КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Введение. Citius, Altius, Fortius – девиз Олимпийских игр современности, как ни к какой другой области
"Citius, Altius, Fortius" – девиз Олимпийских игр современности, как ни к какой другой области, применим к вычислительной технике. Воплощение в жизнь не раз видоизменявшего свою исходную формулировку, но до сих пор действующего эмпирического закона сформулированного в 1965 году Гордоном Муром, похоже, стало "делом чести" производителей аппаратного обеспечения. Из всех известных формулировок этого закона точку зрения потребителя/пользователя наилучшим образом отражает вариант: "производительность вычислительных систем удваивается каждый 18 месяцев". Мы сознательно не использовали термин "процессор", поскольку конечного пользователя вовсе не интересует, кто обеспечивает ему повышение мощности: процессор, ускоритель, видеокарта, – ему важен лишь сам факт роста возможностей "за те же деньги".
Правда, в последние несколько лет возможности увеличения мощности процессоров на основе повышения тактовой частоты оказались фактически исчерпаны, и производители, выбрав в качестве магистрального пути развития увеличение числа ядер на кристалле, были вынуждены призвать на помощь разработчиков программного обеспечения. Старые последовательные программы, способные использовать лишь одно ядро, теперь уже не будут работать быстрее на новом поколении процессоров "задаром" – требуется практически повсеместное внедрение программирования параллельного.
Можно представить следующие направления развития параллельных технологий:
- Параллельные структуры отображают организацию и взаимодействие исполнителей сложного комплекса взаимосвязанных работ.
- Параллельное программирование объединяет проблемы оптимального статического и динамического планирования выполнения комплексов взаимосвязанных работ при заданном составе и структуре взаимодействия исполнителей.
- Параллельные алгоритмы являются естественным результатом оптимального решения задач распараллеливания. Применение многопроцессорных вычислительных систем, а, в особенности, бурно развивающиеся сетевые технологии для решения задач высокой сложности.
В 31-м списке Top500 (июнь 2008) впервые в истории был преодолен петафлопный порог производительности – суперкомпьютер "Roadrunner" [2] производства компании IBM показал на тесте LINPACK 1,026 петафлопс. Много это или мало? Если взять за основу, что реальная производительность хорошей "персоналки" на четырехъядерном процессоре составляет порядка 20 гигафлопс, то весь список Top500 будет эквивалентен половине миллиона таких персоналок. Представленные в списке Top500 данные позволяют проследить характерные тенденции развития индустрии в сфере суперкомпьютерных вычислений. Первый список Top500 датирован июнем 1993 года и содержит 249 систем класса SMP и 97, построенных на основе единственного процессора. Уже четырьмя годами позже в Top500 не осталось ни одной системы на основе единственного процессора. Все дальнейшее развитие шло под лозунгом; от суперкомпьютера к мини-кластеру.
Вспомним: кластер – группа компьютеров, объединенных в ЛВС и способных работать в качестве единого вычислительного ресурса.
Сегодня 75% систем в списке построены на основе процессоров компании Intel, чуть больше 13% – на процессорах компании IBM и 11% – компании AMD (на двух оставшихся производителей NEC и Cray приходится по одной системе соответственно); 81% систем используют всего два типа интерконнекта: Gigabit Ethernet или Infiniband; 85% систем работают под управлением операционной системы из семейства Linux. Как видим, разнообразием список не блещет, что является несомненным плюсом с точки зрения пользователей. Однако для пользователя массового еще большим плюсом была бы возможность иметь персональный суперкомпьютер у себя на столе или, на худой конец, стоящий под столом. Тенденция "персонализации" супервычислений в последнее время развивается все активнее и недавно была подхвачена в том числе и производителями видеокарт, мощности которых возросли настолько, что возникло естественное желание использовать их не только в графических расчетах, но и в качестве ускорителей вычислений общего назначения. Соответствующие решения представлены в настоящее время компанией NVIDIA (семейство NVIDIA Tesla™) и компанией AMD (семейство ATI FireStream™) и демонстрируют в силу специфики внутреннего устройства потрясающую (в сравнении с универсальными процессорами) пиковую производительность, превышающую 1 терафлопс.
Tesla™) и компанией AMD (семейство ATI FireStream™) и демонстрируют в силу специфики внутреннего устройства потрясающую (в сравнении с универсальными процессорами) пиковую производительность, превышающую 1 терафлопс.
Несколько лет назад в моде были казавшиеся вполне обоснованными прогнозы, когда именно будет преодолен тот или иной порог по тактовой частоте процессоров. Четыре-пять гигагерц виделись практически свершившимся фактом, десять маячили где-то недалеко впереди. Однако прогнозы эти на долгое время так и остались прогнозами. В некоторый момент оказалось, что тепло, выделяемое процессором, становится настолько большим, что о стабильной работе на частотах выше четырех гигагерц в условиях, характерных для обычных персональных компьютеров, и говорить не приходится 2) . Энтузиасты, используя дополнительное охлаждение, вплоть до жидкого азота, научились разгонять процессоры производства Intel выше 6 гигагерц, в отдельных случаях до 7 и даже 8, но о стабильной продолжительной работе на таких частотах речь не идет. Как просто было когда-то сравнивать процессоры компании Intel между собой. Все знали, есть Pentium, есть его "урезанный" вариант Celeron, а в остальном, чем выше частота, тем лучше. Эта простота была следствием того факта, что в формуле, определяющей производительность вычислительной системы "тактовая частота процессора * число инструкций, выполняемых за один такт (Instructions Per Cycle, IPC)" переменной величиной была только частота. Необходимо, конечно, отметить, что получаемая по этой формуле величина, дает только так называемую "пиковую производительность", приблизиться к которой на практике можно лишь на отдельных специально подобранных задачах.
Классификация архитектур по параллельной обработке данных
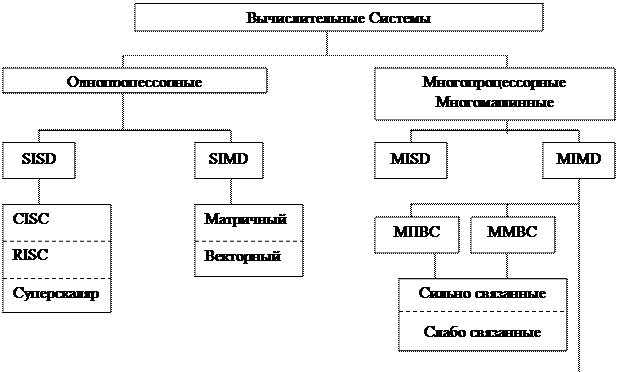
В 1966 году М.Флинном (Flynn) был предложен чрезвычайно удобный подход к классификации архитектур вычислительных систем. В основу было положено понятие потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. Соответствующая система классификации основана на рассмотрении числа потоков инструкций и потоков данных и описывает четыре архитектурных класса.
1. SISD (single instruction stream / single data stream) - одиночный поток команд и одиночный поток данных. К этому классу относятся последовательные компьютерные системы, которые имеют один центральный процессор, способный обрабатывать только один поток последовательно исполняемых инструкций. В настоящее время практически все высокопроизводительные системы имеют более одного центрального процессора, однако, каждый из них выполняют несвязанные потоки инструкций, что делает такие системы комплексами SIMD-систем, действующих на разных пространствах данных. Примерами компьютеров с архитектурой SISD являются большинство рабочих станций Compaq, Hewlett-Packard и Sun Microsystems.
2. MISD (multiple instruction stream / single data stream) - множественный поток команд и одиночный поток данных. Теоретически в этом типе машин множество инструкций должны выполнятся над единственным потоком данных. До сих пор ни одной реальной машины, попадающей в данный класс, не было создано. В качестве аналога работы такой системы, по-видимому, можно рассматривать работу банка. С любого терминала можно подать команду и что-то сделать с имеющимся банком данных. Поскольку база данных одна, а команд много, то мы имеем дело с множественным потоком команд и одиночным потоком данных.
3. SIMD (single instruction stream / multiple data stream) - одиночный поток команд и множественный поток данных. Эти системы обычно имеют большое количество процессоров, в пределах от 1024 до 16384, которые могут выполнять одну и ту же инструкцию относительно разных данных в жесткой конфигурации. Единственная инструкция параллельно выполняется над многими элементами данных. Примерами SIMD машин являются системы CPP DAP, Gamma II и Quadrics Apemille. Другим подклассом SIMD-систем являются векторные компьютеры. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. Это делается за счет использования специально сконструированных векторных центральных процессоров. При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Примерами систем подобного типа является, например, компьютеры Hitachi S3600.
4. MIMD (multiple instruction stream / multiple data stream) - множественный поток команд и множественный поток данных. Эти машины параллельно выполняют несколько потоков инструкций над различными потоками данных. В отличие от многопроцессорных SISD-машин, упомянутых выше, команды и данные связаны, потому что они представляют различные части одной и той же выполняемой задачи. Например, MIMD-системы могут параллельно выполнять множество подзадач, с целью сокращения времени выполнения основной задачи. Наличие большого разнообразия попадающих в данный класс систем, делает классификацию Флинна не полностью адекватной. Действительно и четырех-процессорный SX-5 компании NEC и тысяче-процессорный Cray T3E оба попадают в этот класс. Это заставляет использовать другой подход к классификации, иначе описывающий классы компьютерных систем. Основная идея такого подхода может состоять, например, в следующем. Считаем, что множественный поток команд может быть обработан двумя способами: либо одним конвейерным устройством обработки, работающем в режиме разделения времени для отдельных потоков, либо каждый поток обрабатывается своим собственным устройством. Первая возможность используется в MIMD компьютерах, которые обычно называют конвейерными или векторными, вторая – в параллельных компьютерах. В основе векторных компьютеров лежит концепция конвейеризации, т.е. явного сегментирования арифметического устройства на отдельные части, каждая из которых выполняет свою подзадачу для пары операндов. В основе параллельного компьютера лежит идея использования для решения одной задачи нескольких процессоров, работающих сообща, причем процессоры могут быть как скалярными, так и векторными. На рисунке 12.1 приведен пример такой классификации.
 | |||
|
Рис. 12.1 Классификация ВС
|
|
Дата добавления: 2014-01-04; Просмотров: 523; Нарушение авторских прав?; Мы поможем в написании вашей работы!