КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Построение нечеткого дерева решений
|
|
|
|
Практические применения
Интернет ресурс
Статья
4. Житко В.А. Технология проектирования ЕЯ-интерфейса. статья 2011 год;
5. http://speech-soft.ru/info/magasin_speechtechnology
6. http://www.frolov-lib.ru/books/hi/index.html
Приложение
Задание: Банк. Руководству необходимо определить возможность выдачи кредита для клиента.
Необходимо построить нечеткое дерево решений, с помощью которого определить рейтинг выдачи кредита для клиента, который проживает в регионе 20 лет, и доход его составляет 40000 ден.единиц.
В таблице 2 представлены данные о семи клиентах банка: проживание в регионе (в годах), доход (в денежных единицах) и рейтинг выдачи ему кредита (определяется экспертом).
Табл.2 – Данные о клиентах банка
| № | ФИО клиента банка | Проживание в регионе | Доход | Рейтинг |
| D1 | Иванов Петр Сергеевич | 0,0 | ||
| D2 | Словянский Кузьма Петрович | 0,1 | ||
| D3 | Харичев Федор Михайлович | 0,2 | ||
| D4 | Сидоркин Станислав Семенович | 0,4 | ||
| D5 | Фомкина Екатерина Сергеевна | 0,5 | ||
| D6 | Любушкина Агния Борисовна | 0,8 | ||
| D7 | Степанов Семен Иванович | 1,0 |
Определим лингвистические переменные.
1. x1: «проживание в регионе»
X: [0, 100];
Т(х): «временно», «продолжительно», «постоянно»;
G: «достаточно», «недостаточно»;
М: заданно таблично (таблица 3).
2. x2: «доход»
X: [0, 100 000];
Т(х): «малый», «средний», «высокий»;
G: «достаточно», «недостаточно»;
М: заданно таблично (таблица 4).
Табл.3 – Табличное представление семантического правила для x1
| № | Проживание в регионе | ||
| временно | продолжительно | постоянно | |
| D1 | 0,8 | 0,1 | 0,1 |
| D2 | 0,2 | 0,3 | 0,5 |
| D3 | 0,9 | 0,1 | 0,0 |
| D4 | 0,6 | 0,0 | 0,4 |
| D5 | 0,0 | 0,7 | 0,3 |
| D6 | 0,0 | 1,0 | 0,0 |
| D7 | 0,0 | 0,0 | 1,0 |
Табл.4 – Табличное представление семантического правила для x2
| № | Доход | ||
| малый | средний | высокий | |
| D1 | 1,0 | 0,0 | 0,0 |
| D2 | 0,8 | 0,2 | 0,0 |
| D3 | 0,3 | 0,3 | 0,4 |
| D4 | 0,0 | 0,0 | 1,0 |
| D5 | 0,5 | 0,5 | 0,0 |
| D6 | 0,0 | 1,0 | 0,0 |
| D7 | 0,0 | 0,0 | 1,0 |
Общий вид функции принадлежности лингвистических переменных показан на рисунке 1.
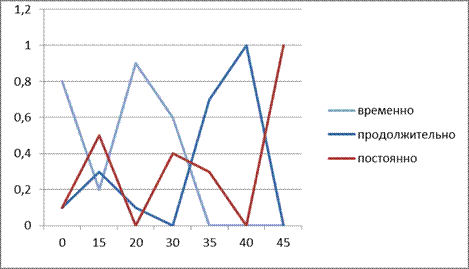

Рис 1 – Графики функций принадлежности
Необходимо найти значение общей энтропии:
Рда = 0 + 0,1 + 0,2 + 0,4 + 0,5 + 0,8 + 1,0 = 3
Рнет =1 + 0,9 + 0,8 + 0,6 + 0,5 + 0,2 + 0 = 4
Р = Рда + Рнет = 3 + 4 = 7.
Расcчитаем E(SN), воспользовавшись формулой:
E(SN) = -  · log 2
· log 2  ;
;
E(SN) = -  log 2 -
log 2 -  log 2 ≈ 0,985 бит.
log 2 ≈ 0,985 бит.
Теперь рассчитаем E(SN , проживание в регионе, временно).
Рдавременно = min(0; 0,8) + min(0,1; 0,2) + min(0,2; 0,9) + min(0,4; 0,6) + min(0,5; 0) + min(0,8; 0) + min(1; 0) = 0 + 0,1 + 0,2 + 0,4 + 0 + 0+ 0 = 0,7.
Рнетвременно = min(1; 0,8) + min(0,9; 0,2) + min(0,8; 0,9) + min(0,6; 0,6) + min(0,5; 0) + min(0,2; 0) + min(0; 0) = 0,8 + 0,2 + 0,8 + 0,6 + 0 + 0 + 0 = 2,4.
Рвременно = 0,7 + 2,4 = 3,1
Рис. 2 – Графики функций принадлежности
E(проживание в регионе, временно) = -  log 2 –
log 2 –  log 2 ≈ 0,770 бит.
log 2 ≈ 0,770 бит.
Рассчитаем E(SN , проживание в регионе, продолжительно).
Рдапродолжительно = min(0; 0,1) + min(0,1; 0,3) + min(0,2; 0,1) + min(0,4; 0) + min(0,5; 0,7) + min(0,8; 1) + min(1; 0) = 0 + 0,1 + 0,1 + 0 + 0,5 + 0,8+ 0 = 1,5.
Рнетпродолжительно = min(1; 0,1) + min(0,9; 0,3) + min(0,8; 0,1) + min(0,6; 0) + min(0,5; 0,7) + min(0,2; 1) + min(0; 0) = 0,1 + 0,3 + 0,1 + 0 + 0,5 + 0,2 + 0 = 1,2.
Р продолжительно = 1,5 + 1,2 = 2,7.
E(проживание в регионе, продолжительно) = -  log 2 –
log 2 – 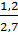 log 2 ≈ 0,990 бит.
log 2 ≈ 0,990 бит.
Рассчитаем E(SN , проживание в регионе, постоянно).
Рдапостоянно = min(0; 0,1) + min(0,1; 0,5) + min(0,2; 0) + min(0,4;0, 4) + min(0,5; 0,3) + min(0,8; 0) + min(1; 1) = 0 + 0,1 + 0 + 0,4 + 0,3 + 0+ 1 =1,8.
Рнетпостоянно = min(1; 0,1) + min(0,9; 0,5) + min(0,8; 0) + min(0,6; 0,4) + min(0,5; 0,3) + min(0,2; 0) + min(0; 1) = 0,1 + 0,5 + 0 + 0,4 + 0,3 + 0 + 0 = 1,3.
Р постоянно = 1,8 + 1,3 = 3,1.
E(проживание в регионе, постоянно) = -  log 2 –
log 2 –  log 2 ≈ 0,980 бит.
log 2 ≈ 0,980 бит.
Результат сведем в таблицу 5.
Табл.5 – Итоги расчетов для x1
| временно | продолжительно | постоянно | |
| Р да | 0,7 | 1,5 | 1,8 |
| Р нет | 2,4 | 1,2 | 1,3 |
| Е, бит | 0,770 | 0,990 | 0,980 |
Найдем энтропию, воспользовавшись формулой:
Е(SN, A) =  · E(Sμ i);
· E(Sμ i);
Е(SN, проживание в регионе) = 
 0,770 +
0,770 + 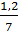 · 0,990 +
· 0,990 +  · 0,980 = 0,613 бит.
· 0,980 = 0,613 бит.
Рассчитаем прирост информации для данного атрибута.
G(SN, проживание в регионе) = 0,985 – 0,613 = 0,372 бит.
Рассчитаем Е(SN, доход, малый)
Рдамалый = min(0; 1) + min(0,1; 0,8) + min(0,2; 0,3) + min(0,4;0) + min(0,5; 0,5) + min(0,8; 0) + min(1; 0) = 0 + 0,1 + 0,2 + 0 + 0,5 + 0 + 0 =0,8.
Рнетмалый = min(1; 1) + min(0,9; 0,8) + min(0,8; 0,3) + min(0,6; 0) + min(0,5; 0,5) + min(0,2; 0) + min(0; 1) = 1 + 0,8 + 0,3 + 0 + 0,5 + 0 + 0 = 2,6.
Р малый = 0,8 + 2,6 = 3,4.
Е(доход, малый) = -  log 2 –
log 2 –  log 2 ≈ 0,785 бит.
log 2 ≈ 0,785 бит.
Рассчитаем Е(SN, доход, средний)
Рдасредний = min(0; 0) + min(0,1; 0,2) + min(0,2; 0,3) + min(0,4;0) + min(0,5; 0,5) + min(0,8; 1) + min(1; 0) = 0 + 0,1 + 0,2 + 0 + 0,5 + 0,8 + 0 =1,6.
Рнетсредний = min(1; 0) + min(0,9; 0,2) + min(0,8; 0,3) + min(0,6; 0) + min(0,5; 0,5) + min(0,2; 1) + min(0; 0) = 0 + 0,2 + 0,3 + 0 + 0,5 + 0,2 + 0 = 1,2.
Р средний = 1,6 + 1,2 = 2,8.
Е(доход, средний) = -  log 2 –
log 2 –  log 2 ≈ 0,985 бит.
log 2 ≈ 0,985 бит.
Рассчитаем Е(SN, доход, высокий)
Рдавысокий = min(0; 0) + min(0,1; 0) + min(0,2; 0,4) + min(0,4;1) + min(0,5; 0) + min(0,8; 0) + min(1; 1) = 0 + 0 + 0,2 + 0,4 + 0 + 0 + 1 =1,6.
Рнетвысокий = min(1; 0) + min(0,9; 0) + min(0,8; 0,4) + min(0,6; 1) + min(0,5; 0) + min(0,2; 0) + min(0; 1) = 0 + 0 + 0,4 + 0,6 + 0 + 0 + 0 = 1.
Р высокий = 1,6 + 1 = 2,6.
Е(доход, высокий) = -  log 2 –
log 2 – 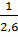 log 2 ≈ 0,961 бит.
log 2 ≈ 0,961 бит.
Результат сведем в таблицу 6.
Табл.6 – Итоги расчетов для x2
| малый | средний | высокий | |
| Р да | 0,8 | 1,6 | 1,6 |
| Р нет | 2,6 | 1,2 | |
| Е, бит | 0,785 | 0,985 | 0,961 |
Найдем энтропию, воспользовавшись формулой:
Е(SN, A) = · E(Sμ i);
Е(SN, доход) = 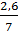 0,785 + · 0,985 +
0,785 + · 0,985 +  · 0,961 = 0,596 бит.
· 0,961 = 0,596 бит.
Рассчитаем прирост информации для данного атрибута.
G(SN, доход) = 0,985 – 0,596 = 0,389 бит.
Максимальный прирост информации обеспечивает атрибут «доход», следовательно, разбиение начнется с него.
На следующем шаге алгоритма необходимо для каждой записи рассчитать степень принадлежности к каждому новому узлу по формуле:
μN  (eA) = min(μN (Dk), μN (Dk, aj))
(eA) = min(μN (Dk), μN (Dk, aj))
Результат представлен в таблице 7.
К узлам [проживание в регионе = временно и доход = высокий], [проживание в регионе = временно и доход = средний], [проживание в регионе = временно и доход = малый] не принадлежит ни одна запись, поэтому они удаляются из дерева.
Для каждого узла находятся коэффициенты РiN.
1. Узел [проживание в регионе = временно и доход = малый]:
Рда = min(0; 0,8) + min(0,1; 0,2) + min(0,2; 0,3) + min(0,4;0) + min(0,5; 0) + min(0,8; 0) + min(1; 0) = 0 + 0,1 + 0,2 + 0 + 0 + 0 + 0 =0,3.
Рнетвысокий = min(1; 0,8) + min(0,9; 0,2) + min(0,8; 0,3) + min(0,6; 0) + min(0,5; 0) + min(0,2; 0) + min(0; 0) = 0,8 + 0,2 + 0,3 + 0 + 0 + 0 + 0 = 1,3.
2. Узел [проживание в регионе = продолжительно и доход = малый]:
Рда = min(0; 0,1) + min(0,1; 0,3) + min(0,2; 0,1) + min(0,4; 0) + min(0,5; 0,5) + min(0,8; 0) + min(1; 0) = 0 + 0,1 + 0,1 + 0 + 0,5 + 0 + 0 =0,7.
Рнетвысокий = min(1; 0,1) + min(0,9; 0,3) + min(0,8; 0,1) + min(0,6; 0) + min(0,5; 0,5) + min(0,2; 0) + min(0; 0) = 0,1 + 0,3 + 0,1 + 0 + 0,5 + 0 + 0 = 1.
3. Узел [проживание в регионе = временно и доход =средний]:
Рда = min(0; 0) + min(0,1; 0,2) + min(0,2; 0,3) + min(0,4; 0) + min(0,5; 0) + min(0,8; 0) + min(1; 0) = 0 + 0,1 + 0,2 + 0 + 0 + 0 + 0 =0,3.
Рнетвысокий = min(1; 0) + min(0,9; 0,2) + min(0,8; 0,3) + min(0,6; 0) + min(0,5; 0) + min(0,2; 0) + min(0; 0) = 0 + 0,2 + 0,3 + 0 + 0 + 0 + 0 = 0,5.
4. Узел [проживание в регионе = продолжительно и доход = средний]:
Рда = min(0; 0) + min(0,1; 0,2) + min(0,2; 0,1) + min(0,4; 0) + min(0,5; 0) + min(0,8; 1) + min(1; 0) = 0 + 0,1 + 0,1 + 0 + 0 + 0,8 + 0 =1.
Рнетвысокий = min(1; 0) + min(0,9; 0,2) + min(0,8; 0,1) + min(0,6; 0) + min(0,5; 0) + min(0,2; 1) + min(0; 0) = 0 + 0,2 + 0,1 + 0 + 0 + 0,2 + 0 = 0,5.
5. Узел [проживание в регионе = постоянно и доход = высокий]:
Рда = min(0; 0) + min(0,1; 0) + min(0,2; 0) + min(0,4; 0,4) + min(0,5; 0) + min(0,8; 0) + min(1; 1) = 0 + 0 + 0 + 0,4 + 0 + 0 + 1 =1,4.
Рнетвысокий = min(1; 0) + min(0,9; 0) + min(0,8; 0) + min(0,6; 0,4) + min(0,5; 0) + min(0,2; 0) + min(0; 1) = 0 + 0 + 0 + 0,4 + 0 + 0 + 1 = 1.
Полученное дерево представлено на рисунке 2.
Теперь определим кредитный рейтинг для клиента, проживающего в регионе 20 лет, и с доходом 40 000.
За положительный исход в данной задаче принято одобрение в выдаче кредита, поэтому хда =1,0, хнет = 0,0.
Табл.7 – Принадлежности записей новым узлам дерева
| Доход | малый | средний | высокий | ||||||
| Проживание в регионе | временно | продолжительно | постоянно | временно | продолжительно | постоянно | временно | продолжительно | постоянно |
| D1 | 0,8 | 0,1 | 0,1 | ||||||
| D2 | 0,2 | 0,2 | 0,5 | 0,2 | 0,2 | 0,2 | |||
| D3 | 0,3 | 0,1 | 0,3 | 0,1 | 0,4 | 0,1 | |||
| D4 | 0,6 | 0,4 | |||||||
| D5 | 0,5 | 0,3 | 0,5 | 0,3 | |||||
| D6 | |||||||||
| D7 |
Новый клиент принадлежит к двум узлам: [проживание в регионе = продолжительно и доход = малый] и [проживание в регионе = продолжительно и доход = средний], со степенями 0,8 и 0,2 соответственно. Подставляя полученные значения в формулу:
δj = 
Рассчитываем кредитный рейтинг:
δ =  0,458
0,458

Рда = 1,6 Рда = 1,6
Рнет = 1,2 Рнет = 1
Рда = 0,8
Рнет = 2,6
 |  |  | |||||||
 | |
Рда = 0,3 Рда = 0,7 Рда = 0,3 Рда = 1 Рда = 1,4
Рнет = 1,3 Рнет = 1 Рнет = 0,5 Рнет = 0,5 Рнет = 1
Рис. 2 – Графическая иллюстрация полученного нечеткого дерева решений
В итоге мы получили кредитный рейтинг, равный 0,458.
Он означает, что степень принадлежности записи к тому, что кредит клиенту будет выдан, равна 0,458, а к невыдаче - 0,542. Следовательно, этому клиенту банком будет отказано.
Создание нечѐткой экспертной системы в пакете CubiCalc
CubiCalc 2.0 – разработка фирмы HyperLogic, является одним из наиболее мощных средств создания систем на основе нечѐткой логики. Пакет содержит интерактивную оболочку для разработки нечѐтких экспертных систем и систем управления.
Фактически пакет CubiCalc 2.0 представляет собой своего рода экспертную систему, в которой пользователь задает набор правил типа «если-то», а система на основе этих правил пытается адекватно реагировать на параметры 38 текущей ситуации. Отличие данного продукта от обычных экспертных систем состоит в том, что вводимые правила содержат нечѐткие величины, т.е. имеют вид «если X принадлежит А, то Y принадлежит B», где A и В – нечѐткие множества. Аппарат нечѐткой логики, заложенный в CubiCalc, дает возможность оперировать нечѐткими понятиями как точными и строить на их основе целые логические системы.
Процесс разработки нечѐткой экспертной системы в пакете CubiCalc начинается с определения переменных, которые будут использоваться в проекте: Project → Variables → New (см.рис.2.2)
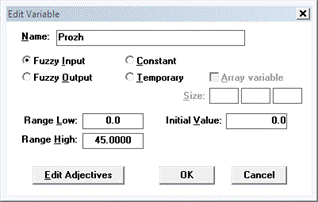
Рис. 2.2- Окно определения переменных
В CubiCalc доступны несколько типов переменных:
1) Fuzzy Input – входная переменная, на области значения которой задаются нечѐткие множества, используемые в левой части правил вывода.
2) Fuzzy Output – результат работы системы нечѐткого логического вывода, определяющей нечѐткие множества, используемые в правой части правил вывода.
3) Constant – переменная с фиксированным значением.
4) Temporary – переменная, принимающая действительные значения (аналогичные значениям типа «float»).
Объявляем первую переменную х1, как Prozh- проживание в регионе (путем ввода в поле name). Задаем атрибуты переменной: ее тип (Fuzzy Input), диапазон изменения ее значений [0, 45] (параметры Range Low – нижняя граница диапазона, Range High – верхняя граница), а также начальное значение (Initial Value) равное 0. После нажатия кнопки «ОК» переменная «Prozh» появляется в списке переменных (см. рис. 2.3).
Аналогично создадим вторую входную переменную – Doxod с диапазоном значений [0, 60000].
Наименование выходной переменной, на основании которой принимается решение о рейтинге выдачи кредита для клиента, задается как Rang (диапазон изменения значений – [0, 1]), тип этой переменной зададим (Fuzzy Output), а так же начальное значение Initial Value выставим равное 0.

Рис.2.3 - Список переменных
Далее необходимо задать характеристики всех трех переменных: Project → Adjective editor
Выбрав переменную Prozh в окне «Adjectives for variables», нажмите кнопку Edit. Здесь для каждой входной и выходной переменной нужно поставить функций принадлежности Adjective → Change List → New. В появившемся окне «Create Adjective(s)» зададим следующие параметры: количество функций принадлежности (Number) равное 3; вид функции принадлежности (Shape) – Trapezoid; ширину основания (base width), равную 45,0(см.рис. 2.4)

Рис.2.4
В окне «Edit Adjective List» присвоим наименования – Small, Medium, Large соответственно малому, среднему и высокому доходу.
Для переменной Prozh присвоим наименования Vrem(временно), Prod(продолжительно), Post(постоянно) см.рис.2.5.
Для переменной Rang присвоим наименования Small (низкий), Medium(средний), Large(высокий).

Рис.2.5
Далее необходимо определить набор правил, которые связывают входные переменные с выходными. Для этого в редакторе правил вывода (Project → Rules) определим(см.рис.2.6):
IF Prozh is Vrem AND Doxod is Small
THEN Rang is Small;
IF Prozh is Prod AND Doxod is Large
THEN Rang is Large;
IF Prozh is Prod AND Doxod is Medium
THEN Rang is Medium;
IF Prozh is Post AND Doxod is Small
THEN Rang is Medium;
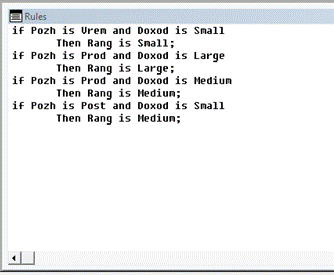
Рис.2.6
Следующими этапами выполнения проекта в CubiCalc являются так называемые предобработка и постобработка. В процессе предобработки (Project → Preprocessing) определяются входные данные. Для этого используется функция field(), которая возвращает данные отдельного поля текущей записи.
Откройте Preprocessing Editor (Редактор предобработки) и введите ниже- следующие инструкции:
Prozh = field(1);
Doxod = field(2);
check = field(3);
В рассматриваемой нечѐткой системе всего два входа, третья переменная (check) содержит «правильный ответ». Таким образом, мы можем посчитать количество ошибок, совершенных системой, в классификации выдачи кредита клиенту.
При постобработке (Project → Postprocessing) задается метод автоматической оценки эффективности системы. Необходимо посчитать количество сделанных системой ошибок и вывести сумму в конце запуска. Чтобы обнаружить ошибку классификации в постобработке, необходимо сравнить выходную переменную с информацией в переменной check файла данных. Чтобы это сделать, вставьте нижеследующие инструкции в окно редактора:
If (rate <> check) errors += 1;end
If (endoffile=TRUE) call message(errors); end
Эти инструкции выполняют сравнение и, если происходит ошибка, дают приращение переменной errors. Последняя инструкция, при достижении конца файла входных данных, выводит окно с сообщением, содержащим данные о количестве ошибок. В процессе настройки системы используются переменные, отличные от входных и выходных. Для обнаружения и подсчета ошибок классификации мы использовали в редакторе имена переменной check и переменной errors соот- ветственно. Теперь необходимо создать сами эти переменные. С помощью меню Variables откройте Variables Editor. Появится диалоговое окно, содержащее имена уже созданных входных и выходных переменных. Нажмите кнопку New для создания новой переменной. В окне Edit Variable определите переменные: сheck (тип переменной – Temporary, начальное значение – 0.0); errors (тип переменной – Temporary, начальное значение – 0.0).
Настройка входного файла:
Для импорта входного файла в проект, необходимо:
1) Создать файл с расширением.txt (см. рис. 2.7), задать файлу имя (File → Input File) и некоторые атрибуты (см. рис. 2.8).


Рис.2.7 Рис.2.8
2) Указать тип файла – Text. Задать количество Fields per Record (Полей на запись), равное 3 (каждая запись содержит значения для Prozh, Doxod и check) и количество Lines per Record (Строк на запись), равное 1 (каждая запись занимает одну текстовую строку).
3) Далее необходимо определить, какая информация должна отображаться при запуске системы (Project → Log Format). Нажатием кнопки «Add» выберите из левого списка окна переменные discont, period, rate и check. Убедимся в непротиворечивости указания переменных (Execute → Check Definitions), снимем флажки Initialization, Simulation. Проверим работу системы, запустив созданный сценарий Execute → Run. Появится окно, содержащее значения переменных и их порядок, выбранные в Log Format Editor. Когда CubiCalc «просмотрит» весь входной файл, появится заданное на этапе предобработки итоговое сообщение (см.рис.2.9).

Рис.2.9
Для остановки сценария выполните Execute → Terminate.
|
|
|
|
|
Дата добавления: 2017-01-13; Просмотров: 984; Нарушение авторских прав?; Мы поможем в написании вашей работы!