КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Информационные потоки и необходимость их автоматизации
|
|
|
|
Потоки информации, циркулирующие в окружающем нас мире, огромны. Во времени они имеют тенденцию к увеличению. В этих потоках имеются документы, содержащие самую разнообразную информацию. Документы сопровождают нас на каждом шагу. Ежедневно в мире создаются миллиарды больших и малых документов и их копий. На производство и воспроизведение документов расходуется огромное количество леса, а на их проверку и хранение требуется большое количество времени. Современное общество не может существовать без документооборота.
 Документооборот — последовательность прохождения документов с момента их составления или получения до момента их обработки и использования.
Документооборот — последовательность прохождения документов с момента их составления или получения до момента их обработки и использования.
Основные принципы документооборота:
- рациональное и своевременное составление документов;
- последовательность охвата документами всех видов хозяйственной деятельности организации;
- взаимосвязь документов;
- рациональная обработка документов;
- сокращение путей прохождения документов;
- систематизированное изучение и совершенствование документооборота.
До обработки документа это могут быть первичные тексты, данные экономической информации, данные автоматических датчиков, листки изменений карточек нормативов и пр. Документы могут быть обработаны вручную или с помощью технических средств (ТС). После обработки вторичные документы в надлежащем виде (форме) должны быть переданы с помощью ТС потребителям.
В любом предприятии возникает проблема такой организации управления данными, которая обеспечила бы наиболее эффективную работу. Для эффективного руководства организацией и оптимального выполнения работ современным руководителям и специалистам постоянно требуется иметь в распоряжении обширную и достоверную информацию. Этого можно достичь в настоящее время только с помощью средств и методов автоматизации информационных потоков.
Информационный поток — информация, рассматриваемая в процессе ее движения в пространстве и времени в определенном направлении.
Правильный выбор или разработка программных продуктов для автоматизации информационных потоков в рамках информационных систем — первейшая задача современных организаций. Для проведения совещаний нужно иметь автоматизированные офисы, а для выполнения технологических процессов — АИС (в том числе АСУ), функционирующие в рамках определенных предметных областей, организаций, производств и т. д. Введение новых безбумажных технологий, использующих ЭВМ и новые организационные формы их применения, повышает требования к защите информации при оперативности информационного обмена. Так в многоуровневых системах организационного управления, таких как банки, налоговые службы и т. п., информационное обеспечение представляет собой сеть Банков данных, в которых эти требования обеспечиваются.
Рассмотрим, как идут потоки информации в АСУ.
Поток информации — это группа данных, рассматриваемых в процессе ее движения в пространстве и времени в одном направлении. У этих данных есть общий источник и общий приемник. Поток, состоящий из смысловых структурных элементов, называют сообщением.
Предполагается, что при управлении количеством и качеством информации происходит ее возникновение, прием, передача и переработка. Действие информации заключается в снятии неопределенности ситуации. В АСУ одной из задач является передача управленческому персоналу минимума информации, необходимой для определения состояния производства и принятия решения. Базы данных (массивы информации) в системе должны быть оптимально организованы на основе использования единой системы классификации и кодирования технико-экономической информации, унифицированных систем документации. Информационное обеспечение (ИО) АСУ должно предоставить всем функциональным подсистемам необходимую информацию в требуемом объеме, в требуемые сроки и в удобной для использования форме. В процессе управления для создания ИО должны быть осуществлены:
- сбор информации о состоянии внешней среды и объекта управления, т. е. создание информации, называемой первичной, текущей, входной;
- подготовка и сборка информации в соответствии с некоторой моделью управления, т. е. создание промежуточной информации;
- выработка управляющих воздействий, т. е. создание оперативной и управляющей информации.
При сборе информации исходными документами являются те, которые служат источниками информации для других документов. Производные документы (показатели) формируются на основании других документов. Первичные документы непосредственно отражают входную информацию. Конечные документы — выходные документы, а также непосредственно влияющие на объект управления.
Формированием документа (показателя) называется процесс перехода от исходных документов (показателей) к производным. Не всегда выполняют преобразование исходных показателей, иногда часть показателей документа просто переносят в другой документ.
В АСУ на нижних уровнях действует детальная информация о состоянии объекта управления. По мере движения информации от нижних уровней управления к высшим она должна быть избавлена от лишних подробностей, бесполезной детализации. Этот процесс называется интеграцией или сжатием информации, а сама информация — осведомительной.
Распорядительная информация (идущая от верхних уровней к нижним) на средних уровнях «размножается», так как средние уровни генерируют дополнительную информацию.
Степень интеграции или степень размножения  оценивается коэффициентом
оценивается коэффициентом  , где
, где 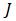 — количество информации. Для осведомительной информации
— количество информации. Для осведомительной информации 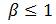 , а для распорядительной —
, а для распорядительной — 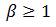 .
.
Прежде всего собирается информация о состоянии внешней среды и объекта управления. Она называется первичной. Информация, получаемая в результате обработки первичной информации (сортировки, группировки, выделения, вычислений и т. д.), называется промежуточной или вторичной информацией.
Информация, полученная для выработки управляющих воздействий, называется управляющей (оперативной), требующей немедленной реакции системы управления.
По критерию стабильности выделяют переменную и постоянную информацию. Переменная информация отражает фактическое состояние объекта и, как правило, участвует в одном цикле обработки. Постоянную информацию многократно используют для обработки переменной информации.
Создание информационного обеспечения АИС (АСУ) начинают с анализа информационных потоков: обследуют реальные потоки и анализируют полученные результаты. Составляют структурную схему потоков информации. Обследуют и изучают существующие потоки, определяют реальные характеристики документов. Изучение существующих потоков информации значительно повышает качество проектируемой системы. Главная цель — выявить возможность автоматизации процессов сбора, передачи и переработки сообщений или их частей.
В результате для перехода от существующих потоков информации к потокам, действующим в условиях автоматизированного управления, составляют таблицы:
- сводные, отражающие количество документов при существующей системе управления;
- первичного анализа структуры и значимости существующих документов;
- анализа структуры и значимости типового сообщения в условиях АУ;
- рекомендуемых потоков информации от подразделений в АСУ;
- рекомендуемых потоков информации, выводимых из системы управления в подразделении;
- сводные, отражающие потоки информации, выводимые из системы управления с помощью ТС.
Эффективным инструментом структурирования информации является математическое моделирование. Создание модели ИО должно основываться на результатах детального обследования объекта управления, выявления закономерностей, функционирования в нем информационных потоков и определения решаемых задач. Должна быть определена связь логических и физических уровней организации (рис. 1.1).

Рис. 1.1. Пример схемы действующих информационных потоков
Далее выполняется анализ структуры документов и разрабатываются их унифицированные формы, пригодные для обработки в ЭВМ. Прежде чем приступить к автоматизации информационных потоков, должны быть выполнены:
- системный анализ информационных потоков — уровень проблем, среда распространения, тип информации, взаимосвязь потоков;
- формирование целевых установок — политических, хозяйственных, нравственных, технических;
- определение переменных управления — экономических, организационных, правовых, информационных.
Предметом труда в АИС является информация, она может классифицироваться по различным признакам, например:
- по форме представления — аналоговая, дискретная;
- по степени детализации — детальная, интегрированная;
- по форме отображения — графическая, текстовая;
- по видам используемых параметров — техническая, социальная, биологическая, экономическая и т. д.
Потоки информации могут формироваться:
- как речевая передача информации;
- как передача информации в виде обычных документов с ручной доставкой;
- с использованием технических средств ручного ввода;
- с автоматическим вводом сообщений.
Поток информации рассматривается как совокупность двух понятий — схемы и элементов потока.
Схема потока информации задается указанием отношения вхождения относительно каждого элемента потока.
Элементами потока могут быть документы, элементы документов (показатели, реквизиты), операторы (люди, устройства, подразделения). Операторы могут быть источниками и потребителями.
В потоке информации (ПИ) определяются два основных параметра — направление и плотность потока. Направление потока задается местом его входа (наименование или шифр) подразделения. Плотность (значение)  потока — объем информации (бит, количество документов, строк, знаков и т. д.), передаваемый в единицу времени
потока — объем информации (бит, количество документов, строк, знаков и т. д.), передаваемый в единицу времени 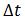 (длительность передачи, приема или обработки).
(длительность передачи, приема или обработки).
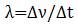 .
.
Потоки информации зависят от режима работы. Применительно к предприятию в ПИ выделяют постоянную составляющую 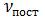 и составляющие потока, имеющие период смены, суток, декады, месяца и т. д.
и составляющие потока, имеющие период смены, суток, декады, месяца и т. д.
Например, для подразделения с двухсменной работой при длительности смены 8 часов и при 25 рабочих днях в месяце плотность информации за месячный интервал, ед. инф./ч:
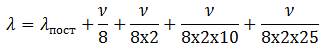
 — плотность постоянного потока.
— плотность постоянного потока.
Составляющие потоков неравномерны в течение периода, поэтому мгновенное значение зависит от суток, числа, месяца. Кроме того, поток состоит из случайного и детерминированного потока. Поэтому каждый раз определяется путем набора и обработки статистических данных.
Для отображения информационных потоков строят информационно-логические схемы взаимодействия их отдельных функций и частей. Строится таблица, отображающая назначение операций, входящую и выходящую информацию. Применяют методы формализации с дальнейшей обработкой на ЭВМ.
Например, используют метод графов (рис. 1.2). Элемент потока  сопоставляют с вершинами графа, и каждую пару вершин соединяют дугой, идущей от
сопоставляют с вершинами графа, и каждую пару вершин соединяют дугой, идущей от 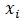 к
к  , где элемент является входом элемента . Расширенный граф добавляет управляющие операторы, от которых исходит управляющее воздействие.
, где элемент является входом элемента . Расширенный граф добавляет управляющие операторы, от которых исходит управляющее воздействие.
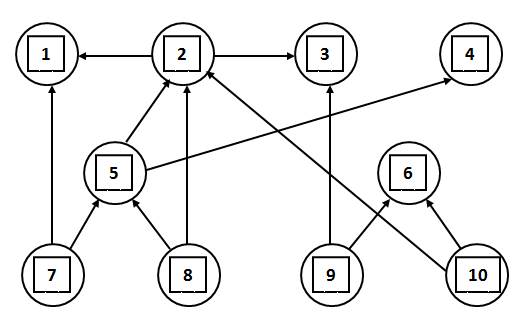
Рис. 1.2. Информационный граф автоматизированных потоков
Система классификации и кодирования информации обеспечивает формализацию информации в виде, пригодном для последующей обработки ее на ЭВМ.
При обработке информации с помощью технических средств используют различные структуры: скалярные данные, массивы, блоки, записи и т. д.
Данные — информация, представленная в формализованном виде, позволяющем передавать или обрабатывать ее с помощью ТС.
Массив — множество данных, содержащих достаточно полное описание информационной совокупности, состоящей из однотипных объектов. Смысловое содержание массива обычно указывается в его названии. Массив состоит из отдельных записей, имеющих одинаковое смысловое содержание. Каждая запись массива состоит из реквизитов. Длина реквизита — количество ячеек памяти, записанных последовательно.
Блок — несколько записей, объединенных в одну физическую запись. ЭВМ обрабатывает данные одного блока, выводит результат во внешнюю память, затем выводит для обработки следующий блок. Объединение записей в блок осуществляется автоматически. Объем блока равен объему сектора магнитного диска (МД), а для массивов на магнитном барабане — объему буферной памяти.
На рис. 1.3 представлена классификация массивов на основе следующих классификационных признаков:
- семантического содержания;
- технологии использования;
- носителя информации;
- технических характеристик.

Рис. 1.3. Классификация массивов
Организация массивов — упорядочение его записей и их физическое размещение в памяти системы. Как правило, массивы упорядочивают по ключу — наиболее важному признаку. Организация (структура) бывает:
- последовательно-смежная;
- цепная;
- ветвящаяся;
- списковая.
Под обработкой массива понимают процесс его преобразования. Типичные операции с массивами: сортировка, слияние, разбиение, поиск, изменение носителей. Сортировка — по ключу, методом замещения, отбора, вставки, квадратичной выборки. По времени различают доступ параллельный, ассоциативный, прямой, последовательный, с равным временем, индексно-последовательный, расчлененный.
Поиск — процедура выделения из некоторого множества объектов подмножества, содержащего только те объекты, которые удовлетворяют некоторому условию. Виды поиска: по совпадению, по интервалу близости, сложному арифметическому условию, семантическому условию, логической совокупности нескольких условий и т. д.
Методы поиска: перебор, вычисление адресов, дихотомический поиск.
Перебор — проверка условий поиска для всех объектов, входящих в состав данного множества.
Вычисление адресов — определение адреса в виде некоторой однозначной функции от заданного условия поиска, определение зоны памяти, ограниченной или произвольной по размеру, которая является -линейной функцией от кода, входящего в условие поиска.
Дихотомический поиск — после каждой проверки уменьшается область поиска примерно в 2 раза. Кроме проверки выполнения условий поиска каждый раз надо определить знак отклонения от заданного условия поиска.
Современные средства электронного документооборота дают возможность создать интегральные системы с одновременной обработкой структурных и неструктурных данных, включая письма, приказы, инструкции, расписания, видеоинформацию и т. д. Управление обычной электронной почтой предусматривает автоматизацию рассылки информации по адресам, т. е. с помощью ИС происходит управление всем документооборотом.
Например, в экспертной системе знания (наборы понятий и отношений между ними) представлены в символьной форме. Типы знаний: понятийные, конструктивные, процедурные, фактографические, метазнания.
Понятийные — знания, выработанные в теоретических науках и используемые для решения определенной задачи.
Конструктивные — знания, выработанные в технике и большей части прикладных наук, о наборах возможных структур объектов и взаимодействии между их частями.
Процедурные — знания, используемые в выбранной предметной области, методы, алгоритмы и программы, полезные для конкретного приложения, которые можно использовать, передавать и объединять в библиотеки.
Фактографические знания — количественные и качественные характеристики объектов и явлений.
Метазнания — знания о порядке и правилах применения знаний.
Существуют различные формы представления знаний. Чаще всего используются эвристические модели. В большинстве экспертных систем в базе знаний (БЗ) хранятся используемые в данный момент правила и сведения о проблемной области.
В основе представления знаний с помощью семантических сетей лежит формализация в виде графа с помеченными вершинами и дугами. Вершины — некоторые сущности (объекты, события, процессы, явления), а дуги — отношения между ними.
Например, простейшая семантическая сеть, выражающая знания об ЭВМ:
- по типам — в зависимости от производительности (микро, мини, мега);
- по классам — по их стоимости (низкая, средняя, высокая, большая).
Дуги данной сети будут обозначать соответствие.
Более сложный способ представления знаний — в виде фреймов, он используется в мощных экспертных системах. Фреймы — специфические объекты, соответствующие понятиям предметной области, имеющие внутреннюю структуру в виде слотов: данных, правил, других фреймов.
Элементарными компонентами представления знаний являются тексты, списки и другие символьные структуры. Знания представляются в виде конкретных фактов и правил.
Подход, основанный на продукционных правилах, чрезвычайно распространен в экспертных системах. Как правило, они имеют форму ЕСЛИ... ТОГДА... ИНАЧЕ..... Правила в БЗ имеют вид: ЕСЛИ А (условие) ТО S (действие). S исполняется, если А истинно. Действие S обычно является утверждением, которое может быть выведено системой, если истинно условие правила А. Правила служат для представления эвристик — неформальных правил рассуждения эксперта.
Цель автоматизации разнообразных потоков информации — совершенствование существующего документооборота, форм документов, сокращение их числа и копий, оптимизация маршрутов движения документов и алгоритма их формирования. Одна из основных задач состоит в разработке и внедрении средств и методов использования вычислительной техники для перевода документооборота из бумажной формы в электронную. Современные сетевые информационные технологии позволяют решить эту задачу. Все банки мира уже связаны сетевыми электронными сетями, и финансовые документы циркулируют в основном в электронном виде. Постепенно выходят из обращения бумажные акции предприятий и другие ценные бумаги. Их заменяют электронные депозитарии, т. е. базы данных (БД), в которых сведения об акционерах хранятся в виде записей. Сравнительно недавно появились электронные деньги — это тоже записи БД. Движение электронных денег происходит по безбумажной технологии путем переноса данных из одних записей в другие. В качестве электронных денег служат пластиковые карты, содержащие сведения о владельце электронного счета на магнитной полосе, или смарт-карты, которые записывают на микросхему, встроенную в эту карту. По безбумажной технологии сегодня работает большинство средств массовой информации. Все этапы подготовки газет, рекламы, книг проводятся на компьютере с помощью автоматизированных издательских систем.
Многозадачные операционные системы (ОС) типа Windows позволяют одновременно создавать и редактировать тексты, а компьютерные сети объединяют в автономные рабочие группы. Такая рабочая группа может обходиться без бумажных документов до полного завершения работы над системой (проектом). Только когда работа закончена, можно составить итоговый бумажный документ. Основным препятствием на пути создания безбумажной технологии стоит проблема ввода исходных данных в электронном виде. Эта проблема решается путем создания и внедрения специальных аппаратов и специальных средств перевода информации разного вида в электронную форму. Автоматизация ввода информации в компьютер, т. е. перевод бумажных документов в электронный вид, осуществляется путем сканирования.
Сканирование — это технологический процесс, в результате которого создается графический образ бумажного документа.
Существуют разные виды сканеров, но в основе их действия лежит один и тот же принцип: документ освещается светом от специального источника, а отраженный свет воспринимается светочувствительным элементом. Минимальный элемент интерпретируется сканером как цветная или серая точка. В результате сканирования документа создается графический файл, в котором хранится растровое изображение документа (состоит из пикселей). Количество точек определяется как размером изображения, так и разрешающей способностью сканера. Данные о сканерах см. в разд. 1.4.
Проблема автоматического распознавания текста созданного точечного графического изображения является сложной. Эта задача решается с помощью специальных программных средств, называемых средствами распознавания образов. Реально это стало возможно только в последние годы. Появились специальные программы, которые распознают разные шрифты и даже рукописный текст. В нашей стране наиболее распространены программы распознавания текста на русском языке Fine Reader и CuneiForm.
Например, программа Fine Reader 7.0 компании АВВYY Software предназначена для распознавания текстов на русском и многих других языках, а также и для распознавания смешанных двуязычных текстов. Программа позволяет сканировать, распознавать, редактировать распознанный текст, проверять его орфографию и сохранять документы. Fine Reader работает с разными моделями сканеров в среде Windows и поддерживает стандарт TWAIN. Для изменения настроек сканера служит кнопка «Опции» панели «Scan&Read». Когда сканер выбран, активизируются флажки в диалоговом окне. Если установить флажокTWAIN драйвера, то сканирование будет проходить через TWAIN интерфейс, если иначе — напрямую. Флажок «Показывать опции перед началом сканирования» нужно устанавливать только в том случае, когда бумажные страницы документа существенно отличаются друг от друга, и тогда перед сканированием каждой страницы будет открываться диалоговое окно настройки сканирования, чтобы регулировать качество процесса. Сам процесс сканирования проходит в автоматическом режиме. После сканирования следует приступить к распознаванию.
Окно программы Fine Reader (рис. 1.4) содержит строку меню, панели инструментов и рабочую область. В левой части рабочей области расположено окно «Пакет». Здесь содержится список графических документов, которые нужно преобразовать в текст. В верхней части окна программы (под панелью стандартных инструментов) находятся панели для сканирования, распознавания, проверки и сохранения документов. Панель «Scan&Read» содержит все операции преобразования (через диалоговые окна) бумажного документа в электронный графический. Далее по горизонтали расположены панели «Открыть», «Распознать», «Проверить», «Сохранить». После операции сканирования (выполняемой подключенным сканером) программа отображает значки полученной страницы в панели «Пакет». При распознавании текста сначала в окне рабочей области содержится отсканированный графический документ для распознавания, затем текстовый документ после распознавания с выделением фрагментов, распознанных неоднозначно. Дополнительные врезки и данные могут запутать естественный порядок распознавания текста, поэтому, прежде чем включить текст в документ, его разбивают на блоки (сегментируют), содержащие цельные фрагменты. Блоки распознают последовательно и нумеруют. Полученный блок вставляется в порядке нумерации в документ. Этап распознавания выполняется программой без вмешательства пользователя, за исключением случая, когда после распознавания идет процесс проверки и исправления ошибок. Распознанный текст представляется в окне в виде форматированного текстового документа. Он теряет связь с исходным изображением. Программа цветом выделяет символы, которые она распознала неоднозначно, и это упрощает поиск ошибок. Имеется возможность проверки грамматики. Полученный текст можно сохранить в виде форматированного или неформатированного документа. Есть возможность прямой передачи полученного текста программе Word, Ехсеl или в буфер обмена.

Рис. 1.4. Окно программы Fine Reader
При автоматизации документооборота широко используются средства автоматического перевода — компьютерные словари и программы автоматического перевода с одного языка на другой. Из последних в нашей стране наиболее распространены программы Socrat и Stylus (теперь называется Prompt). Программа Prompt предназначена для автоматического перевода с русского языка на английский и наоборот. Работает с документами разных форматов. Ее интерфейс соответствует требованиям ОС Windows. Режим работы идет поэтапно:
- загружается файл с исходным текстом (команды: Файл —> Открыть);
- в диалоговом окне Конвертировать файл автоматически выбирается формат файла и направление перевода (команда: ОК);
- сначала исходный документ отображается как в области оригинала, так и в области перевода, далее дается команда Перевод —> Весь Текст;
- во время перевода осуществляется прокручивание исходного документа и замена исходного текста на иноязычный текст;
- после перевода можно выполнить редактирование текста. Широко используют при создании документов компьютерную графику, различные мультимедийные средства.
Контрольные вопросы к разделу 1.2
1. Что такое документооборот?
2. Каковы основные принципы документооборота?
3. Что такое информационный поток?
4. Что такое интеграция и сжатие информации? Приведите формулу для определения степени интеграции.
5. В чем заключается анализ информационных потоков?
6. Каковы виды формирования информационных потоков?
7. Каковы современные средства электронного документооборота?
|
|
|
|
|
Дата добавления: 2017-01-13; Просмотров: 1659; Нарушение авторских прав?; Мы поможем в написании вашей работы!