КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Реализация принципов векторной обработки
|
|
|
|
Рассмотрим механику векторной обработки на примере сложения двух одномерных массивов A(NDIM) и B(NDIM) размерности NDIM и запись результата в C(NDIM):
C=A+B
Данной операции присущ параллелизм - сложение элементов массивов Ai и Bi есть независимые процессы, которые могут исполняться параллельно. В алгоритмических языках высокого уровня (C, Fortran, Pascal и т.п.) существуют специальные операторы цикла, необходимые для исполнения данного суммирования:
do i=1, NDIM
Ci=Ai+Bi
end do
В вычислительной системе с последовательной (скалярной) обработкой данный цикл будет исполняться последовательно: приращение индекса цикла, загрузка операндов Ai и Bi, выполнение сложения, запись результата и т.д.
При выполнении каждой итерации цикла из оперативной памяти считываются последовательно команды, дешифрируются и выполняются. Результаты выполнения команд записываются в заданные места строго в порядке, предусмотренном программой.
Плавному течению конвейера в вычислительной системе мешает много явлений, в частности: зависимости по данным; условные переходы. В рассмотренном простом цикле нельзя выполнять операцию сложения пока не будут получены из оперативной памяти оба операнда; нельзя выполнять запись результата (очередного элемента массива С) до завершения операции сложения.
В итоге, даже при использовании всех современных методов разрешения конфликтных ситуаций (изменения порядка выполнения команд, переименования регистров, предсказания переходов, выполнения ветвей программы по предположению и т.п.) не удается обеспечить необходимую загрузку конвейера, а значит, и добиться максимально возможной производительности.
Итак, реализация операций обработки векторов на скалярных процессорах с помощью обычных циклов ограничивает скорость вычислений по следующим причинам:
перед каждой скалярной операцией необходимо вызывать и декодировать скалярную команду;
для каждой команды необходимо вычислять адреса элементов данных;
данные должны вызываться из оперативной памяти, а результаты запоминаться в оперативной памяти. В больших вычислительных системах оперативная память выполняется, как правило, в виде набора модулей, доступ к которым может осуществляться одновременно. В условиях, когда каждая команда вырабатывает свой собственный запрос к оперативной памяти, такой раздробленный доступ может стать причиной возникновения конфликтов обращения к оперативной памяти, препятствующих эффективному использованию ее потенциальной пропускной способности.
необходимо осуществлять упорядочение выполнения операций в функциональных устройствах. В целях увеличения производительности эти устройства строятся по конвейерному принципу. Эффективному использованию конвейерных устройств препятствует последовательная “природа” оператора цикла.
реализация команд построения циклов (счетчик и переход) сопровождается накладными расходами. Кроме того, наличие в цикле команды перехода препятствует эффективному использованию принципа опережающего просмотра.
В тоже время анализ алгоритма показывает, что имеется возможность выполнять одноименную операцию сложения над всеми элементами исходных массивов без конфликтов. Причем, чем больше размер этих массивов, тем больше простор для параллельной работы.
Эффект параллельности будет достигнут если вычислительная система будет оперировать с векторными командами. В зависимости от типа векторной вычислительной системы возможны различные варианты. Например, в векторной вычислительной системе операции обработки выполняются только при условии, что операнды находятся в векторных регистрах и результат тоже заносится в один из векторных регистров. Тогда в рассмотренном примере, при условии, что размерность векторных регистров равна или больше размерности векторных операндов, нам необходимы всего 4 векторные команды: 2 команды засылки операндов в векторные регистры, одна команда сложения и одна команда записи результата в оперативную память. Конечно, кроме этих четырех векторных команд необходимы и скалярные команды, которые подготовят начальные адреса векторов, шаги – при необходимости. Однако, даже с учетом этих вспомогательных скалярных команд, производительность вычислительной системы с векторными командами будет существенно выше обычной последовательной (скалярной) вычислительной системы, так как после начала выполнения векторной команды нет необходимости считывать из оперативной памяти очередные команды последовательного цикла, дешифрировать их, заниматься преодолением конфликтных ситуаций, препятствующих работе конвейера.
Векторные операции обеспечивают идеальную возможность полной загрузки вычислительного конвейера. При выполнении векторной команды одна и та же операция применяется ко всем элементам вектора (или чаще всего к соответствующим элементам пары векторов). Для настройки конвейера на выполнение конкретной операции может потребоваться некоторое установочное время, однако затем операнды могут поступать в конвейер с максимальной скоростью, допускаемой возможностями оперативной памяти. При этом не возникает пауз ни в связи с выборкой новой команды, ни в связи с определением ветви вычислений при условном переходе. Таким образом, главный принцип вычислений в векторной вычислительной системе состоит в выполнении некоторой элементарной операции или комбинации из нескольких элементарных операций, которые должны повторно применяться к некоторому блоку данных. Таким операциям в исходной программе соответствуют небольшие компактные циклы.
Теоретически ускорение за счет векторизации по сравнению с последовательным кодом могло бы составить величину, равную длине вектора процессора (при условии, что векторная и скалярная операции выполняются за один и тот же момент времени). Однако, в действительности время исполнения векторной команды больше времени последовательной за счет необходимости времени на загрузку операндов в векторные регистры, дешифровку и запуск команд. Поэтому реальное ускорение всегда меньше теоретического. Пример ускорения при вычислении суммы двух векторов (массивов) за счет использования векторной команды приведен на рис. 1.
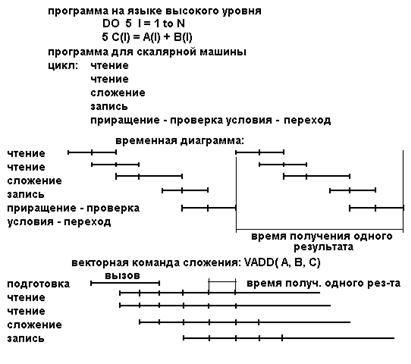
Рис. 1. Вычисление суммы двух векторов на скалярном и векторном процессоре.
Итак, изучение искусства оптимизации скалярных программ показывает, что первым ограничивающим повышение скорости счета фактором является время, необходимое на реализацию отдельной команды. Исполнение даже одной арифметической операции требует исполнения еще нескольких команд. Время, затрачиваемое именно на эти последние команды, становится критическим фактором. Чем больше арифметических операций, тем данная проблема становится острее. Если бы вычислительная система могла «знать», что, например, существует множество арифметических операций, которые нужно выполнять, то появилась бы возможность исполнять отдельные действия параллельно: передавать операнды из оперативной памяти в функциональные устройства, выполнять отдельные этапы арифметических операций, возвращать результаты в оперативную память, вести счетчик требуемого числа повторений операций и др. Этот конвейерный процесс в точности есть именно то, из чего состоит векторная обработка. Руководствуясь одной командой, векторный процессор как бы создает конвейерную линию, исполняющую операцию, заданную в команде без прерываний и без необходимости готовить и исполнять для каждой пары операндов дополнительные команды.
Работа векторного процессора в таком режиме требует координации его различных стадий. Для этого структура вычислительной системы должна иметь более высокий уровень логических возможностей. Необходимо также, чтобы структура данных была достаточно регулярной, чтобы эти логические возможности и оборудование векторного процессора могли быть использованы в полной мере. Назовем эти структурированные данные векторами. К другим характеристикам векторов относятся следующие:
для векторов, длина которых меньше максимальной, установочное (стартовое время) является одинаковым и не зависящим от длины. Следовательно, чем длиннее векторы, тем выше производительность.
поскольку элементы одного вектора обрабатываются параллельно разными устройствами, между ними не может быть взаимодействия на протяжении всего времени выполнения векторной операции. Это означает, что между элементами вектора при выполнении векторной операции не может быть никаких рекурсивных связей.
Векторная обработка реализуется в вычислительных системах двух типов: векторно-матричных и векторно-конвейерных.
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 625; Нарушение авторских прав?; Мы поможем в написании вашей работы!