длину n, обозначается как An. Например, для алфавита A = { a, b, с } получаем
A 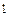 = { a, b, с }, A 2 = { aa, ab, ac, ba, bb, bс, са, сb, cc }, A
= { a, b, с }, A 2 = { aa, ab, ac, ba, bb, bс, са, сb, cc }, A 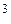 = { aaa, abb, acc, aab,...}. Необходимо отметить, что A
= { aaa, abb, acc, aab,...}. Необходимо отметить, что A 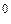 = {e}, где e - пустая строка.
= {e}, где e - пустая строка.
Множество всех строк, составленных из символов алфавита A и имеющих длину n ³ 1, обозначается как A +, где
A+ = A1 È А2 È... È Аn È....
Множество всех строк, составленных из символов алфавита A и включающих пустую строку e, обозначается через А *, где
А* = {e} È А+ = А0 È A1 È А2 È... È Аn È….
Формальной грамматикой называется четверка G = { N, T, P, S }, где N - конечное множество (алфавит) нетерминальных символов; Т - конечное множество (алфавит) терминальных символов; P - конечное множество правил вывода (продукций) вида a ® b, где a и b - строки символов, такие, что a Î (N È Т)+,
b Î (N È Т)*; S - начальный символ грамматики, причем всегда S Î N.
Терминальные символы являются неделимыми единицами некоторого языка, из которых состоят строки или предложения этого языка. Нетерминальные символы иногда называют вспомогательными, так как они определяют вспомогательные синтаксические конструкции или понятия языка и используются для получения предложений. Всегда N Ç T = Æ, т.е. множества нетерминальных и терминальных символов не имеют общих элементов. Начальный символ S грамматики является исходным при получении любой строки языка.
Арифметические и логические выражения могут быть описаны с помощью контекстно-свободных грамматик (КС-грамматик). В таких грамматиках левые части всех правил вывода состоят из одного нетерминального символа, т.е. имеют вид B ® b, где B Î N и b Î (N È Т)*. Здесь нетерминальный символ B можно заменить строкой b (возможно, пустой), не обращая внимания на контекст, в котором он встретился.
Рассмотрим КС-грамматику, описывающую арифметические выражения, построенные с использованием знаков операций +,–, *, / и круглых скобок. Операнды могут состоять из одной буквы латинского алфавита или цифры. Терминальные символы грамматики будем обозначать строчными буквами, нетерминальные - прописными. Такая грамматика может быть представлена как
G = (N, T, P, E),
где N = {E, T, F}, T = {+, –, *, /, (,), 0, 1, 2... 9, a, b, c, …, z}, а правила вывода, составляющие множество P, имеют следующий вид:
E ® T çЕ + Т çE – Т;
Т ® F çТ * F çT / F;
F ® (Е) ç0 ç1 ç2 ç... ç9 çа çb çс ç... çz.
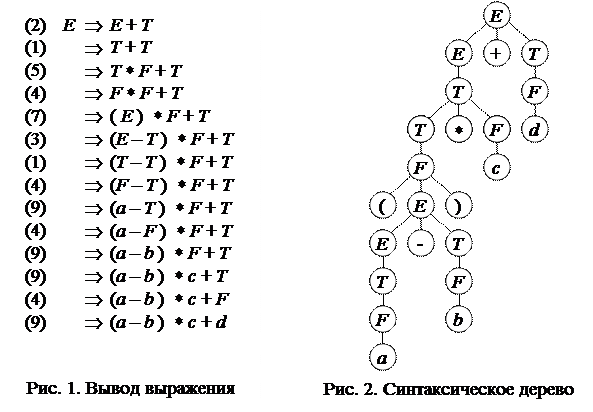
Любое правильное с точки зрения представленной грамматики арифметическое выражение можно вывести из начального символа Е последовательным применением указанных правил. Например, покажем, что выражение
(a - b)* c + d (1)
является правильным. Для этого перенумеруем правила вывода грамматики:
| 1: E ® T; | 4: T ® F; | 7: F ® (E); |
| 2: Е ® Е + Т; | 5: T ® T * F; | 8: F ® 0 ç1 ç2 ç... ç9; |
| 3: E ® E – T; | 6: T ® T / F; | 9: F ® a ç b ç c ç... ç z. |
Затем выполним вывод выражения (1) из начального символа E (рис. 1), указывая в скобках номера применяемых на каждом шаге правил. Порядок использования правил вывода также может быть представлен синтаксическим деревом, которое для данного примера имеет вид, показанный на рис. 2. Таким образом, выражение (1) является синтаксически корректным, поскольку существует конечная последовательность правил, применение которых позволяет вывести это выражение.
Для описания синтаксиса языков программирования широкое применение находит форма Бэкуса-Наура (БНФ), которая эквивалентна контекстно-свободным грамматикам, но отличается по форме записи. При использовании БНФ нетерминальные символы заключаются в угловые скобки <... >, запись::= означает "определяется как", а вертикальная черта читается как "или". Рассмотренная выше грамматика, описывающая арифметические выражения и представленная в форме Бэкуса-Наура, имеет следующий вид:
< выражение >::= < терм > | < выражение > + < терм > | < выражение > – < терм >;
< терм >::= < множитель > | < терм > * < множитель > | < терм > / < множитель >;
< множитель >::= (< выражение >) | 0 | l | 2|... | 9| a | b |... | z.
 |
|
|
|
|
|
Дата добавления: 2015-06-28; Просмотров: 1762; Нарушение авторских прав?; Мы поможем в написании вашей работы!