КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Понятие программных нитей и wavefront
|
|
|
|
Одним из фундаментальных для архитектуры графических процессоров AMD является понятие wavefront. Дело в том, что все графические процессоры (и NVIDIA, и AMD) архитектурно устроены таким образом, чтобы обрабатывать одновременно множество потоков инструкций (нитей), количество которых может исчисляться тысячами. Собственно, в этом заключается главная особенность графических процессоров — возможность параллельной обработки огромного множества программных нитей. Однако эффективная обработка таких нитей возможна только в том случае, если все нити графической программы, осуществляя параллельную обработку данных, в целом движутся параллельным курсом по коду программы, причем для всех нитей в конкретный момент времени реализуется одна и та же операция, но с разными данными. Так вот, графические процессоры AMD предыдущего поколения устроены таким образом, что каждый мини-процессор (SIMD Engine) может выполнять только одну операцию (инструкцию с одним программным адресом), но с разными операндами. То есть все 16 SPU в блоке SIMD Engine процессора, к примеру, Cayman выполняют одну и ту же инструкцию. Например, это может быть инструкция сложения содержимого двух регистров: она одновременно выполняется всеми SPU блока SIMD Engine, но регистры берутся разные. Собственно, отсюда и название SIMD (Single Instruction, Multiple Data — одна инструкция, множество данных).
Напомним, что каждый SPU содержит четыре или пять (в зависимости от модели графического процессора) исполнительных блоков (ALU), что позволяет каждому SPU одновременно обрабатывать четыре или пять нитей.
При параллельной обработке программных нитей графических программ такой подход себя оправдывает и позволяет достаточно равномерно загружать все исполнительные блоки. Если же в результате ветвления в программе нити расходятся в своем пути исполнения кода, то происходит так называемая сериализация. В этом случае используются не все исполнительные блоки в SIMD Engine, поскольку нити подают на исполнение различные инструкции, а SIMD Engine может исполнять только инструкцию с одним адресом. Естественно, в этом случае производительность снижается.
Если рассматривать параллельно расположенные нити, то перпендикулярный срез 64 нитей, соответствующих инструкции с одним программным адресом, называется wavefront (волновой фронт нитей) — рис. 2. Понятно, что в графических программах операции с одним программным адресом могут соответствовать не 64 нити, а существенно больше, то есть инструкция с одним программным адресом может порождать несколько wavefront.
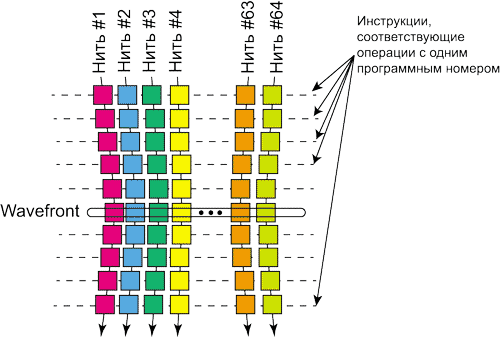
Рис. 2. Понятие wavefront
Понятие wavefront очень важно, поскольку такой волновой фронт инструкций является минимальной порцией инструкций для выполнения на SIMD Engine.
Идеальной является ситуация, когда все нити выполняются параллельно (синхронно), то есть во всех нитях исполняется одна и та же инструкция. Если же происходит сериализация нитей, то, образно говоря, нужные нити подтормаживаются при выполнении до выравнивания всех нитей по номеру инструкции. При этом исполняться может даже одна нить, но это займет столько же времени, сколько и выполнение всего волнового фронта нитей. В «железе» это реализовано с помощью маскирования определенных нитей, то есть инструкции формально исполняются, но результаты их выполнения никуда не записываются и в дальнейшем не используются.
В графических процессорах AMD, начиная с Radeon HD серии 2000 и заканчивая Radeon HD серии 6000, каждый SIMD Engine обрабатывает одновременно инструкции из нескольких wavefront (по количеству ALU в SPU). В частности, в графических процессорах Radeon HD серии 6000 каждый SIMD Engine в лучшем случае может одновременно исполнять четыре wavefront, что соответствует четырем ALU в каждом SPU. В данном случае можно провести аналогию с рядами и столбцами матриц. Набор инструкций можно рассматривать как матрицу, ряды которых образуют wavefront (горизонтальный срез), а столбцы — нити инструкций. Так вот, набор из 64 ALU в каждом SIMD Engine также можно рассматривать как матрицу из 16 столбцов (по количеству SPU) и четырех рядов (по количеству ALU в каждом SPU).
Каждый такой ряд, содержащий 16 ALU, выполняет инструкции из одного wavefront, а всего в SIMD Engine одновременно может выполняться четыре wavefront. Но главное, что при этом исполняется только одна программная инструкция с разными данными.
Часто возникает ситуация, когда на SIMD Engine последовательно выполняется последовательность wavefront и некоторые из них являются зависимыми от других. Собственно, это типичная ситуация, поскольку wavefront — это лишь объединение (горизонтальный срез) из 64 отдельных нитей инструкций. А ведь инструкции в таких нитях могут зависеть друг от друга. Если в нити встречаются такие зависимые инструкции, то зависимым становится весь wavefront, поскольку, как уже отмечалось, весь набор инструкций, образующих wavefront, должен выполняться одновременно.
Рассмотрим в качестве упрощенного примера серию из 15 wavefront, которые будут иметь буквенные обозначения: A, B, C, D, E, F, G, H, I, J, K, L, M, N и O. Пусть wavefront С зависит от В (то есть wavefront В не может быть исполнен, пока не выполнен wavefront С). Далее, пусть wavefront F зависит от wavefront E, wavefront G — от F, а wavefront L — от K (рис. 3).
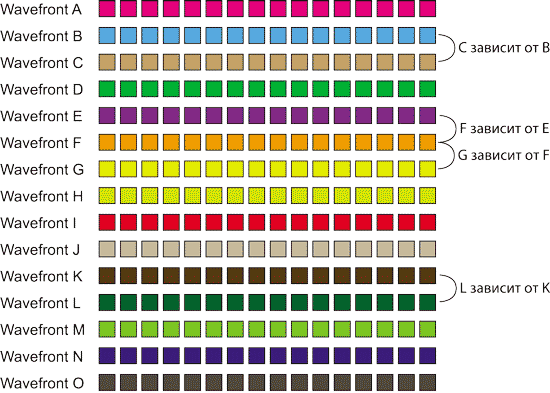
Рис. 3. Последовательность из 15 wavefront с зависимостями
В первом такте SIMD Engine сможет исполнять одновременно инструкции из wavefront A и B, поскольку они не зависят друг от друга. При этом из четырех ALU в каждом SPU будут задействованы только два, поскольку wavefront C не может быть выполнен, пока не выполнен wavefront B (рис. 4).
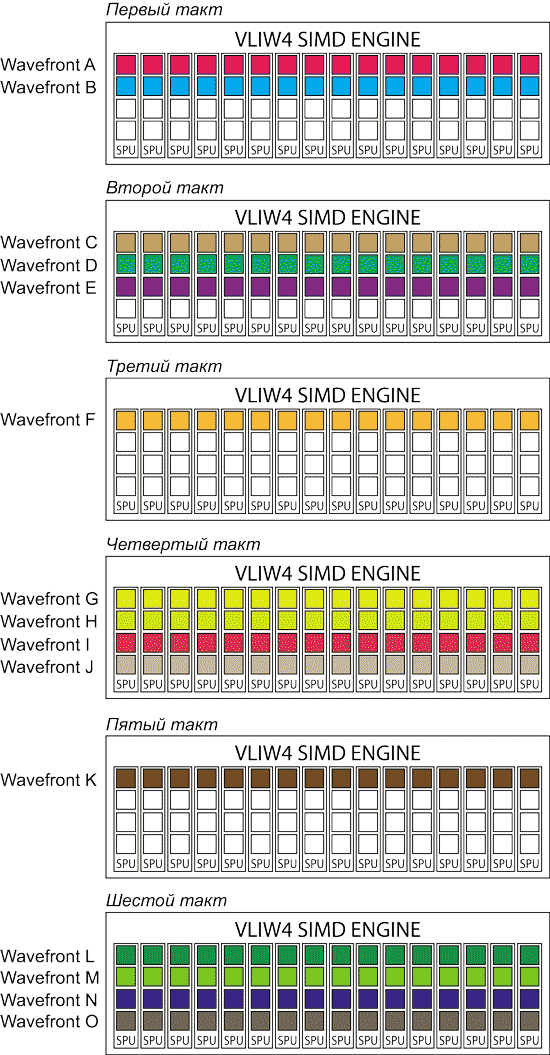
Рис. 4. Выполнение последовательности 15 wavefront с зависимостями
на SIMD Engine с архитектурой VLIW4
Во втором такте в SIMD Engine могут выполняться одновременно wavefront C, D и E. Соответственно в каждом SPU будут задействоваться три ALU.
В третьем такте в SIMD Engine может исполняться только wavefront F, поскольку, во-первых, он должен быть выполнен после wavefront E, а во-вторых, wavefront G должен быть выполнен после wavefront F. Соответственно в каждом SPU будет задействоваться только один ALU.
В четвертом такте могут быть выполнены wavefront G, H, I и J (все они не зависят друг от друга). Таким образом, в каждом SPU будут задействованы все четыре ALU.
В следующем такте выполняется только один wavefront K, поскольку следующий за ним wavefront L зависит от wavefront K и не может исполняться одновременно с ним.
Ну и в последнем, шестом такте могут одновременно выполняться wavefront L, M, N и O.
Таким образом, для выполнения всех 15 wavefront c учетом зависимостей потребовалось шесть тактов. Понятно, что если бы зависимости отсутствовали, то для выполнения всех wavefront потребовалось бы четыре такта.
|
|
|
|
|
Дата добавления: 2015-07-13; Просмотров: 654; Нарушение авторских прав?; Мы поможем в написании вашей работы!