КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Основные причины чрезвычайных ситуаций
По дисциплине
" ТЕОРИЯ ИНФОРМАЦИИ"
для студентов специальности 5В100200–Системы информационной безопасности
Рассмотрено и одобрено на заседании кафедры СИБ
Протокол № 9 от 24.06.2016г.
Зав каф. СИБ ______________ Е.Г. Сатимова
Составил: магистр. ст. пр _______________ Б.М.Якубов
Алматы, 2016 г.
ПОМЕХОУСТОЙЧИВОЕ КОДИРОВАНИЕ:
Помехоустойчивость- способность системы осуществлять прием информации в условиях наличия помех в линии связи и искажений во внутри аппаратных трактах. Помехоустойчивость обеспечивает надежность и достоверность передаваемой информации (данных). Мы будем в основном рассматривать двоичные коды. Двоичные (коды) данные передаются между вычислительными терминалами, летательными аппаратами, спутниками и т. д. Передача данных в вычислительных системах чувствительна к малой доле ошибке, т. к. одиночная ошибка может существенно нарушить процесс вычислений. Наиболее часто ошибки появляются в УВВ, шинах, устройствах памяти. УВВ содержат большое количество элементов, ошибки обуславливаются старением элементов, ухудшением качества электрических соединений, расфазировкой сигналов. Значительная часть ошибок приходится на ОП, вследствие отказа отдельных ИС либо всей ИС, ошибок связанных с флуктуацией напряжения питания и т. д. В системах со многими пользователями и разделением по времени длинные двоичные сообщения разделяются на пакеты. Сообщения, представленные длинными последовательностями битов, обычно разбиваются на более короткие последовательности битов, называемые пакетами. Пакеты можно передать по сети как независимые объекты и собирать из них сообщение на конечном пункте. Пакет, снабженный именем и управляющими битами в начале и в конце, называется кадром. Управление линией передачи данных осуществляется по специальному алгоритму, называемому протоколом. Наличие помех ставит дополнительные требования к методам кодирования. Для защиты информации от помех необходимо вводить в том или ином виде избыточность: повышение мощности сигнала; повторение сообщений; увеличение длинны кодовой комбинации и т. д. Увеличение мощности сигналов приводит к усложнению и удорожанию аппаратуры, кроме того, в некоторых системах передачи информации имеется ограничение на передаваемую мощность, например, спутниковая связь. Повторная передача сообщений требует наличия буферов для хранения информации и наличия обратной связи для подтверждения достоверности переданной информации. При этом, значительно падает скорость передачи информации, кроме того этот метод не всегда м. б. использован, например, в система реального времени. Одним из наиболее эффективных методов повышения достоверности и надежности передачи данных является помехоустойчивое кодирование, позволяющее за счет внесения дополнительной избыточности (увеличение минимального кодового расстояния) в кодовых комбинациях передаваемых сообщений обеспечить возможность обнаружения и исправления одиночных, кратных и групповых ошибок. Минимальное кодовое расстояние характеризует помехоустойчивость и избыточность сообщений. В зависимости от величины минимального кодового расстояния существуют коды, обнаруживающие и исправляющие ошибки. Кодовое расстояние - d определяется как количество единиц в результате суммирования по модулю два двух кодовых комбинаций. Минимальное кодовое расстояние d0 - минимальное из кодовых расстояний всех возможных кодовых комбинаций. Для обнаружения r ошибок минимальное кодовое расстояние равно:
d0 і r+1. (8)
Для обнаружения r ошибок и исправления s ошибок минимальное кодовое расстояние равно:
d0 і r+s+1. (9)
Только для исправления ошибок минимальное кодовое расстояние равно:
d0 і 2s+1. (10).
ОБНАРУЖИВАЮЩИЕ КОДЫ:
Обнаруживающие коды - это коды, позволяющие обнаружить ошибку, но не исправить ее. Простейший способ обнаружения ошибки это добавление к последовательности битов данных еще одного бита-бита проверки на четность (нечетность) значение, которого равно сумме по модулю два исходной последовательности битов. Чаще организуется проверка на нечетность. В символьном коде ASCII к семи битам кода добавляется восьмой бит проверки на четность - k1.
S1 S2 S3 S4 S5 S6 S7 K1
Однобитовая проверка позволяет обнаружить любую единичную ошибку, две ошибки обнаружить нельзя, в общем случае обнаруживается любое нечетное количество ошибок. Внесение избыточности за счет увеличения длины кодовой комбинации приводит к снижению скорости передачи информации. Если скорость идеально использует канал, то
 .
.  (11)
(11)
Если кодовая комбинация длиной n содержит k информационных и m контрольных разрядов (n = k + m), то
 .
.
Для кода ASCII n = 8 и k = 7
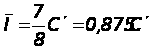 т. е. введения одного избыточного разряда приводит к уменьшению пропускной способности канала связи на 12,5%. Чаще всего шумы (молнии, разрыв и т.д.) порождают длинные пакеты ошибок и вероятность четного и нечетного числа ошибок одинакова, а значит и однобитовая проверка не эффективна. Проверка на четность по вертикали и горизонтали. При этом последовательность битов данных перестраивается в двухмерный массив, и вычисляются биты на четность, как для каждой строки, так и для каждого столбца. При этом можно обнаружить несколько ошибок, если они не располагаются в одинаковых строках и столбцах. Чаще всего используется при передаче данных кода ASCII; каждый символ можно считать строкой массива. Такая проверка может не только установить факт ошибки, но и обнаружить ее место, а значит, есть принципиальная возможность ее исправления, хотя это практически не используется.
т. е. введения одного избыточного разряда приводит к уменьшению пропускной способности канала связи на 12,5%. Чаще всего шумы (молнии, разрыв и т.д.) порождают длинные пакеты ошибок и вероятность четного и нечетного числа ошибок одинакова, а значит и однобитовая проверка не эффективна. Проверка на четность по вертикали и горизонтали. При этом последовательность битов данных перестраивается в двухмерный массив, и вычисляются биты на четность, как для каждой строки, так и для каждого столбца. При этом можно обнаружить несколько ошибок, если они не располагаются в одинаковых строках и столбцах. Чаще всего используется при передаче данных кода ASCII; каждый символ можно считать строкой массива. Такая проверка может не только установить факт ошибки, но и обнаружить ее место, а значит, есть принципиальная возможность ее исправления, хотя это практически не используется.
1 0 1 1 0 1 1 1
0 1 0 0 0 1 0 0
1 0 1 0 0 1 0 1
1 1 0 0 1 0 1 0
0 0 0 1 0 1 0 0
1 0 0 0 1 0 0
После обнаружения ошибок иногда можно повторить передачу сообщений, иногда после обнаружения ошибки предпринимается вторая и даже третья попытка передачи сообщения. Проверка на четность широко используется на ЭВМ, как на аппаратном, так и на программном уровне. Например, при считывании с магнитной ленты в случае, когда условие на четность не выполняется, то производится повторное считывание, т. е. если произошла малая потеря намагниченности, то после второй попытки может быть считывание произойдет правильно.
Пример 1. Символы алфавита источника кодируются семиразрядным двоичным кодом с весом кодовых векторов (количеством единиц в кодовой комбинации) w = 3. Определить необходимую мощность кода и его избыточность.
Решение: Мощность семиразрядного кода равна N = 27 = 128.
Так как для кодирования используются только кодовые вектора с весом три, то количество таких векторов в семиразрядном коде равно:

Избыточность кода равна R = 1 – log2K/ log2N = 0,265.
Литература: Конспекты лекций., Л. 3, 4, 5,6,7
Список литературы:
Основная:
1. Прокис Дж. Цифровая связь. - М.: Радио и связь, 2000.
2. Скляр Б. Цифровая связь. - М., Санк-П, Киев: Изд. дом «Вильяме» 2003.
3. Гаранин М.В., Журавлев, Кунегин С.В. Системы и сети передачи информации. - М.: Радио и связь, 2001.
4.В.К. Душин. Теоретические основы информационных процессов и
систем. Учебник. - М. Издательско - торговая корпорация «Данников и К»,
2003.
5.Передача дискретных сообщений В.П.Шувалов и др. -М.: Радио и
связь, 1990.
Дополнительная:
6. Хаффман Д. А. Метод построения кодов с минимальной - избыточностью//Кибернетический сборник, вып. 3.- М.: ИЛ, 1961.- С. 79-87.
7. Хэмминг Р.Б. Коды с обнаружением и исправлением ошибок//Коды с обнаружением и исправлением ошибок.- М.: ИЛ, 1056.- С. 7-23.
Свёрточный код
[править | править вики-текст]
Материал из Википедии — свободной энциклопедии
Свёрточный код — это корректирующий ошибки код, в котором
(a) на каждом такте работы кодера  символов входной полубесконечной последовательности преобразуются в
символов входной полубесконечной последовательности преобразуются в  символов выходной, и
символов выходной, и
(b) в преобразовании также участвуют 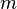 предыдущих символов;
предыдущих символов;
(c) выполняется свойство линейности (если двум кодируемым последовательностям  и
и  соответствуют кодовые последовательности
соответствуют кодовые последовательности 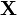 и
и  , то кодируемой последовательности
, то кодируемой последовательности  соответствует
соответствует  ).
).
Свёрточный код является частным случаем древовидных и решетчатых кодов.
Содержание
[убрать]
· 1История возникновения
· 2Общая схема нерекурсивного кодера
· 3Двоичные свёрточные кодеры
· 4Параметры и характеристики свёрточных кодов
· 5Общий вид двоичного сверточного кодера
· 6Способ задания сверточных кодов
· 7Применение
· 8См. также
· 9Литература
· 10Ссылки
· 11Статьи
· 12Примечания
История возникновения[править | править вики-текст]
В 1955 году Л. М. Финком, который в то время являлся заведующим кафедрой Ленинградской академии связи, был предложен первый рекуррентный код.
В 1959 году западный специалист Хегельбергер (Hegelbeger), не имевший представления о работе советских ученых в области кодирования, «вновь открыл» рекуррентный код и назвал его своим именем.
Сам Финк в своей монографии «Теория передачи дискретных сообщений» писал: «В этом коде последовательность кодовых символов не разделяется на отдельные кодовые комбинации. В поток информационных символов включаются корректирующие символы так, что между каждыми двумя информационными символами помещается один корректирующий. Обозначая информационные символы через ai, а корректирущие через bi получаем такую последовательность символов:
a1b1a2b2a3b3 …… akbkak+1bk+1…..
Информационные символы определяются переданным сообщением, а корректирующие формируются по следующему правилу:
bi = (ak-s + ak+s+1) mod 2, (1.1)
где s — произвольное целое число, называемое шагом кода (s = 0,1,2…). Очевидно, что при ошибочном приеме некоторого корректирующего символа bi соотношение (1.1) в принятой последовательности не будет выполнено для i = k. В случае же ошибочного приема информационного символа ai соотношение (1.1) не будет выполняться при двух значениях ki, а именно при k1 = i — s — 1 и при k2 = i + s. Отсюда легко вывести правило исправления ошибок при декодировании. В принятой кодовой последовательности для каждого bk проверяется соотношение (1.1). Если оно не выполняется при двух значениях k (k = k1 и k = k2), и при этом
k2 — k1 = 2s +1, (1.2)
то информационный элемент ak1+s+1 должен быть заменен на противоположный.
Очевидно, что избыточность кода равна 1/2. Он позволяет исправлять все ошибочно принятые символы, кроме некоторых неудачных сочетаний. Так, если s = 0, он обеспечивает правильное декодирование, когда между двумя ошибочно принятыми символами имеется не менее трех (а в некоторых случаях двух) правильно принятых символов (при этом учитываются как информационные, так и проверочные символы).»
Общая схема нерекурсивного кодера[править | править вики-текст]
Схема кодера нерекурсивного свёрточного кода представлена на Рис.1. Он состоит из  -ичных регистров сдвига с длинами
-ичных регистров сдвига с длинами  . Некоторые (может и все) входы регистров и выходы некоторых ячеек памяти соединены с несколькими
. Некоторые (может и все) входы регистров и выходы некоторых ячеек памяти соединены с несколькими  сумматорами по модулю . Число сумматоров больше числа регистров сдвига:
сумматорами по модулю . Число сумматоров больше числа регистров сдвига:
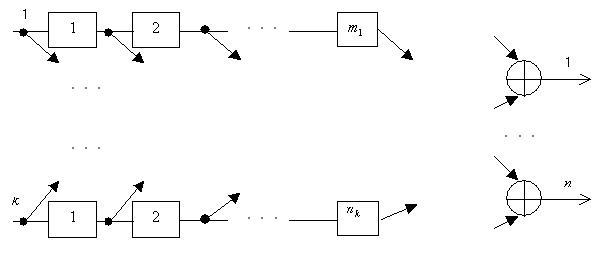
Рис.1. Общая схема кодирования свёрточным кодом
На каждом такте работы кодера на его вход поступает информационных символов, они вместе с хранящимися в регистрах сдвига символами поступают на входы тех сумматоров, с которыми имеется связь. Результатом сложения является кодовых символов, готовых к передаче. Затем в каждом регистре сдвига происходит сдвиг: все ячейки сдвигаются вправо на один разряд, при этом крайние левые ячейки заполняются входными символами, а крайние правые стираются. После этого такт повторяется. Начальное состояние регистров заранее известно (обычно нулевое).
· Суммарная длина  всех регистров сдвига называется кодовым ограничением, а максимальная длина
всех регистров сдвига называется кодовым ограничением, а максимальная длина  — задержкой.
— задержкой.
· Значения регистров сдвига в каждый момент времени называется состоянием кодера.
Двоичные свёрточные кодеры[править | править вики-текст]
Для наглядности представления будем описывать свёрточное кодирование по действию соответствующего кодирующего устройства.
Свёрточный кодер — это устройство, принимающее на каждом такте работы в общем случае k входных информационных символов, и выдающее на выход каждого такта n выходных символов. Число 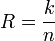 называют относительной скоростью кода. k — число информационных символов, n — число передаваемых в канал связи символов за один такт поступления на кодер информационного символа. Выходные символы рассматриваемого такта зависят от m информационных символов, поступающих на этом и предыдущих тактах, то есть выходные символы свёрточного кода однозначно определяются его входными символами и состоянием, которое зависит от m — k предыдущих информационных символов. Основными элементами свёрточного кода являются: регистр сдвига, сумматор по модулю 2, коммутатор.
называют относительной скоростью кода. k — число информационных символов, n — число передаваемых в канал связи символов за один такт поступления на кодер информационного символа. Выходные символы рассматриваемого такта зависят от m информационных символов, поступающих на этом и предыдущих тактах, то есть выходные символы свёрточного кода однозначно определяются его входными символами и состоянием, которое зависит от m — k предыдущих информационных символов. Основными элементами свёрточного кода являются: регистр сдвига, сумматор по модулю 2, коммутатор.
Регистр сдвига (англ. Shift register) — это динамическое запоминающее устройство, хранящее двоичные символы 0 и 1. Память кода определяет число триггерных ячеек m в регистре сдвига. Когда на вход регистра сдвига поступает новый информационный символ, то символ, хранящийся в крайнем правом разряде, выводится из регистра и сбрасывается. Остальные символы перемещаются на один разряд вправо и, таким образом, освобождается крайний левый разряд куда будет поступать новый информационный символ.
Сумматор по модулю 2 осуществляет сложение поступающих на него символов 1 и 0. Правило сложения по модулю 2 таково: сумма двоичных символов равна 0, если число единиц среди поступающих на входы символов четно, и равно 1, если это число нечетно.
Коммутатор последовательно считывает поступающие на его входы символы и устанавливает на выходе очередность кодовых символов в канал связи. По аналогии с блоковыми кодами, свёрточные коды можно классифицировать на систематические и несистематические.
Систематический свёрточный код — это код, содержащий в своей выходной последовательности кодовых символов породившую её последовательность информационных символов. Иначе код называют несистематическим.
Параметры и характеристики свёрточных кодов[править | править вики-текст]
При свёрточном кодировании преобразование информационных последовательностей в выходные и кодовые происходит непрерывно. Кодер двоичного свёрточного кода содержит сдвигающий регистр из m разрядов и сумматоры по модулю 2 для образования кодовых символов в выходной последовательности. Входы сумматоров соединены с определёнными разрядами регистра. Коммутатор на выходе устанавливает очередность посылки кодовых символов в канал связи. Тогда структуру кода определяют нижеследующие характеристики.
1. Число информационных символов, поступающих за один такт на вход кодера — k.
2. Число символов на выходе кодера — n, соответствующих k, поступившим на вход символам в течение такта.
3. Скорость кода определяется отношением R=k/n и характеризует избыточность, вводимую при кодировании.
4. Избыточность кода 
5. Память кода (входная длина кодового ограничения или информационная длина кодового слова), определяется максимально степенью порождающего многочлена в составе порождающей матрицы G(X):

6. Маркировка сверточного кода обозначается в большинстве случаев (n, k, l), но возможны и вариации.
7. Вес w двоичных кодовых последовательностей определяется числом «единиц», входящих в эту последовательность или кодовые слова.
8. Кодовое расстояние  показывает степень различия между i-й и j-й кодовыми комбинациями при условии их одинаковой длины. Для любых двух двоичных кодовых комбинаций кодовое расстояние равно числу несовпадающих в них символов. В общем виде кодовое расстояние может быть определено как суммарный результат сложения по модулю 2 одноименных разрядов кодовых комбинаций
показывает степень различия между i-й и j-й кодовыми комбинациями при условии их одинаковой длины. Для любых двух двоичных кодовых комбинаций кодовое расстояние равно числу несовпадающих в них символов. В общем виде кодовое расстояние может быть определено как суммарный результат сложения по модулю 2 одноименных разрядов кодовых комбинаций 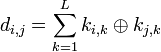 , где
, где 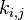 и
и  — k-е символы кодовых комбинаций i и j; L- длина кодовой комбинации.
— k-е символы кодовых комбинаций i и j; L- длина кодовой комбинации.
9. Минимальное кодовое расстояние 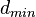 — это наименьшее расстояние Хемминга для набора кодовых комбинаций постоянной длины. Для его нахождения необходимо перебрать все возможные пары кодовых комбинаций. Тогда получаем
— это наименьшее расстояние Хемминга для набора кодовых комбинаций постоянной длины. Для его нахождения необходимо перебрать все возможные пары кодовых комбинаций. Тогда получаем  . Но! Это определение справедливо для блочных кодов имеющих постоянную длину. Сверточные коды являются непрерывными и характеризуются многими минимальными расстояниями, определяемыми длинами начальных сегментов кодовых последовательностей, между которыми берется минимальное расстояние. Число символов в принятой для обработки длине сегменты L определяет на приемной стороне число ячеек в декодирующем устройстве.
. Но! Это определение справедливо для блочных кодов имеющих постоянную длину. Сверточные коды являются непрерывными и характеризуются многими минимальными расстояниями, определяемыми длинами начальных сегментов кодовых последовательностей, между которыми берется минимальное расстояние. Число символов в принятой для обработки длине сегменты L определяет на приемной стороне число ячеек в декодирующем устройстве.
Общий вид двоичного сверточного кодера[править | править вики-текст]
Пусть регистр сдвига содержит m ячеек, то есть память кода равна m, коммутатор производит один цикл опроса, проходя значения  информационных символов, где m кратно k, при этом за один цикл он опрашивает n
информационных символов, где m кратно k, при этом за один цикл он опрашивает n  2 выходов кодера. Количество выходных кодовых символов, на которое оказывает влияние изменение одного входного информационного символа равно
2 выходов кодера. Количество выходных кодовых символов, на которое оказывает влияние изменение одного входного информационного символа равно  . Величина Iall называется полной длинной кодового ограничения.
. Величина Iall называется полной длинной кодового ограничения.
Поскольку корректирующие свойства конкретного сверточного кода определяются длиной кодового ограничения и выбором связей сдвигающего регистра на сумматор по модулю 2 (XOR), то для задания структуры сверточного кодера необходимо указать какие разряды регистра сдвига связаны с каждым из сумматоров по модулю 2 (XOR).
Связь j-го сумматора по модулю 2 описывается j-ой порождающей последовательностью:
gj=(gj0, gj1,gj2,…,gjm-1), (4.1)
где  (4.2)
(4.2)
Типичные параметры сверточных кодов: k, n= 1,2,…,8; R=k/n=1/4,…,7/8; m=2,…,10.
Способ задания сверточных кодов[править | править вики-текст]
Сверточный код удобно задавать с помощью порождающих многочленов, которые определяются видом формулы (4.1) по аналогии с тем, как это осуществляется для линейных блоковых циклических кодов.
Подробную информацию о циклических кодах читатель сможет найти в учебном пособии Сагаловича Ю. Л. «Введение в алгебраические коды»[1] в главах 4 и 5.
Порождающий многочлен полностью определяет структуру двоичного кодера сверточного кода. В отличие от блоковых кодов, каждый из которых описывается лишь одним порождающим многочленом, сверточный код описывается несколькими порождающими многочленами. Количество многочленов, которыми описывается сверточный код определяется количеством выходных символов n. Представим последовательность информационных символов, поступающих на вход кодера в виде многочлена:  , где Xi — символ оператора задержки на i тактов работы сдвигающего регистра, ai = {0,1} — информационные двоичные символы. Многочлены, описывающие n последовательностей кодовых символов, поступающих на вход коммутатора кодера а затем в канал связи, имеют вид:
, где Xi — символ оператора задержки на i тактов работы сдвигающего регистра, ai = {0,1} — информационные двоичные символы. Многочлены, описывающие n последовательностей кодовых символов, поступающих на вход коммутатора кодера а затем в канал связи, имеют вид:  , где
, где 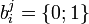 двоичные кодовые символы на j-ом входе коммутатора кодера.
двоичные кодовые символы на j-ом входе коммутатора кодера.
j-й порождающий многочлен сверточного кода имеет вид:  , где
, где  двоичные коэффициенты, равные 1, если i-я ячейка сдвигающего регистра через схему суммирования связана с j-ым коммутатором кодера, и равны 0 в противном случае. Причем, в силу линейности сверточного кода и принятых обозначений получаем:
двоичные коэффициенты, равные 1, если i-я ячейка сдвигающего регистра через схему суммирования связана с j-ым коммутатором кодера, и равны 0 в противном случае. Причем, в силу линейности сверточного кода и принятых обозначений получаем: 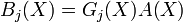 .
.
Используя представление сверточного кода с помощью порождающих многочленов, можно задавать сверточный код посредством последовательностей коэффициентов производящих многочленов, записанных в двоичной или восьмеричной форме. Запись в восьмеричной форме более компактная и используется при большой длине сдвигающего регистра кодера.
В общем случае последовательность коэффициентов j-ого производящего многочлена будет иметь вид  и совпадает с порождающей последовательностью кода (4.1). Тогда, если
и совпадает с порождающей последовательностью кода (4.1). Тогда, если  — последовательность кодируемых символов, а
— последовательность кодируемых символов, а 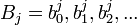 — последовательность кодовых символов на j-ом входе коммутатора кодера, то для любого из них, появляющегося в
— последовательность кодовых символов на j-ом входе коммутатора кодера, то для любого из них, появляющегося в  -й момент времени (
-й момент времени ( ), можно записать:
), можно записать:
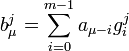 Таким образом, каждый кодовый символ выходной последовательности кодера сверточного кода определяется сверткой кодируемой информационной и порождающей последовательности, что и обуславливает названиесверточных кодов. Сверточные коды являются частным случаем итеративных или рекуррентных кодов.
Таким образом, каждый кодовый символ выходной последовательности кодера сверточного кода определяется сверткой кодируемой информационной и порождающей последовательности, что и обуславливает названиесверточных кодов. Сверточные коды являются частным случаем итеративных или рекуррентных кодов.
Применение[править | править вики-текст]
Сверточные коды используются для надежной передачи данных: видео, мобильной связи, спутниковой связи. Они используются вместе с кодом Рида — Соломона и другими кодами подобного типа. До изобретения турбо-кодов такие конструкции были наиболее действенными и удовлетворяли пределу Шеннона. Так же свёрточное кодирование используется в протоколе 802.11a на физическом MAC-уровне для достижения равномерного распределения 0 и 1 после прохождения сигнала через скремблер, вследствие чего количество передаваемых символов увеличивается в два раза и, следовательно, мы можем добиться благоприятного приема на принимающем устройстве.
Причины возникновения ЧС и сопутствующие им условия подразделяют на внутренние и внешние.
[править]Внутренние причины
К внутренним относятся:
§ сложность технологий;
§ недостаточная квалификация и некомпетентность обслуживающего персонала;
§ проектно-конструкторские недоработки в механизмах и оборудовании;
§ физический и моральный износ оборудования и механизмов;
§ низкая трудовая и технологическая дисциплины и др.
[править]Внешние причины
К внешним относятся:
§ стихийные бедствия;
§ неожиданное прекращение подачи электроэнергии, газа, технологических продуктов (интернет);
§ терроризм;
§ войны
|
|
Дата добавления: 2017-02-01; Просмотров: 73; Нарушение авторских прав?; Мы поможем в написании вашей работы!