КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
И интенсивности ввода-вывода
|
|
|
|
Из рисунка видно, что для загрузки процессора на 90% достаточно всего трех счетных задач. Однако для того, чтобы обеспечить такую же загрузку интерактивными задачами, выполняющими интенсивный ввод-вывод, потребуются десятки таких задач. Необходимым условием для выполнения задачи является загрузка ее в оперативную память, объем которой ограничен. В этих условиях был предложен метод организации вычислительного процесса, называемый свопингом. В соответствии с этим методом некоторые процессы (обычно находящиеся в состоянии ожидания) временно выгружаются на диск. Планировщик операционной системы не исключает их из своего рассмотрения, и при наступлении условий активизации некоторого процесса, находящегося в области свопинга на диске, этот процесс перемещается в оперативную память. Если свободного места в оперативной памяти не хватает, то выгружается другой процесс.
При свопинге, в отличие от рассмотренных ранее методов реализации виртуальной памяти, процесс перемещается между памятью и диском целиком, то есть в течение некоторого времени процесс может полностью отсутствовать в оперативной памяти. Существуют различные алгоритмы выбора процессов на загрузку и выгрузку, а также различные способы выделения оперативной и дисковой памяти загружаемому процессу.
8.3.4. Иерархия запоминающих устройств. Принцип кэширования данных
Память вычислительной машины представляет собой иерархию запоминающих устройств (внутренние регистры процессора, различные типы сверхоперативной и оперативной памяти, диски, ленты), отличающихся средним временем доступа и стоимостью хранения данных в расчете на один бит (рис.8.16).
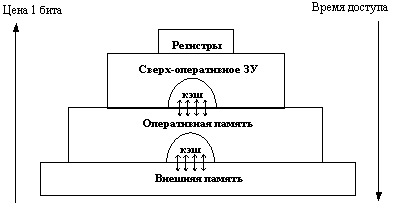
Рис.8.16. Иерархия ЗУ
Пользователю хотелось бы иметь и недорогую и быструю память. Кэш-память представляет некоторое компромиссное решение этой проблемы.
Кэш-память – это способ организации совместного функционирования двух типов запоминающих устройств, отличающихся временем доступа и стоимостью хранения данных, который позволяет уменьшить среднее время доступа к данным за счет динамического копирования в "быстрое" ЗУ наиболее часто используемой информации из "медленного" ЗУ.
Кэш-памятью часто называют не только способ организации работы двух типов запоминающих устройств, но и одно из устройств - "быстрое" ЗУ. Оно стоит дороже и, как правило, имеет сравнительно небольшой объем. Важно, что механизм кэш-памяти является прозрачным для пользователя, который не должен сообщать никакой информации об интенсивности использования данных и не должен никак участвовать в перемещении данных из ЗУ одного типа в ЗУ другого типа, все это делается автоматически системными средствами.
Рассмотрим частный случай использования кэш-памяти для уменьшения среднего времени доступа к данным, хранящимся в оперативной памяти. Для этого между процессором и оперативной памятью помещается быстрое ЗУ, называемое просто кэш-памятью (рис.8.17).
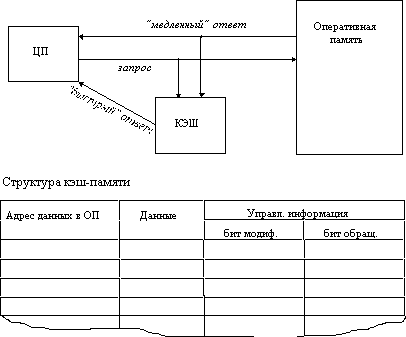
Рис.8.17. Кэш-память
В качестве такового может быть использована, например, ассоциативная память. Содержимое кэш-памяти представляет собой совокупность записей обо всех загруженных в нее элементах данных. Каждая запись об элементе данных включает в себя адрес, который этот элемент данных имеет в оперативной памяти, и управляющую информацию: признак модификации и признак обращения к данным за некоторый последний период времени.
В системах, оснащенных кэш-памятью, каждый запрос к оперативной памяти выполняется в соответствии со следующим алгоритмом:
Просматривается содержимое кэш-памяти с целью определения, не находятся ли нужные данные в кэш-памяти; кэш-память не является адресуемой, поэтому поиск нужных данных осуществляется по содержимому - значению поля "адрес в оперативной памяти", взятому из запроса.
Если данные обнаруживаются в кэш-памяти, то они считываются из нее, и результат передается в процессор.
Если нужных данных нет, то они вместе со своим адресом копируются из оперативной памяти в кэш-память, и результат выполнения запроса передается в процессор. При копировании данных может оказаться, что в кэш-памяти нет свободного места, тогда выбираются данные, к которым в последний период было меньше всего обращений, для вытеснения из кэш-памяти. Если вытесняемые данные были модифицированы за время нахождения в кэш-памяти, то они переписываются в оперативную память. Если же эти данные не были модифицированы, то их место в кэш-памяти объявляется свободным.
На практике в кэш-память считывается не один элемент данных, к которому произошло обращение, а целый блок данных, это увеличивает вероятность так называемого "попадания в кэш", то есть нахождения нужных данных в кэш-памяти.
Покажем, как среднее время доступа к данным зависит от вероятности попадания в кэш. Пусть имеется основное запоминающие устройство со средним временем доступа к данным t1 и кэш-память, имеющая время доступа t2, очевидно, что t2<t1. Обозначим через t среднее время доступа к данным в системе с кэш-памятью, а через p -вероятность попадания в кэш. По формуле полной вероятности имеем:
t = t1((1 - p) + t2(p
Из нее видно, что среднее время доступа к данным в системе с кэш-памятью линейно зависит от вероятности попадания в кэш и изменяется от среднего времени доступа в основное ЗУ (при р=0) до среднего времени доступа непосредственно в кэш-память (при р=1).
В реальных системах вероятность попадания в кэш составляет примерно 0,9. Высокое значение вероятности нахождения данных в кэш-памяти связано с наличием у данных объективных свойств: пространственной и временной локальности.
Пространственная локальность. Если произошло обращение по некоторому адресу, то с высокой степенью вероятности в ближайшее время произойдет обращение к соседним адресам.
Временная локальность. Если произошло обращение по некоторому адресу, то следующее обращение по этому же адресу с большой вероятностью произойдет в ближайшее время.
Все предыдущие рассуждения справедливы и для других пар запоминающих устройств, например, для оперативной памяти и внешней памяти. В этом случае уменьшается среднее время доступа к данным, расположенным на диске, и роль кэш-памяти выполняет буфер в оперативной памяти.
8.4.Управление вводом-выводом
Одной из главных функций ОС является управление всеми устройствами ввода-вывода компьютера. ОС должна передавать устройствам команды, перехватывать прерывания и обрабатывать ошибки; она также должна обеспечивать интерфейс между устройствами и остальной частью системы. В целях развития интерфейс должен быть одинаковым для всех типов устройств (независимость от устройств).
8.4.1. Физическая организация устройств ввода-вывода
Устройства ввода-вывода делятся на два типа: блок-ориентированные устройства и байт-ориентированные устройства. Блок-ориентированные устройства хранят информацию в блоках фиксированного размера, каждый из которых имеет свой собственный адрес. Самое распространенное блок-ориентированное устройство - диск. Байт-ориентированные устройства не адресуемы и не позволяют производить операцию поиска, они генерируют или потребляют последовательность байтов. Примерами являются терминалы, строчные принтеры, сетевые адаптеры. Однако некоторые внешние устройства не относятся ни к одному классу, например, часы, которые, с одной стороны, не адресуемы, а с другой стороны, не порождают потока байтов. Это устройство только выдает сигнал прерывания в некоторые моменты времени.
Внешнее устройство обычно состоит из механического и электронного компонента. Электронный компонент называется контроллером устройства или адаптером. Механический компонент представляет собственно устройство. Некоторые контроллеры могут управлять несколькими устройствами. Если интерфейс между контроллером и устройством стандартизован, то независимые производители могут выпускать совместимые как контроллеры, так и устройства.
Операционная система обычно имеет дело не с устройством, а с контроллером. Контроллер, как правило, выполняет простые функции, например, преобразует поток бит в блоки, состоящие из байт, и осуществляют контроль и исправление ошибок. Каждый контроллер имеет несколько регистров, которые используются для взаимодействия с центральным процессором. В некоторых компьютерах эти регистры являются частью физического адресного пространства. В таких компьютерах нет специальных операций ввода-вывода. В других компьютерах адреса регистров ввода-вывода, называемых часто портами, образуют собственное адресное пространство за счет введения специальных операций ввода-вывода (например, команд IN и OUT в процессорах i86).
ОС выполняет ввод-вывод, записывая команды в регистры контроллера. Например, контроллер гибкого диска IBM PC принимает 15 команд, таких как READ, WRITE, SEEK, FORMAT и т.д. Когда команда принята, процессор оставляет контроллер и занимается другой работой. При завершении команды контроллер организует прерывание для того, чтобы передать управление процессором операционной системе, которая должна проверить результаты операции. Процессор получает результаты и статус устройства, читая информацию из регистров контроллера.
8.4.2. Организация программного обеспечения ввода-вывода
Основная идея организации программного обеспечения ввода-вывода состоит в разбиении его на несколько уровней, причем нижние уровни обеспечивают экранирование особенностей аппаратуры от верхних, а те, в свою очередь, обеспечивают удобный интерфейс для пользователей.
Ключевым принципом является независимость от устройств. Вид программы не должен зависеть от того, читает ли она данные с гибкого диска или с жесткого диска.
Очень близкой к идее независимости от устройств является идея единообразного именования, то есть для именования устройств должны быть приняты единые правила.
Другим важным вопросом для программного обеспечения ввода-вывода является обработка ошибок. Вообще говоря, ошибки следует обрабатывать как можно ближе к аппаратуре. Если контроллер обнаруживает ошибку чтения, то он должен попытаться ее скорректировать. Если же это ему не удается, то исправлением ошибок должен заняться драйвер устройства. Многие ошибки могут исчезать при повторных попытках выполнения операций ввода-вывода, например, ошибки, вызванные наличием пылинок на головках чтения или на диске. И только если нижний уровень не может справиться с ошибкой, он сообщает об ошибке верхнему уровню.
Еще один ключевой вопрос - это использование блокирующих (синхронных) и неблокирующих (асинхронных) передач. Большинство операций физического ввода-вывода выполняется асинхронно - процессор начинает передачу и переходит на другую работу, пока не наступает прерывание. Пользовательские программы намного легче писать, если операции ввода-вывода блокирующие - после команды READ программа автоматически приостанавливается до тех пор, пока данные не попадут в буфер программы. ОС выполняет операции ввода-вывода асинхронно, но представляет их для пользовательских программ в синхронной форме.
Последняя проблема состоит в том, что одни устройства являются разделяемыми, а другие - выделенными. Диски - это разделяемые устройства, так как одновременный доступ нескольких пользователей к диску не представляет собой проблему. Принтеры - это выделенные устройства, потому что нельзя смешивать строчки, печатаемые различными пользователями. Наличие выделенных устройств создает для операционной системы некоторые проблемы.
Для решения поставленных проблем целесообразно разделить программное обеспечение ввода-вывода на четыре слоя (рис.8.18):
· обработка прерываний;
· драйверы устройств;
· независимый от устройств слой операционной системы;
· пользовательский слой программного обеспечения.
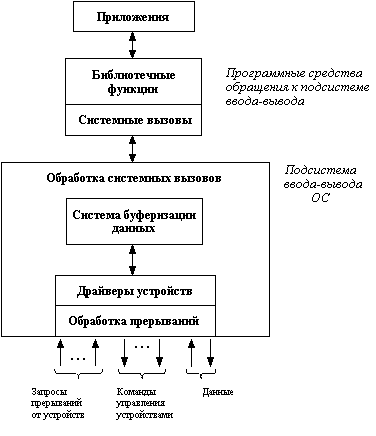
Рис.8.18. Многоуровневая организация подсистемы ввода-вывода
9. Системные программы
9.1. Утилиты
Ути́лита (англ. utility или tool) – программный продукт, предназначенный не для решения какой-либо прикладной задачи, а для решения вспомогательных задач.
Так компьютерные утилиты можно разделить на три группы: утилиты сервисного обслуживания компьютера, утилиты расширения функциональности и информационные утилиты.
Утилиты сервисного обслуживания (УСО)
К УСО относятся все виды сервисных программ, такие как утилиты по: дефрагментации, проверке и исправлению структуры разделов жёсткого диска, исправлению системных зависимостей, тонкой настройке системы и т. д.
Поскольку типовой набор необходимых УСО примерно одинаков для всех пользователей ПК, то большое распространение получили заранее собранные пакеты утилит, наиболее ярким примером которых может послужить пакет Norton Utilities (входящий в Norton System Works) от компании Symantec.
Основные типы УСО
Дефрагментаторы проверяют степень фрагментации файлов и свободного пространства на доступных системе разделах логических накопителей, устраняют (снижают) её – дефрагментируют, а также могут перемещать файлы для расположения в порядке, обеспечивающем оптимальное время доступа (минимальное – к часто используемым файлам за счёт большего – к редко используемым).
Утилиты по контролю ошибок и повреждений структуры разделов и SMART-ревизоры проверяют на наличие ошибок файловую систему, и устройство хранения данных (жёсткий диск, устройство на основе Flash-памяти, дискету…). Также могут обращаться к SMART-модулю жёсткого диска для контроля его служебной информации.
· Для UNIX-подобных ОС
o fsck (входит в утилиты для файловых систем в GNU/Linux)
· Для Microsoft Windows и Windows NT
o Norton Disk Doctor (часть Norton Utilities, входящих в свою очередь в Norton System Works от Symantec Corporation)
o Windows Chkdisk (часть ОС Windows NT 5.x)
o Windows Scandisk (часть ОС Windows 4.x)
o SMART-мониторы, и другие
Утилиты контроля целостности системы сканируют конфигурационные файлы, символьные ссылки и/или ярлыки с целью поиска некорректных записей, а также удалённых или перемещённых файлов.
· Для Microsoft Windows и Windows NT
o Norton WinDoctor (часть Norton Utilities, входящих в свою очередь в Norton System Works от Symantec Corporation)
o JV16 Power Tools
o JV RegCleaner
o CCleaner
· Для UNIX-подобных ОС
o TIGER (набор скриптов на GNU Bash)
o chkrootkit
o cruft, deborphan, debfoster в Debian
Утилиты расширения функциональности р асширяют функциональность существующих прикладных или системных средств, например, утилиты автоматизации и переконвертации медиа-тегов (mp3 id3, Ogg tags), безопасного (невосстановимого) удаления файлов, утилиты переконвертирования файлов различных форматов, утилиты системного менеджмента.
Основные виды утилит расширения функциональности
Утилиты-конвертеры занимаются переконвертированием файлов, представляющих собой различное представление одного и того же типа данных, но в разных форматах: аудио, видео, графические, конструкторские, модельные, программные файлы.
К ним относятся:
· Конвертеры программного кода, преобразующие исходные тексты с одного языка программирования или его реализации (например, Borland C++ → Microsoft Visual C++) на другой или же оптимизирующие исходный код в пределах одного языка/реализации. (В принципе, компилятор тоже можно отнести к конвертерам – с языка высокого уровня в машинный код)
· Конвертеры мультимедийных файлов, перекодирующие закодированные в файлах по одному из известных кодеков мультимедийные данные при помощи другого кодека, а так же, опционально, меняющие разрешение, глубину кодирования и иные параметры мультимедийного потока.
· Конвертеры графических файлов, преобразующие между собой различные графические форматы, а также выделяющие изображения из видеопотока.
Утилиты – редакторы метаинформации занимаются сбором, записью и редактированием метаинформации файлов, такой как содержимое тегов мультимедийных файлов, информация о медиасодержимом, данные EXIF тегов цифровых изображений, etc.. Обычно входят в состав так называемой медиа-библиотеки.
Утилиты системного менеджмента занимаются расширенным управлением системой, таким как: работа с разделами дисков, перепрограммирование (перепрошивка) памяти BIOS, установка расширенных аппаратных настроек аппаратного обеспечения.
К ним относятся:
· В ОС Windows NT 4 – 5.1 большинство утилит системного менеджмента сгруппировано в Windows Management Console вызываемой пунктом «Управление компьютером» контекстного меню значка «Мой компьютер»
· Утилиты по работе разделами диска:
o Microsoft fdisk – утилита по работе с разделами диска, часть ОС Microsoft Windows.
o Linux fdisk – консольное приложение для работы с разделами диска под ОС на ядре Linux
o Disk Druid – утилита по работе с разделами диска под ОС GNU/Linux с графическим пользовательским интерфейсом.
o mdadm – утилита GNU/Linux для управления RAID массивами (Linux Software Raid)
o PartitionMagic – утилита для работы с разделами диска под ОС Windows или DOS с графическим пользовательским интерфейсом.
o Оснастка «Управление дисками» Windows Management Console
· Утилиты тонкой настройки занимаются тонкой (расширенной) настройкой существующих программ или ОС:
o «Xteq-dotec X-Setup»
o OnTrack WinCustomizer
Информационные утилиты включают в себя мониторы, бенчмарки, и утилиты общей (статической) информации.
9.2. Компилятор
Компиля́тор – это:
1. Программа или техническое средство, выполняющее компиляцию.
2. Машинная программа, используемая для компиляции.
3. Транслятор, выполняющий преобразование программы, составленной на исходном языке, в объектный модуль.
4. Программа, переводящая текст программы на языке высокого уровня, в эквивалентную программу на машинном языке.
5. Программа, предназначенная для трансляции высокоуровневого языка в абсолютный код или, иногда, в язык ассемблера. Входной информацией для компилятора (исходный код) является описание алгоритма или программа на проблемно-ориентированном языке, а на выходе компилятора – эквивалентное описание алгоритма на машинно-ориентированном языке (объектный код).
Компиляция – это
1. Трансляция программы на язык, близкий к машинному.
2. Трансляция программы, составленной на исходном языке, в объектный модуль. Осуществляется компилятором.
Компилировать – проводить трансляцию машинной программы с проблемно-ориентированного языка на машинно-ориентированный язык
Виды компиляторов
· Векторизующий. Транслирует исходный код в машинный код компьютеров, оснащённых векторным процессором.
· Гибкий. Составлен по модульному принципу, управляется таблицами и запрограммирован на языке высокого уровня или реализован с помощью компилятора компиляторов.
· Инкрементальный. Повторно транслирует фрагменты программы и дополнения к ней без перекомпиляции всей программы.
· Интерпретирующий (пошаговый). Последовательно выполняет независимую компиляцию каждого отдельного оператора (команды) исходной программы.
· Компилятор компиляторов. Транслятор, воспринимающий формальное описание языка программирования и генерирующий компилятор для этого языка.
· Отладочный. Устраняет отдельные виды синтаксических ошибок.
· Резидентный. Постоянно находится в основной памяти и доступен для повторного использования многими задачами.
· Самокомпилируемый. Написан на том же языке, с которого осуществляется трансляция.
· Универсальный. Основан на формальном описании синтаксиса и семантики входного языка. Составными частями такого компилятора являются: ядро, синтаксический и семантический загрузчики.
Виды компиляции
· Пакетная. Компиляция нескольких исходных модулей в одном пункте задания.
· Построчная. То же, что и интерпретация.
· Условная. Компиляция, при которой транслируемый текст зависит от условий, заданных в исходной программе. Так, в зависимости от значения некоторой константы, можно включать или выключать трансляцию части текста программы.
Основы
Большинство компиляторов переводит программу с некоторого высокоуровневого языка программирования в машинный код, который может быть непосредственно выполнен центральным процессором. Как правило, этот код также ориентирован на исполнение в среде конкретной операционной системы, поскольку использует предоставляемые ею возможности (системные вызовы, библиотеки функций). Архитектура (набор программно-аппаратных средств), для которой производится компиляция, называется целевой машиной.
Некоторые компиляторы (например, Java) переводят программу не в машинный код, а в программу на некотором специально созданном низкоуровневом языке. Такой язык – байт-код – также можно считать языком машинных команд, поскольку он подлежит интерпретации виртуальной машиной. Например, для языка Java это JVM (язык виртуальной машины Java), или так называемый байт-код Java (вслед за ним все промежуточные низкоуровневые языки стали называть байт-кодами). Для языков программирования на платформе.NET Framework (C#, Managed C++, Visual Basic.NET и другие) это MSIL (Microsoft Intermediate Language, «Промежуточный язык фирмы Майкрософт»).
Программа на байт-коде подлежит интерпретации виртуальной машиной, либо ещё одной компиляции уже в машинный код непосредственно перед исполнением. Последнее называеется «Just-In-Time компиляция» (JIT), по названию подобного компилятора для Java. MSIL-код компилируется в код целевой машины также JIT-компилятором, а библиотеки.NET Framework компилируются заранее).
Для каждой целевой машины (IBM, Apple и т. д.) и каждой операционной системы или семейства операционных систем, работающих на целевой машине, требуется написание своего компилятора. Существуют также так называемые кросс-компиляторы, позволяющие на одной машине и в среде одной ОС получать код, предназначенный для выполнения на другой целевой машине и/или в среде другой ОС. Кроме того, компиляторы могут быть оптимизированы под разные типы процессоров из одного семейства (путём использования специфичных для этих процессоров инструкций). Например, код, скомпилированный под процессоры семейства i686, может использовать специфичные для этих процессоров наборы инструкций – MMX, SSE, SSE2.
Также существуют компиляторы, переводящие программу с языка высокого уровня на ассемблер.
Существуют программы, которые решают обратную задачу – перевод программы с низкоуровневого языка на высокоуровневый. Этот процесс называют декомпиляцией, а программы – декомпиляторами. Но поскольку компиляция – это процесс с потерями, точно восстановить исходный код, скажем, на C++, в общем случае невозможно. Более эффективно декомпилируются программы в байт-кодах – например, существует довольно надёжный декомпилятор для Flash. Сходным процессом является дизассемблирование машинного кода в код на ассемблере, который всегда выполняется успешно. Связано это с тем, что между кодами машинных команд и командами ассемблера имеется практически однозначное соответствие.
Структура компилятора
Процесс компиляции состоит из следующих этапов:
· Лексический анализ. На этом этапе последовательность символов исходного файла преобразуется в последовательность лексем.
· Синтаксический (грамматический) анализ. Последовательность лексем преобразуется в дерево разбора.
· Семантический анализ. Дерево разбора обрабатывается с целью установления его семантики (смысла) – напр. привязка идентификаторов к их декларациям, типам, проверка совместимости, определение типов выражений и т. д. Результат обычно называется «промежуточным представлением/кодом», и может быть дополненным деревом разбора, новым деревом, абстрактным набором команд или чем-то ещё, удобным для дальнейшей обработки.
· Оптимизация. Выполняется удаление излишних конструкций и упрощение кода с сохранением его смысла. Оптимизация может быть на разных уровнях и этапах, напр. над промежуточным кодом или над конечным машинным кодом.
· Генерация кода. Из промежуточного представления выдается код на целевом языке.
В конкретных реализациях компиляторов, эти этапы могут быть раздельны или совмещены в том или ином виде.
Трансляция и компоновка
Важной исторической особенностью компилятора, отраженной в его названии (англ. compile – собирать вместе, составлять), являлось то, что он мог производить и компоновку (то есть содержал две части – транслятор и компоновщик). Это связано с тем, что раздельная компиляция и компоновка как отдельная стадия сборки выделились значительно позже появления компиляторов, и многие популярные компиляторы (например, GCC) до сих пор физически объединены со своими компоновщиками. В связи с этим, вместо термина «компилятор» иногда используют термин «транслятор» как его синоним: либо в старой литературе, либо когда хотят подчеркнуть его способность переводить программу в машинный код (и наоборот, используют термин «компилятор» для подчеркивания способности собирать из многих файлов один).
9.3. Отладчик
Отладчик является модулем среды разработки или отдельным приложением, предназначенным для поиска ошибок в программе. Отладчик позволяет выполнять пошаговую трассировку, отслеживать значения переменных в процессе выполнения программы, устанавливать точки или условия останова и т. д.
9.4. Интерпретатор
Интерпретатор (языка программирования) – это:
1. Программа или техническое средство, выполняющее интерпретацию.
2. Вид транслятора, осуществляющего пооператорную (покомандную) обработку и выполнение исходной программы или запроса (в отличие от компилятора, транслирующего всю программу без её выполнения).
3. Программа (иногда аппаратное средство), анализирующее команды или операторы программы и немедленно выполняющее их.
4. Языковый процессор, который построчно анализирует исходную программу и одновременно выполняет предписанные действия, а не формирует на машинном языке скомпилированную программу, которая выполняется впоследствии
Типы интерпретаторов
Простой интерпретатор анализирует и тут же выполняет (собственно интерпретация) программу покомандно (или построчно), по мере поступления её исходного кода на вход интерпретатора. Достоинством такого подхода является мгновенная реакция. Недостаток – такой интерпретатор обнаруживает ошибки в тексте программы только при попытке выполнения команды (или строки) с ошибкой.
Интерпретатор компилирующего типа – это система из компилятора, переводящего исходный код программы в промежуточное представление, например, в байт-код или p-код, и собственно интерпретатора, который выполняет полученный промежуточный код (так называемая виртуальная машина). Достоинством таких систем является большее быстродействие выполнения программ (за счёт выноса анализа исходного кода в отдельный, разовый проход, и минимизации этого анализа в интерпретаторе). Недостатки – большее требование к ресурсам и требование на корректность исходного кода. Применяется в таких языках, как PHP, Python, Perl (используется байт-код), а также в различных СУБД (используется p-код).
В случае разделения интерпретатора компилирующего типа на компоненты получаются компилятор языка и простой интерпретатор с минимизированным анализом исходного кода. Причём исходный код для такого интерпретатора не обязательно должен иметь текстовый формат или быть байт-кодом, который понимает только данный интерпретатор, это может быть машинный код какой-то существующей аппаратной платформы. К примеру, виртуальные машины вроде QEMU, Bochs, VMware включают в себя интерпретаторы машинного кода процессоров семейства x86.
Некоторые интерпретаторы (например, для языков Lisp, Scheme, Python, Бейсик и других) могут работать в режиме диалога или так называемого цикла чтения-вычисления-печати (англ. read-eval-print loop, REPL). В таком режиме интерпретатор считывает законченную конструкцию языка (например, s-expression в языке Lisp), выполняет её, печатает результаты, после чего переходит к ожиданию ввода пользователем следующей конструкции.
Уникальным является язык Forth, который способен работать как в режиме интерпретации, так и компиляции входных данных, позволяя переключаться между этими режимами в произвольный момент, как во время трансляции исходного кода, так и во время работы программ.
Следует также отметить, что режимы интерпретации можно найти не только в программном, но и аппаратном обеспечении. Так, многие микропроцессоры интерпретируют машинный код с помощью встроенных микропрограмм, а процессоры семейства x86, начиная с Pentium (например, на архитектуре Intel P6), во время исполнения машинного кода предварительно транслируют его во внутренний формат (в последовательность микроопераций).
Достоинства и недостатки интерпретаторов
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 523; Нарушение авторских прав?; Мы поможем в написании вашей работы!