КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция 02
|
|
|
|
Рис. 14.1
Кодирование длин повторений
Лекция 14
Кодирование длин участков (или повторений) может быть достаточно эффективным при сжатии двоичных данных, например, черно-белых факсимильных изображений, черно-белых изображений, содержащих множество прямых линий и однородных участков, схем и т.п. Кодирование длин повторений является одним из элементов известного алгоритма сжатия изображений JPEG.
Идея сжатия данных на основе кодирования длин повторений состоит в том, что вместо кодирования собственно данных подвергаются кодированию числа, соответствующие длинам участков, на которых данные сохраняют неизменное значение.
Предположим, что нужно закодировать черно-белое (двухцветное) изображение размером 8 х 8 элементов, приведенное на рис. 14.1
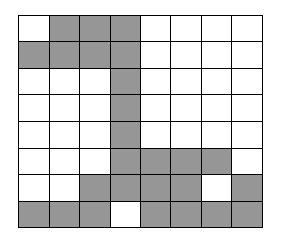 |
Просканируем это изображение по строкам (двум цветам на изображении будут соответствовать 0 и 1), в результате получим двоичный вектор данных
X= (0111000011110000000100000001000000010000000111100011110111101111)
длиной 64 бита (исходный код составляет 1 бит на элемент изображения).
Выделим в векторе X участки, на которых данные сохраняют неизменное значение, и определим их длины. Результирующая последовательность длин участков - положительных целых чисел, соответствующих исходному вектору данных X, - будет иметь вид r = (1, 3, 4, 4, 7, 1, 7, 1, 7, 1, 7, 4, 3, 4, 1, 4, 1, 4).
Теперь эту последовательность, в которой заметна определенная повторяемость (единиц и четверок гораздо больше, чем других символов), можно закодировать каким-либо статистическим кодом, например, кодом Шеннона-Фано без памяти, имеющим таблицу кодирования (табл. 15.1)
Таблица 14.1
| Кодер | |
| Длина участка | Кодовое слово |
Для того, чтобы указать, что кодируемая последовательность начинается с нуля, добавим в начале кодового слова префиксный символ 0. В результате получим кодовое слово B (r) = (0100011010110101101011001110100100) длиной в 34 бита, то есть результирующая скорость кода R составит 34/64, или немногим более 0,5 бита на элемент изображения. При сжатии изображений большего размера и содержащих множество повторяющихся элементов эффективность сжатия может оказаться существенно более высокой.
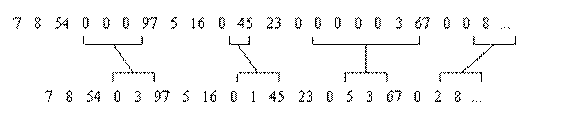
Существует еще один метод использования кодирования длин повторений, когда в цифровых данных встречаются участки с большим количеством нулевых значений. Всякий раз, когда в потоке данных встречается “ ноль ”, он кодируется двумя числами. Первое - 0, являющееся флагом начала кодирования длины потока нулей, и второе – количество нулей в очередной группе. Если среднее число нулей в группе больше двух, будет иметь место сжатие. С другой стороны, большое число отдельных нулей может привести даже к увеличению размера кодируемого файла:
 |
Еще одним простым и широко используемым для сжатия изображений и звуковых сигналов методом кодирования без потерь является метод дифференциального кодирования.
|
|
|
|
|
Дата добавления: 2013-12-11; Просмотров: 772; Нарушение авторских прав?; Мы поможем в написании вашей работы!