КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Рекуррентный алгоритм поиска решения МЦП
|
|
|
|
Автор: Вилисов Валерий Яковлевич, профессор кафедры Математики Технологического университета (г. Королев, Моск. обл.)
Рекуррентный алгоритм (РА) применяют для ограниченного числа шагов МЦП 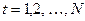 . Процедура выбора решений рассматривается как задача динамического программирования (ЗДП).
. Процедура выбора решений рассматривается как задача динамического программирования (ЗДП).
По аналогии с ЗДП оптимальный суммарный платеж 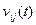 , за оставшиеся t шагов, при перехода из
, за оставшиеся t шагов, при перехода из  -го состояния в j -ое (
-го состояния в j -ое (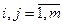 ), при условии принятия решения
), при условии принятия решения 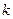 , можно выразить через платеж за один шаг и оптимальный суммарный платеж за оставшиеся (t +1) шагов:
, можно выразить через платеж за один шаг и оптимальный суммарный платеж за оставшиеся (t +1) шагов:
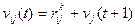 .
.
А поскольку процесс может перейти из -го состояния в любое j -ое с вероятностью 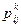 , то условный (при условии выбора решения k) средний платеж:
, то условный (при условии выбора решения k) средний платеж:
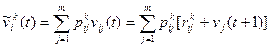 .
.
Величина 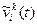 является целевой функцией (ЦФ) для выбора наилучшего k -го решения на t -ом шаге. Как и в ЗДП кроме решения ЦФ зависит и от текущего состояния i. Тогда, если платеж имеет смысл выигрыша, то уравнение Беллмана примет вид:
является целевой функцией (ЦФ) для выбора наилучшего k -го решения на t -ом шаге. Как и в ЗДП кроме решения ЦФ зависит и от текущего состояния i. Тогда, если платеж имеет смысл выигрыша, то уравнение Беллмана примет вид:
 . (1)
. (1)
А поскольку число шагов ограничено (N), то логично считать, что для (N +1)-го шага:
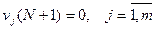 . (2)
. (2)
Соотношение (1) представляет собой рекуррентное уравнение ЗДП, позволяющее найти оптимальное решение для каждого шага процесса. Поскольку в задаче (1)-(2) учитывается случайный характер выигрыша, её называют стохастической ЗДП.
Введя обозначение
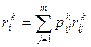 , (3)
, (3)
уравнение (1) для последнего шага, с учетом (2), можно записать в таком виде:
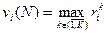 , (4)
, (4)
а для остальных шагов:
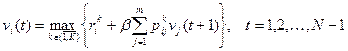 , (5)
, (5)
где 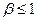 - коэффициент дисконтирования.
- коэффициент дисконтирования.
Как и в ЗДП, условно-оптимальные решения отыскивается в обратном порядке (от последнего шага к начальному), а затем оптимальные – в прямом.
Алгоритм (4) - (5) можно применять и при нестационарных (изменяющихся по шагам) матрицах 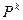 и
и 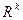 .
.
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 424; Нарушение авторских прав?; Мы поможем в написании вашей работы!