КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Генератор тактовых импульсов
|
|
|
|
Править] Пузырек
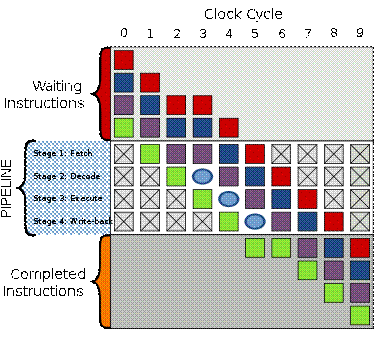

Пузырек в третьем такте обработки задерживает исполнение
Когда в выполнении по каким-либо причинам случается небольшой сбой или задержка, в конвейере получается «пузырек», в котором не происходит ничего полезного. Во втором такте обработка фиолетовой инструкции задерживается и вместо стадии расшифровки в третьем такте теперь находится пузырек. Всё, что находится «за» фиолетовой инструкцией, испытывает задержку в один такт, тогда как все, что находится «перед» фиолетовой инструкцией продолжает исполняться.
Очевидно, что наличие пузырька в конвейере дает суммарное время исполнения в 8 тактов вместо 7 на схеме исполнения, продемонстрированной выше.
Пузырьки — это как заглушки, в которых не случается ничего полезного при их прочтении, раскодировании, исполнении и записи результата. Они могут быть выражены при помощи инструкции NOP[1][2][3]ассемблера.
[править] Пример 1
Допустим, типичная инструкция для сложения двух чисел это СЛОЖИТЬ A, B, C. Эта инструкция суммирует значения, находящиеся в ячейках памяти A и B, а затем кладет результат в ячейку памяти C. В конвейерном процессоре контроллер может разбить эту операцию на последовательные задачи вида
Ячейки R1, R2 и R3 являются регистрами процессора. Значения, которые хранятся в ячейках памяти, которые мы называем A и B, загружаются (то есть копируются) в эти регистры, затем суммируются, и результат записывается в ячейку памяти C.
В данном примере конвейер состоит из трех уровней — загрузки, исполнения и записи. Эти шаги называются, очевидно, уровнями или шагами конвейера.
В бесконвейерном процессоре, только один шаг может работать в один момент времени, поэтому инструкция должна полностью закончиться прежде, чем следующая инструкция в принципе начнется. В конвейерном процессоре, все эти шаги могут выполняться одновременно на разных инструкциях. Поэтому когда первая инструкция находится на шаге исполнения, вторая инструкция будет на стадии раскодирования, а третья инструкция будет на стадии прочтения.
Конвейер не уменьшает время, которое необходимо для того, чтобы выполнить инструкцию, но зато он увеличивает объем (число) инструкций, которые могут быть выполнены одновременно и таким образом уменьшает задержку между выполненными инструкциями — увеличивая т. н. пропускную способность. Чем больше уровней имеет конвейер, тем больше инструкций могут выполняться одновременно и тем меньше задержка между завершенными инструкциями. Каждый микропроцессор, произведенный в наши дни, использует как минимум двухуровневый конвейер.
[править] Пример 2
Чтобы лучше продемонстрировать идею, давайте посмотрим на теоретический трехуровневый конвейер:
| Шаг | Описание |
| Загрузка | Прочитать инструкцию из памяти |
| Исполнение | Исполнить инструкцию |
| Запись | Записать результат в память и/или регистры |
и на псевдоассемблерный листинг, который нужно выполнить:
ЗАГРУЗИТЬ 40, A; загрузить число 40 в AКОПИРОВАТЬ A, B; скопировать A в BСЛОЖИТЬ 20, B; добавить 20 к BЗАПИСАТЬ B, 0x0300; записать B в ячейку памяти 0x0300Теперь как это всё будет исполняться:
| Такт 1 | ||
| Загрузка | Исполнение | Запись |
| ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ читается из памяти.
| Такт 2 | ||
| Загрузка | Исполнение | Запись |
| КОПИРОВАТЬ | ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ выполняется, тогда как инструкция КОПИРОВАТЬ читается из памяти.
| Такт 3 | ||
| Загрузка | Исполнение | Запись |
| СЛОЖИТЬ | КОПИРОВАТЬ | ЗАГРУЗИТЬ |
Инструкция ЗАГРУЗИТЬ находится на шаге записи результата, где её результат (то есть число 40) записывается в регистр А. В это же время, инструкция КОПИРОВАТЬ исполняется. Так как она должна скопировать содержимое регистра A в регистр B, она должна дождаться окончания инструкции ЗАГРУЗИТЬ.
| Такт 4 | ||
| Загрузка | Исполнение | Запись |
| ЗАПИСАТЬ | СЛОЖИТЬ | СКОПИРОВАТЬ |
Загружена инструкция ЗАПИСАТЬ, тогда как инструкция СКОПИРОВАТЬ прощается с нами, а по инструкции СЛОЖИТЬ в данный момент производятся вычисления.
И так далее. Следует учитывать, что иногда инструкции будут зависеть от результатов других инструкций (например, как наша инструкция СКОПИРОВАТЬ). Когда более, чем одна инструкция ссылается на определенное место, читая его (то есть используя в качестве входного операнда) либо записывая в него (то есть используя его в качестве выходного операнда), исполнение инструкций не в порядке, который был изначально запланирован в оригинальной программе может повлечь за собой «конфликт конвейера» (англ. en:Hazard (computer architecture)) (о чем упоминалось выше). Существует несколько зарекомендовавших себя приемов для либо предотвращения конфликтов, либо их исправления, если они случились.
[править] Трудности
Множество схем включают в себя конвейеры в 7, 10 или даже 20 уровней (как, например, в Intel Pentium 4). Поздние ядра Pentium 4 с кодовыми именами «Prescott» и «Cedar Mill» (и их Pentium D-производные) имеют 31-уровневый конвейер, самый длинный среди популярных процессоров. Xelerator X10q имеет конвейер длиной более, чем в тысячу шагов[4]. Обратной стороной медали в данном случае является необходимость сбрасывать весь конвейер в случае, если ход программы изменился (например, по условному оператору). Эту проблему пытаются решать предсказатели переходов (англ. en:Branch predictor). Предсказание переходов само по себе может только усугубить ситуацию, если предсказание производится плохо. В некоторых областях применения, таких как вычисления на суперкомпьютерах, программы специально пишутся так, чтобы как можно реже использовать условные операторы, поэтому очень длинные конвейеры весьма позитивно скажутся на общей скорости вычислений, так как длинные конвейеры проектируются так, чтобы уменьшить CPI (англ. Clocks Per Instruction, количество тактов на инструкцию). Если ветвление происходит постоянно, переорганизация таким образом, чтобы те инструкции, которые, скорее всего, понадобятся, были размещены в конвейере, может значительно уменьшить потери скорости по сравнению с необходимостью каждый раз полностью сбрасывать конвейер. Программы типа gcov могут использоваться для того, чтобы определять, как часто отдельные ветки исполняются на самом деле, используя технологию, известную как анализ покрытия кода (англ. Code coverage analysis), хотя на практике подобный анализ является последней мерой при оптимизации[ источник не указан 410 дней ].
Высокая пропускная способность конвейеров оборачивается тормозами в случае, если в исполняемом коде содержится много условных переходов: процессор не знает, откуда читать следующую инструкцию, и поэтому вынужден ждать, когда закончится инструкция условного перехода, оставляя за ней пустой конвейер. После того, как ветка будет пройдена и станет известно, куда процессору необходимо переходить в дальнейшем, следующая инструкция должна будет пройти весь путь через конвейер перед тем, как результат становится доступным и процессор снова «работает». В крайнем случае, производительность конвейерного процессора может теоретически упасть до производительности бесконвейерного, или даже быть хуже за счет того, что будет занят только один уровень конвейера и между уровнями присутствует небольшая задержка.
Из-за конвейера процессора, код, который загружает процессор, не будет исполнен мгновенно. Из-за этого, обновления в коде, которые находятся очень близко к текущему месту исполнения программы, могут пройти незамеченными из-за того, что код уже предзагружен в en:Prefetch Input Queue. Кэш инструкций еще больше усугубляют эту проблему. Стоит учитывать, что данная проблема присутствует только в самомодифицирующихся программах, а также в упаковщиках исполняемых файлов.
Генератор тактовой частоты (генератор тактовых импульсов) генерирует электрические импульсы заданной частоты (обычно прямоугольной формы) для синхронизации различных процессов в цифровых устройствах — ЭВМ, электронных часах и таймерах, микропроцессорной и другой цифровой технике. Тактовые импульсы часто используются как эталонная частота — считая их количество, можно, например, измерять временные интервалы.
В микропроцессорной технике один тактовый импульс, как правило, соответствует одной атомарной операции. Обработка одной инструкции может производиться за один или несколько тактов работы микропроцессора, в зависимости от архитектуры и типа инструкции. Частота тактовых импульсов определяет скорость вычислений.
[править] Типы генераторов
В зависимости от сложности устройства, используют разные типы генераторов.
[править] Классический
В несложных конструкциях, не критичных к стабильности тактового генератора, часто используется последовательное включение нескольких инверторов через RC-цепь. Частота колебаний зависит от номиналов резистора и конденсатора. Основной минус данной конструкции — низкая стабильность. Плюс — предельная простота.
[править] Кварцевый
Генератор Пирса.
[править] Кварц + микросхема генерации
Микросхема генерации представляет собой специальную микросхему, которая при подаче на её входную ногу сигнала с кварцевого резонатора будет выдавать на остальных выводах частоту, делённую или умноженную на исходную. Данное решение используется в часах, а также на старых материнских платах (где частоты шин были заранее известны, только внутренняя частота центрального процессора умножалась коэффициентом умножения).
[править] Программируемая микросхема генерации
В современных материнских платах необходимо большое количество разных частот, помимо опорной частоты системной шины, которые, по возможности, не должны быть зависимы друг от друга. Хотя базовая частота всё же формируется кварцевым резонатором (частота — 14,3 МГц), она необходима лишь для работы самой микросхемы. Выходные же частоты корректируются самой микросхемой. Например, частота системной шины может быть всегда равна стандартным 33 МГц, AGP — 66 МГц и не зависеть от частоты FSB процессора.
Если в электронной схеме необходимо разделить частоту на 2 используют Т-триггер в режиме счётчика импульсов. Соответственно, для увеличения делителя увеличивают количество счётчиков (триггеров).
[править] Тактовый генератор
Тактовый генератор — автогенератор, формирующий рабочие такты процессора («частоту»). В некоторых процессорах (например, Z80) выполняется встроенным.
Кроме тактовки процессора в обязанности тактового генератора входит организация циклов системной шины. Поэтому его работа часто тесно связана с циклами обновления памяти, контроллером ПДП и дешифратором сигналов состояния процессора.
|
|
|
|
|
Дата добавления: 2013-12-12; Просмотров: 1361; Нарушение авторских прав?; Мы поможем в написании вашей работы!