КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Организация файлов и доступ к ним. Операции над файлами
|
|
|
|
Файл представляет собой набор однородных записей – наименьших элементов данных, которые могут быть обработаны как единое целое прикладной программой при обмене с внешним устройством. В большинстве операционных систем размер записи равен одному байту. Приложения оперируют записями, физический обмен с устройством ввода/вывода осуществляется блоками, поэтому записи объединяются в блоки. Операционные системы поддерживают несколько вариантов структуризации файлов:
1. Последовательный файл – неструктурированная последовательность байтов, обработка которых предполагает последовательное чтение записей от начала файла до конца. Способ последовательного чтения файла называется последовательным доступом (например, если в качестве носителя файла используется магнитная лента, причем текущая позиция считывания может быть возвращена к началу файла командой rewound). Способ использовался в старых операционных системах, когда дисков не было и компьютеры оснащались магнитофонами.
2. Файл прямого доступа – файл, байты которого могут быть считаны в произвольном порядке. На дисках файлы хранятся на устройствах прямого (random) доступа, поэтому содержимое файла может быть разбросано по разным блокам диска, которые можно считывать в произвольном порядке. Номер блока (относительный номер, специфицирующий блок) определяется позицией внутри файла. Для доступа к середине файла просмотр его с начала не обязателен. Данная схема обеспечивает максимальную гибкость и универсальность. С помощью базовых системных вызовов (или функций библиотеки ввода/вывода) пользователи могут структурировать файлы по своему желанию.
3.В ранних операционных системах использовались другие формы организации файла и другие способы доступа к ним. В настоящее время они применяются в больших мэйнфреймах, ориентированных на коммерческую обработку данных.
Способ 1. Хранение файла в виде последовательности записей фиксированной длины, каждая из которых имеет внутреннюю структуру. Операция чтения производится над записью, а операция записи переписывает или добавляет запись целиком. Ранее использовались записи по 80 байт (по числу позиций в перфокарте) или по 132 символа (по ширине принтера). В операционной системе СР/М файлы были последовательностями 128-символьных записей. С введением CRT -терминалов[2] идея утратила популярность.
| l1 | l2 | l3 |
| |||||
|
| ||||
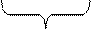
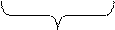
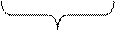
| Рис. 4.2. Файл как последовательность записей переменной длины |
Способ 2. Хранение файла в виде последовательности записей переменной длины, каждая из которых содержит ключевое поле в фиксированной позиции внутри записи (рис. 4.2.). Базисной операцией является считывание записи с каким-либо значением ключа. Записи могут располагаться в файле последовательно (например, отсортированные по значению ключевого поля) или в более сложном порядке. Метод доступа по значению ключевого поля к записям последовательного файла называется индексно-последовательным.
Способ 3. В некоторых системах ускорение доступа к файлу обеспечивает конструированием индекса файла. Индекс обычно хранится на том же устройстве, что и сам файл, и состоит из списка элементов, каждый из которых содержит идентификатор записи, за которым следует указание о местоположении данной записи. Для поиска записи вначале происходит обращение к индексу, где находится указатель на нужную запись. Такие файлы называются индексированными, а метод доступа к ним – доступ с использованием индекса (рис. 4.3.).
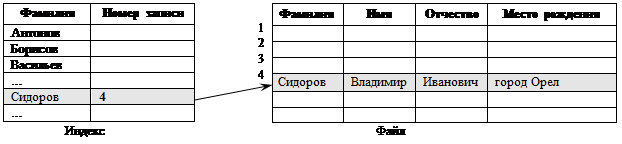 |
| Рис. 4.3. Организация индекса для последовательного файла |

Другим способом выделения дискового пространства при помощи индексных узлов (например, Unix) является древовидная организация блоков, при которой блоки, составляющие файл, являются листьями дерева, а каждый внутренний узел содержит указатели на множество блоков файла (рис. 4.4.). Для больших файлов индекс может оказаться громоздким, в этом случае создают индекс для индексного файла (блоки промежуточного уровня или блоки косвенной адресации).
Файлы позволяют сохранять информацию и получать ее. Операционная система должна предоставить в распоряжение пользователя набор операций для работы с файлами, реализованных через системные вызовы. Чаще всего при работе с файлом пользователь выполняет не одну, а несколько операций, например:
- найти данные файла и его атрибуты по символьному имени;
- считать необходимые атрибуты файла в отведенную область оперативной памяти и проанализировать права пользователя на выполнение требуемой операции;
- выполнить операцию;
- освободить занимаемую данными файла область памяти.
Ниже приведены наиболее часто встречающиеся системные вызовы, относящиеся к файлам:
- Create – создание файла без данных. Системный вызов объявляет о создании нового файла и позволяет установить некоторые его атрибуты; при этом выделяется место для файла на диске и вносится запись в каталог.
- Delete – удаление файла и освобождение занимаемого им дискового пространства.
- Open – открытие файла. Перед использованием файла процесс должен его открыть. Системный вызов разрешает системе проанализировать атрибуты файла и проверить права доступа к нему, а также считать в оперативную память список адресов блоков файла для быстрого доступа к его данным. Открытие файла является процедурой создания дескриптора или управляющего блока файла. Дескриптор (описатель) файла хранит всю информацию о нем. Иногда в языках программирования, под дескриптором понимается альтернативное имя файла или указатель на описание файла в таблице открытых файлов, используемый при последующей работе с файлом. Например, на языке Си операция открытия файла fd=open (pathname, flags, modes); возвращает дескриптор fd, который может быть задействован при выполнении операций чтения (read (fd, buffer, count);) или записи.
- Close – закрытие файла. Если работа с файлом завершена, его атрибуты и адреса блоков на диске больше не нужны, файл нужно закрыть, чтобы освободить место во внутренних таблицах файловой системы.
- Reade – чтение данных из файла. Вызывающий процесс должен указать объем считываемых данных и предоставить для них буфер в оперативной памяти.
- Write – запись данных в файл. Запись данных в файл производится в текущую позицию. Если текущая позиция находится в конце файла, его размер увеличивается, в противном случае запись осуществляется на место имеющихся данных, которые теряются.
- Append – добавление. Системный вызов представляет собой усеченную версию вызова write и может только добавлять данные к концу файла.
- Seek – поиск. Для файлов произвольного доступа нужно указывать, где располагаются данные в файле. Системный вызов устанавливает файловый указатель в определенную позицию в файле. После выполнения системного вызова данные могут читаться или записываться в этой позиции.
- Get attributes – получение атрибутов. Процессам часто для выполнения работы нужно получать атрибуты файла при помощи системного вызова.
- Set attributes – установка атрибутов. Некоторые атрибуты файла могут устанавливаться пользователем после создания файла. Системный вызов предоставляет такую возможность.
- Rename – переименование файла. Системный вызов позволяет изменить имя файла.
Существует два способа выполнения последовательности действий над файлами.
Способ 1. Для каждой операции выполняются как универсальные, так и уникальные действия. Например, последовательность операций может быть такой: open, read1, close,... open, read2, close,... open, read3, close. Данный способ более устойчив к сбоям, поскольку результаты каждой операции становятся независимыми от результатов предыдущей операции, поэтому он иногда применяется в распределенных файловых системах (например, Sun NFS).
Способ 2. Универсальные действия выполняются в начале и в конце последовательности операций, а для каждой промежуточной операции выполняются только уникальные действия. В этом случае последовательность вышеприведенных операций будет выглядеть так: open, read1,... read2,... read3, close. Данный способ использует большинство операционных систем как более экономичный и быстрый.
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 2622; Нарушение авторских прав?; Мы поможем в написании вашей работы!