КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Второе десятилетие XXI века
|
|
|
|
Следующим шагом КНР будет, возможно, гетерогенный, гиперпараллельный суперкомпьютер на базе массивно-мультитредовых и потоковых процессоров собственного производства, толерантный к задержкам выполнения операций с огромной глобально адресуемой пространственно распределенной памятью.
Сегодня исследователи из развитых стран приступили к концептуальной проработке систем экзафлопного уровня, концентрируясь на необходимости решения основных проблем современных суперкомпьютеров, в частности:
· устранить «стену памяти», не позволяющую «снимать» с современных суперкомпьютеров реальную производительность выше 5-10% пиковой на задачах с плохой пространственно-временной локализацией обращений к памяти;
· добиться масштабируемости производительности и отказоустойчивости при увеличении количества процессоров;
· снизить энергопотребление.
Решение всех этих проблем и было определено в числе главных целей проекта 863, который по мнению его разработчиков, как и аналогичные проекты США и Японии, будет промежуточным (кремниевым) этапом при переходе к квантовым компьютерам.
Характерно, что при этом явно осознается тот факт, что путем увеличения количества однородных ядер в коммерчески доступных процессорах экзафлопный барьер преодолеть не удастся, поскольку еще сильнее обостряются проблемы «стены памяти», плохой масштабируемости и чрезмерного энергопотребления. Если двигаться по проторенному пути использования коммерческих процессоров с увеличивающимся количеством ядер, то экзафлопная система-монстр будет потреблять около 200 МВт, что практически неприемлемо.
Надо полагать, что, как и зарубежные коллеги, из множества вариантов создания экзафлопных систем китайские специалисты выберут два взаимодополняющих решения: многоядерные гетерогенные мультитредово-потоковые архитектуры и 3D-сборку (трехмерные СБИС)]. Такие стратегические суперкомпьютерные технологии, по-видимому, и позволят создать экзафлопную китайскую СКСН по проекту 863.
Системность государственной организации работ в области стратегических суперкомпьютерных технологий на базе серьезных экспертных проработок, высокий профессионализм специалистов, продемонстрированные темпы роста и масштабность позволяют предположить, что к середине следующего десятилетия КНР вполне может стать лидером в этой области.
Процессоры: made in Сhina
Процессор FT64 (рис. 1) базируется на 32-разрядном процессоре Imagine Стэндфордского университета, предназначенном для мультимедийной обработки, но в отличие от него FT64 ориентирован на научные вычисления, работает с 64-разрядными данными и подключается к Itanium 2 как процессор-ускоритель.
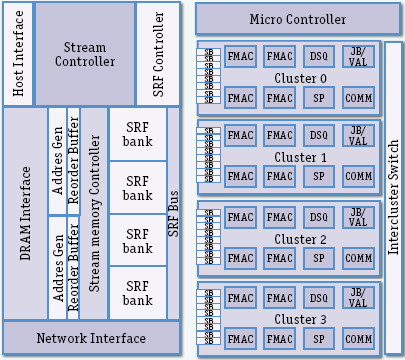
Рис. 1
Host Interface – интерфейс с управляющим процессором, в качестве него используется Itanium 2; DRAM Interface – интерфейс с внекристальной динамической памятью, у каждого FT64 своя такая внешняя память (cм. DDR2 DIMM на рис. 2); Network Interface – интерфейс с внутриплатной сетью, могут быть разные топологии; Addres Gen – адресный генератор; Reorder Buffer – буфер переупорядочения; Stream memory Controller – контроллер потоковой памяти; SRF bank – банк файла потоковых регистров; SRF Bus – общая шина банков файла потоковых регистров; Stream Controller – контроллер потоков данных, получает указания от управляющего процессора, передает их в контроллер потоковой памяти и микроконтроллер арифметических кластеров; SRF Controller – контроллер файла потоковых регистров; Cluster 0,1,2,3 – арифметические кластеры, содержат множество функциональных устройств и настраиваемый коммутатор для передачи данных между ними, управляются одной широкой командой, выдаваемой микроконтроллером; Micro Controller – микроконтроллер арифметических кластеров; Intercluster Switch – межкластерный коммутатор, позволяющий соединять функциональные устройства разных арифметических кластеров; SB – потоковый буфер для сборки/разборки потоков данных, удобных по организации для работы конвейерных алгоритмов обработки, реализуемых в арифметических кластерах; FMAC – устройство выполнения операции умножения и сложения над 64-разрядными числами в формате с плавающей запятой; DSQ – устройство выполнения деления и извлечения квадратного корня; SP – регистровая блокнотная память; COMM – блок связи с межкластерным коммутатором; JB/VAL (jump bit/check value) – блок проверки «на лету» по заданным условиям битов пакетов сообщений, преобразование их и при невыполнении условий – отбраковка.
Потоковая модель вычислений – это вычислительный граф, в узлах которого находятся вычислительные ядра, а по дугам передаются данные в виде наборов записей однородных данных. В FT64 вычислительные ядра реализуются на четырех арифметических кластерах, в каждом из которых по четыре 64-разрядных конвейерных устройства сложения-умножения c локальными регистровыми файлами LRF на входах. Вычислительные ядра отображаются на арифметические кластеры, передача данных между ядрами происходит через потоковые регистровые файлы SRF, имеющие объем 256 Кбайт, а для более сложных случаев – через внешнюю DRAM-память и блок интерфейса с внешней сетью.
Соотношение пропускной способности DRAM, LRF и SRF – 1:10:85, что принципиально для процессоров такого типа. Управление арифметическими кластерами и передачами данных осуществляется внутрикристальным контроллером и микроконтроллером, который содержит память 2Kх688 бит команд. FT64 был разработан за один год с использованием технологии 130 нм на кристалле 12х12 мм с тактовой частотой 500 МГц и потреблением 8,6 Вт. Пиковая производительность такого кристалла – 16 GFLOPS. На оценочных тестах научных приложений один FT64 развивает реальную производительность в 4,2 раза выше, чем Itanium 2/1,6 ГГц, а плата из восьми процессоров дает почти линейный прирост в 6,8 раза. Ускоритель из восьми процессоров по энергетической эффективности превосходит Itanium 2 почти в 100 раз.
Проект MASA сравним с проектами Merrimac и TRIPS (США), ориентированными на бортовые приложения, но процессор MASA можно считать обобщенной реализацией на кристалле одной платы с несколькими FT64. Если в FT64 используется параллелизм уровня машинных команд и обработки данных (ILP- и DLP-параллелизм), то в MASA используется еще и тредовый (TLP) параллелизм. Один процессор MASA содержит два MIPS-процессора, управляющих 2D-сетью четырехъядерных блоков (тайлов), каждое ядро которых можно сопоставить с одним FT64. Ядро содержит 16 конвейерных АЛУ обработки вещественных чисел, файл потоковых регистров (SRF), потоковые буферы (SB) и локальные регистровые файлы (LRF). На периферии 2D-сети тайлов процессор MASA имеет интерфейсы с памятью и внешними устройствами с программируемым локальным управлением. Вариант процессора MASA с 256 АЛУ, реализованный по норме 45 нм, может развивать реальную производительность в 100-350 GFLOPS на большинстве оценочных тестов. Например, на задаче трехмерного преобразования Фурье процессор MASA 1 ГГц с пиковой производительностью 512 GFLOPS развивает реальную производительность 100,7 GFLOPS.
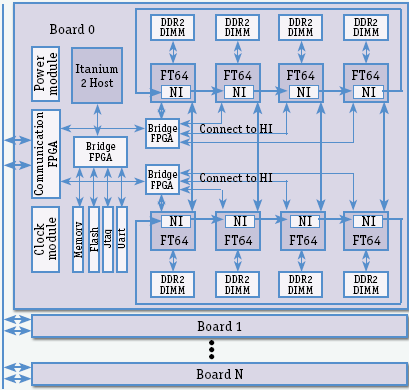
Рис. 2
Board 0,1...N – платы с процессорами FT64; DDR2 DIMM – внекристальная динамическая память, у каждого процессора FT64 своя; NI – блоки сетевых интерфейсов FT64; Bridge FPGA – схемы-мосты на программируемых логических матрицах; Memory – оперативная DRAM-память платы; Flash – внешняя флэш-память; Jtag – специализированный аппаратный интерфейс тестирования; Uart – универсальный асинхронный приемопередатчик, производит преобразование параллельного кода в последовательный при выдаче и обратно – при приеме; Power module – модуль источника питания; Сlock module – модуль выдачи тактовых сигналов; Communication FPGA – коммуникационная схема на программируемой логической матрице; Itanium 2 Host – управляющий процессор платы в виде процессора Itanium 2; Connect to HI – подключение к интерфейсу FT64 с управляющим процессором, по нему осуществляется управление процессорами FT64 и их контроль.
Толерантность работы с памятью лучшим образом обеспечивают мультитредовые процессоры. Исторически сложилось, что тут выделяется направление с малым количеством тредов в процессорном ядре (единицы) и массово-мультитредовые процессоры с большим количеством тредов (сотни) в ядре. В Китае ведутся работы по мультитредовым процессорам первого направления, причем для VLIW- или EPIC-архитектур реализуется наиболее сложная – SMT-мультитредовость. Мультитредовые процессоры второго типа с запуском VLIW-команды за такт от одного треда применяются в Cray XMT, а в более обобщенном виде, с запуском за такт нескольких RISC-команд, но от разных тредов ядра, – в российском массово-мультитредовом процессоре СКСН «Ангара».
Контрольные вопросы
1. Какая суммарная производительность систем списка ТОР500 на 2010 г.?
2. Какие производительности необходимо иметь на 2019 г.?
3. Кто лидирует в области суперкомпьютеров?
4. Какие цели и задачи поставлены в программе DARPA HPCS?
5. Какая связь между простанственно-временной локальностью и реальной производительностью?
6. Как выполняется программа DARPA HPCS?
7. Какие проблемы надо решить при создании суперкомпьютеров с экзафлопной производительностью?
8. Что такое «стена памяти»?
9. Какие пути достижения экзафлопной призводительности?
10. Что подразумевает эволюционный путь?
11. Что подразумевает революционный путь?
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 1409; Нарушение авторских прав?; Мы поможем в написании вашей работы!