КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Логическая и физическая организация файла
|
|
|
|
В общем случае данные, содержащиеся в файле, имеют логическую структуру. Эта структура является базой при разработке программы, предназначенной для обработки этих данных. Поддержание структуры данных может быть возложено на приложение либо в определенной степени эту работу может выполнять файловая система. Если приложение ведает действиями, связанными со структуризацией и интерпретацией содержимого файла, то файл представляется файловой системе неструктурированной последовательностью данных. Приложение формулирует запросы к файловой системе на ввод-вывод, используя общие для всех приложений системные средства, например, указывая смещение от начала файла и количество байт, которые необходимо считать или записать. Поступивший к приложению поток байт интерпретируется в соответствии с заложенной в программе логикой.
Модель файла, в соответствии с которой содержимое файла представляется неструктурированной последовательностью байт, стала популярной с операционной системы UNIX, в настоящее время широко используется в современных операционных системах. Неструктурированная модель позволяет легко организовать разделение файла между несколькими приложениями, которые могут по-своему структурировать и интерпретировать данные, содержащиеся в файле.
Другая модель файла – структурированный файл применялась в ранних операционных системах (OS/360, DEC RSX и VMS), в настоящее время используется редко. В этом случае поддержание структуры файла поручается файловой системе. Файловая система видит файл как упорядоченную последовательность логических записей. Приложение может обращаться к файловой системе с запросами на ввод-вывод на уровне записей. Файловая система должна обладать информацией о структуре файла, достаточной для того, чтобы выделить любую запись. Файловая система представляет приложению доступ к записи, а вся остальная обработка данных, содержащаяся в этой записи, выполняется приложением. Развитием этого подхода стали системы управления базами данных (СУБД), которые поддерживают сложную структуру данных и взаимосвязи между ними.
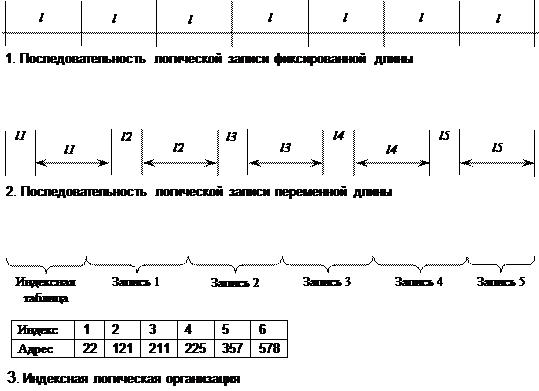
Логическая запись представляет собой наименьший элемент данных, которым может оперировать программист при обмене с внешним устройством. Даже если физический обмен с устройством осуществляется большими единицами, операционная система обеспечивает программисту доступ к отдельной логической записи. Файловая система может использовать два способа доступа к логическим записям: читать или записывать логические записи последовательно (последовательный доступ) или позиционировать файл на запись с указанным номером (прямой доступ). Файловая система может поддерживать только несколько схем логической организации файла (рис. 4.9.).
|
К числу таких способов относится представление данных в виде записей, длина которых фиксирована в пределах файла (рис.4.9.(1)). В этом случае доступ к n записи осуществляется либо путем последовательного чтения предшествующих записей, либо прямо по адресу, вычисленному по ее порядковому номеру. Другой способ состоит в представлении данных в виде последовательности записей, размер которых изменяется в пределах одного файла (рис. 4.9.(2)). В этом случае для поиска нужной записи система должна последовательно считать все предшествующие записи. Вычислить адрес нужной записи по ее номеру при такой логической организации файла невозможно, поэтому не может быть применен более эффективный метод прямого доступа. Файлы, доступ к записям которых осуществляется последовательно, по номерам позиций, называются неиндексированными или последовательными.
Другим типом файлов являются индексированные файлы, которые допускают прямой доступ к отдельной логической записи (рис.4.9.(3)). В индексированном файле записи имеют одно или более ключевых полей и могут адресоваться путем указания этих значений. Для быстрого поиска данных в индексированном файле предусматривается индексная таблица, в которой значениям ключевых полей ставится в соответствие адрес внешней памяти. Этот адрес может указывать на искомую запись (прямой доступ) либо на область внешней памяти, занимаемой несколькими записями, в число которых входит и искомая запись (прямой доступ и последовательный доступ). В последнем случае файл имеет индексно-последовательную организацию. Ведением индексных таблиц занимается файловая система.
Описанные выше структуры в большей степени имеют отношение к обычным файлам, которые могут быть структурированными и неструктурированными. Остальные типы файлов обладают определенной структурой, известной файловой системе.
Физическая организация файла описывает правила расположения файла на устройстве внешней памяти (способ размещения файла на диске). Основными критериями эффективности физической организации файлов являются:
- скорость доступа к данным;
- объем адресной информации файла;
- степень фрагментированности дискового пространства;
- максимально возможный размер файла.
Файл состоит из физических записей – блоков. Блок – наименьшая единица данных, которой внешнее устройство обменивается с оперативной памятью. Важным моментом в реализации хранения файлов является учет соответствия блоков диска файлам. В операционных системах применяются разные методы физической организации файлов и, соответственно, выделения файлу дискового пространства.
Метод 1: выделение непрерывной последовательностью блоков – хранение каждого файла непрерывной последовательностью блоков диска (простейший способ). При непрерывном расположении (рис. 4.10.) файл характеризуется адресом и длиной (в блоках). Файл, стартующий с блока b, занимает затем блоки b + 1, b + 2,... b + n – 1. Например, на диске, состоящем из блоков по 1 Кбайт, файл размером в 50 Кбайт будет занимать 50 последовательных блоков, при 2-килобайтных блоках – 25 последовательных блоков.
Преимущества: простота и легкость реализации, так как выяснение местонахождения файла сводится к вопросу, где находится первый блок; хорошая производительность, так как целый файл может быть считан за одну дисковую операцию. Непрерывное выделение блоков используется в операционных системах IBM/CMS, RSX-11 (для выполняемых файлов) и в ряде других.
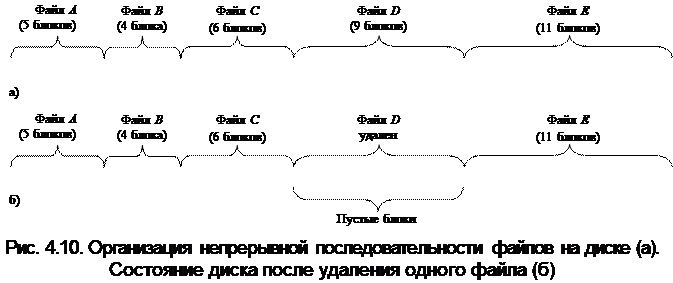 |
Недостатки. Во время создания файла заранее не известна его длина, а значит не известно, сколько памяти надо зарезервировать для этого файла. В процессе эксплуатации диск представляет собой некоторую совокупность свободных и занятых фрагментов и не всегда имеется подходящий по размеру свободный фрагмент для нового файла. Непрерывное распределение внешней памяти неприменимо до тех пор, пока неизвестен максимальный размер файла. При таком порядке размещения неизбежно возникает фрагментация, и пространство на диске используется не эффективно, так как отдельные участки маленького размера (минимально 1 блок) могут остаться не используемыми. Некоторые операционные системы используют модифицированный вариант непрерывного выделения: к основным блокам файла добавляют резервные блоки. Однако с выделением блоков из резерва возникают аналогичные проблемы.
Метод нерационален, когда содержимое диска постоянно изменяется. Однако для стационарных файловых систем, например для файловых систем компакт-дисков, метод пригоден. Файловые системы, состоящие из непрерывных файлов, использовались на магнитных дисках в ранних операционных системах благодаря их простоте и высокой производительности. Некоторое время идея не использовалась, но с появлением CD-ROM, DVD и других одноразовых оптических носителей метод снова стал использоваться.
Метод 2: связный список. Внешняя фрагментация (основная проблема предыдущего метода) может быть устранена за счет представления файла в виде связного списка блоков диска (рис. 4.11.). При таком способе в начале каждого блока содержится указатель на следующий блок. В этом случае адрес файла также может быть задан одним числом – номером первого блока. В отличие от предыдущего способа, каждый блок может быть присоединен в цепочку какого-либо файла, следовательно, фрагментация отсутствует.
Метод позволяет использовать каждый блок диска. Потерь дискового пространства на фрагментацию (кроме потерь в последних блоках файла) не возникает. Файл может изменяться во время своего существования, наращивая число блоков. Запись в директории содержит указатель на первый и последний блоки файла, иногда в качестве варианта используется специальный знак конца файла EOF. Первое слово каждого блока используется как указатель на следующий блок, в остальной части блока хранятся данные.
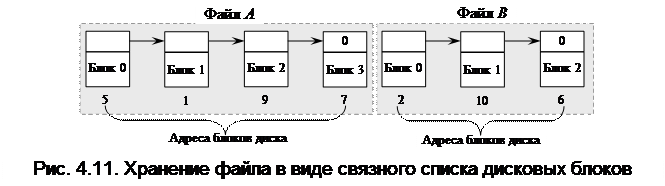

Недостатки. При прямом доступе к файлу выбор логически смежных записей, которые занимают физически несмежные секторы, может потребовать много времени. Так чтобы получить доступ к блоку n операционная система должна сначала прочитать n-1 блоков по очереди. Прямым следствием этого является низкая надежность. Наличие дефектного блока в списке приводит к потере информации в оставшейся части файла и потенциально к потере дискового пространства, отведенного под этот файл. Для указателя на следующий блок внутри блока нужно выделить место, что не всегда удобно. Поэтому метод связного списка обычно в чистом виде не используется.
Метод 3: связный список при помощи таблицы отображения файлов. Оба недостатка схемы организации файлов в виде связных списков устраняются при хранении указателей на следующие блоки не в блоках, а в таблице отображения файлов (FAT, File Allocation Table), загружаемой в память (рис. 4.12.). Этой схемы придерживаются многие операционные системы: MS-DOS, OS/2, MS Windows и другие. Запись в директории содержит только ссылку на первый блок. Далее при помощи таблицы FAT можно локализовать блоки файла независимо от его размера. В тех строках таблицы, которые соответствуют последним блокам, обычно записывается некоторое граничное значение, например EOF. Метод позволяет использовать для данных весь блок и случайный доступ к любому блоку значительно проще. Хотя для получения доступа к конкретному блоку и требуется проследовать по цепочке ссылок до ссылки на требуемый блок, однако вся цепочка ссылок хранится в памяти, поэтому для следования по ней не требуются дополнительные дисковые операции.
Главное достоинство: по таблице FAT можно судить о физическом соседстве блоков, располагающихся на диске, и при выделении нового блока можно легко найти свободный блок диска, находящийся поблизости от других блоков данного файла. Основной недостаток: необходимость хранения в памяти таблицы FAT, которая имеет значительный размер.
 |
Метод 4: индексные узлы (i - узлы). Наиболее распространенный метод выделения файлу блоков диска – это связать с каждым файлом таблицу индексных узлов (index node), содержащую атрибуты файла и адреса блоков файла (рис. 4.13.). Каждый файл имеет свой индексный блок. Запись в директории, относящаяся к файлу, содержит адрес индексного блока. При наличии i -узла можно найти все блоки файла. Индексирование поддерживает прямой доступ к файлу, без ущерба от внешней фрагментации.
Преимущество данного метода заключается в том, что каждый конкретный i -узел должен находиться в памяти только в случае открытия файла и его размер значительно меньше размера таблицы FAT. Индексированное размещение широко распространено и поддерживает как последовательный, так и прямой доступ к файлу.
Обычно применяется комбинация одноуровневых и многоуровневых индексов. Первые несколько адресов блоков файла хранятся в индексном узле. Для маленьких файлов индексный узел хранит всю необходимую информацию об адресах блоков диска. Для больших файлов один из адресов индексного узла указывает на блок косвенной адресации. Данный блок содержит адреса дополнительных блоков диска. Если этого недостаточно, используется блок двойной косвенной адресации, который содержит адреса дополнительных блоков косвенной адресации. Если и этого не хватает, используется блок тройной косвенной адресации.
Данную схему используют файловые системы HPFS (OS/2), NTFS (Windows), ufs (Unix) и др. Такой подход позволяет при фиксированном, относительно небольшом размере индексного узла поддерживать работу с файлами, размер которых может меняться от нескольких байтов до нескольких гигабайтов. Для маленьких файлов используется только прямая адресация, которая обеспечивает максимальную производительность.
 |
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 4191; Нарушение авторских прав?; Мы поможем в написании вашей работы!