КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Общие принципы работы систем речевого общения
|
|
|
|
План
Алгоритми розпізнавання інформації
1. Классификация систем речевого общения
2. Общие принципы работы систем речевого общения
Задание:
Вариант 1. В распечатанном варианте самостоятельной работы подчеркнуть основной материал, ответить на контрольные вопросы. Скрепить листы. Подписать работу
Вариант 2. Составить опорный конспект в тетради для СР. Ответить на контрольные вопросы.
Классификация систем речевого общения
Системы речевой обработки сигналов обычно делят на системы распознавания и системы синтеза речи.
Распознавание речи (иногда называемое распознаванием голоса) – это процесс преобразования акустического сигнала в некую абстрактную форму разговорного языка. Он состоит из этапа преобразования голоса в текст и из этапа автоматической интерпретации семантики (смысла) речи. Распознаванием голоса часто называется также идентификация говорящего по голосу. Такие системы используются, например, в системах безопасности.
Основанием дальнейшей классификации систем речевой обработки сигналов могут являться, например, вид и сложность решаемых задач. Так если при синтезе речи необходимо воспроизводить ограниченное число фраз, их достаточно просто записать и реализовать механизм включения их воспроизведения в нужный момент. Если же число фраз велико или вообще не ограничено, такие методы не приносят результат;
Системы распознавания по сложности обычно делят на следующие группы:
- системы автоматического распознавания изолированных слов. То есть система должна распознавать пословно произносимые человеком команды;
- системы автоматического распознавания слитной речи. То есть система должна уметь выделять слова в естественном частично слитном потоке человеческой речи;
- системы понимания речи. То есть системы, которые наделены элементами интеллекта, что позволяет, во-первых, на основе смыслового анализа более правильно выделять слова в потоке речи, а, во-вторых, сохранять информацию в некой базе знаний, откуда она может быть легко извлечена для решения определенных интеллектуальных задач.
Также системы распознавания речи могут быть классифицированы по:
- размеру словаря. Под словарем понимается набор хранимых в системе единиц речи (например, слов, слогов, фонем-звуков);
- качеству распознавания (приемлемым считается процент ошибки распознавания не более 5 процентов);
- по способу обработки входного сообщения;
- по степени зависимости от диктора.
Размер словаря системы распознавания голоса влияет на степень сложности, требования к процедурам обработки и точность системы. Одним системам для работы необходимо всего несколько слов (например, голосовые команды), а другим требуется большой словарь (например, диктофонные системы). Если единицей словаря является слово, то по объему словаря системы делятся обычно делятся на:
- системы с очень большим словарем – десятки тысяч слов;
- системы с большим словарем – тысячи слов;
- системы со средним словарем – сотни слов;
- системы с маленьким словарем – до сотни слов.
Качество распознавания на современном уровне, кроме низкого процента ошибки распознавания и надлежащего размера словаря предполагает независимость распознавания от диктора и способность обрабатывать непрерывную речь, то есть возможность пользователям говорить естественно (непрерывно), не делая пауз между словами.
Распознавание речи, зависимое от диктора подразумевает, что пользователь должен сначала научить систему распознавания своему голосу и только после этого система сможет функционировать. Независимое от диктора распознавание речи означает, что система способна распознать любую речь, независимо от того, кто говорит. Голосозависимые системы предназначены для одного конкретного пользователя. Такие системы обычно проще разрабатывать, они дешевле и работают более точно, хотя и менее гибки, чем независимые от диктора программы. Соответственно голосонезависимые программы способны работать с широким кругом пользователей и обладают болев высокой гибкостью, хотя и значительно более высокой ценой и несколько худшим качеством распознавания.
Распознавание речи происходит так: при помощи микрофона и оцифровывающего устройства (например, звуковой карты компьютера) и машинной обработки речевой сигнал фиксируется. Затем цифровой сигнал разбивается на неделимые интервалы, каковыми могут быть фонемы (элементарные звуки речи), слоги, слова. На основе контекста, шаблонов речи, некоторых акустических признаков слова объединяются в логические единицы - фразы и предложения. Затем эти логические единицы анализируются и переводятся в действительные команды или сообщения, которые понятны конкретной программе.
Системы синтеза речи, кроме сложности и величины словаря, обычно классифицируются по:
- уровню кодирования – то есть по тому, что является единицей, хранимой в словаре, - слово, слог или фонема (отдельный звук);
- методу кодирования. Существуют в общем случае два метода кодирования: непосредственное хранение фрагмента речевого сигнала, соответствующего единице (слову, слогу или звуку-фонеме) словаря (волновой метод) и хранение параметров речевого сигнала вместо него самого (параметрический метод). Второй метод позволяет гибко регулировать параметры выходящего речевого сигнала и значительно снижать необходимое для хранения словаря и самого сигнала количество памяти, но в некоторой степени снижает качество синтезируемой речи.
Почти все методы для речевого синтеза и распознавания основаны на модели речи человека, показанной на рисунке.
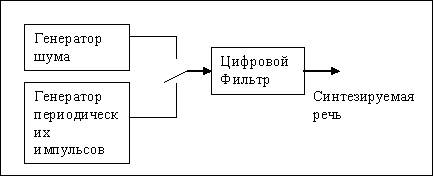
Процесс распознавания речи включает в себя несколько этапов. На каждом из этапов для обработки речевого сигнала используется целый ряд различных подходов. Итак, этапы распознавания речи следующие:
1. Получение речевого сигнала и его предварительная обработка;
2. Распознавание фонем и слов;
3. Понимание речи.
Для распознавания фонем, слогов и слов используются такие методы, как скрытые марковские модели, искусственные нейронные сети или их комбинация. Об этих методах будет довольно подробно рассказано в последующих главах.
Возможно, самое сложное, это понять речь. На этом этапе последовательности слов должны быть преобразованы в представления о том, что хотел сказать говоривший.
Надо заметить, что живая человеческая речь не является полным аналогом письменной речи. В частности, если на письме слова, как правило, разделяются пробелом, то в живой речи паузы между словами может не быть вообще, эта пауза может быть наоборот очень большой. Знаки пунктуации, необходимые при письме и помещаемые на бумагу тем же способом, что и буквы, в живой речи не обозначаются каким-либо звуком, а угадываются по интонации или даже просто исходя из смысла сказанного. Кроме того, сами звуки не всегда имеют четкое и однозначное соответствие в письменной речи. Например, бука «о» в слове “коза” звучит как «а», в то время как в слове «рот» эта же буква звучит как «а». Мы, конечно, знаем, что в русском языке, как правило (если не говорить о вологодском наречии), буква «о» звучит как «о» под ударением и «а» в безударных слогах, но мы должны это объяснить и компьютерной системе, синтезирующей или распознающей речь. Поэтому на входе синтезирующей системы или на выходе системы распознавания, работающих со слогами или фонемами, как правило, должна быть подсистема транскрибирования, то есть нечто, что будет переводить письменный текст в набор звуков и наоборот – набор звуков в письменный текст.
Хорошо известно, что понимание речи опирается на огромный объем лингвистических и культурных знаний. Большая часть систем распознавания голоса учитывает при этом знания о естественном языке и конкретный контекст.
Задача, связанная с распознаванием речи – распознавание говорящего (диктора). Есть два пути к этому –идентификация и верификация говорящего. Идентификация – это поиск во множестве фраз образца, соответствующего манере речи говорящего. Верификация – это определение идентичности говорящего по заранее определенным параметрам речевого сигнала-образца. Технология распознавания диктора позволяет использовать голос для обеспечения контроля доступа; например, телефонный доступ к банковским услугам, к базам данных, к системам электронной торговли, голосовой почте, секретному оборудованию.
На сегодняшний день основными направлениями развития систем речевого общения видятся следующие:
- минимизация необходимого словаря;
- улучшения качества распознавания и синтеза непрерывной речи;
- передача и распознавание интонации, акцентов, особенностей произношения, а также распознавание речи с «нестандартным» произношением;
- выделение смысловой составляющей распознанного текста.
Контрольные вопросы
1. Какие проблемы могут возникнуть при распознавании речи?
2. На что влияет размер словаря системы?
3. Как могут быть классифицированы системы распознавания речи?
|
|
|
|
Дата добавления: 2015-07-13; Просмотров: 516; Нарушение авторских прав?; Мы поможем в написании вашей работы!