КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Микропроцессоры
|
|
|
|
Общая схема АЛУ для операции умножения
Построение АЛУ для выполнения операции умножения чисел с плавающей точкой
АЛУ для реализации операции деления.
Операция / является обратной по отн к операции *, поэтому общая структура операции заключается в последовательности вычитания значения делителя из делимого и (каких-то??) сдвигах.
Результат в виде текущего значения частичных разностей. Цифры частного определяются как 1при положительном значении частичных разностей и как нуль в противном случае.
Рассм. осн. требования: Частное Z как рез-т деления делимого X на делитель Y, Z=X/Y. Х представляется в формате двойного слова, т.е. занимает (2n-1) разрядов, Z и Y представлены в формате одинарного слова, т.е. занимают (n-1)разрядов. Поэтому |Z|<2n-1. Для того, чтобы частное размещалось в формате двойного слова необходимо |X’|-|Y|<0, где |X’|=|X|-2-(n+1). В противном случае частное не может быть размещено в формате одного слова. Поэтому операция деления невыполнима. Для поверки этого условия выполним пробное вычитание. Для этого выравнивают делимое и делитель так, чтобы младший разряд делителя был под (n-1)-м разрядом делимого.если вычитание даст отрицательный результат, то операция продолжается. По сути дела мы реализовали традиционное деление «в столбик».Т.о. для выполнения операции деления необходимо либо сдвигать вправо делитель по разрядной сетке, начиная со старших разрядов в процессе получения частичных разностей. При этом делимое остается неподвижным. Либо можно сдвигать влево значение делимого при неподвижном делителе. В процессе получения частичных разностей очередная цифра частного определяется знаком текущего значения частичных разностей. Исходя из этого может быть построено 2 варианта АЛУ.(СХЕМА)
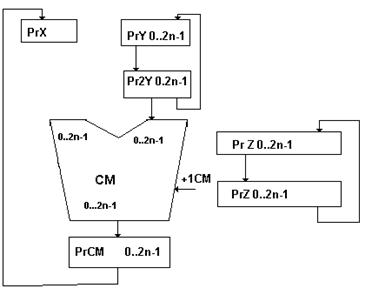 Данная схема предполагает использование двойной разрядности всех элементов. При этом делимое и послед. значение частичных разностей неподвижны, а сдвигаются вправо компоненты делителя. Начальное положение делителя старшие разряды регистра РгУ, а затем делитель à из результате каждой итерации. Частичные разности получаются с помощью сумматора, на один вход которого подается делимое, а на другой-обратный код делителя. Доп. код получается подсуммированием 1 к младшему разряду сумматора. Цифры частного формируют по знаку полученных частичных разностей, т.е. по нулевому разряду сумматора. Цифры заносятся в младший разряд регистра РгZ, которые передаются со сдвигом влево в регистр Z’, а далее прямо в регистр Z. Основным недостатком этой схемы является использование двойной разрядности всех компонентов. На практике получила распространение схема с неподвижным делителем и сдвигаемым влево значением частичных разностей.(СХЕМА)В Рг1 размещается делитель, а в РгВ и Рг2-делимое. В триггерах знака сохраняются знаки операндов. Регистр 3 используется для размещения цифр частного. Общая схема алгоритма:
Данная схема предполагает использование двойной разрядности всех элементов. При этом делимое и послед. значение частичных разностей неподвижны, а сдвигаются вправо компоненты делителя. Начальное положение делителя старшие разряды регистра РгУ, а затем делитель à из результате каждой итерации. Частичные разности получаются с помощью сумматора, на один вход которого подается делимое, а на другой-обратный код делителя. Доп. код получается подсуммированием 1 к младшему разряду сумматора. Цифры частного формируют по знаку полученных частичных разностей, т.е. по нулевому разряду сумматора. Цифры заносятся в младший разряд регистра РгZ, которые передаются со сдвигом влево в регистр Z’, а далее прямо в регистр Z. Основным недостатком этой схемы является использование двойной разрядности всех компонентов. На практике получила распространение схема с неподвижным делителем и сдвигаемым влево значением частичных разностей.(СХЕМА)В Рг1 размещается делитель, а в РгВ и Рг2-делимое. В триггерах знака сохраняются знаки операндов. Регистр 3 используется для размещения цифр частного. Общая схема алгоритма:
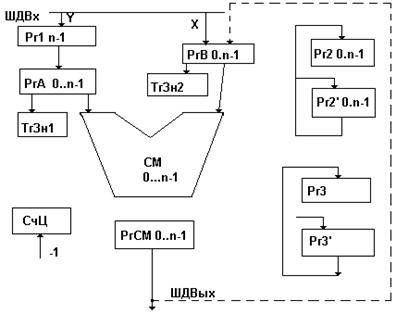 1.Берутся модули от операндов, которые размещаются в регистрах.
1.Берутся модули от операндов, которые размещаются в регистрах.
2.Делимое ß на 1 разряд, для этого регистр А обнуляется и содержимое передается в регистр сумматора со сдвигом ß на один разряд.В освободившийся младший разряд сумматора записывается младший разряд из регистра 2. После этого содержимое регистра сумматора записывается в регистр В. одновременно разряды регистра 2, кроме старшего, передаются в Рг2’ со сдвигом ß на 1 разряд и затем в регистр 2.
3.выполняется получение значения частичных разностей путем сложения содержимого регистра В и обратного кода делителя из регистра А. Выполняется добавление 1 к младшему разряду сумматора для получения дополнительного кода делителя.
4.Если 0-й разряд регистра сумматора>0, то цифра Zi, заносимая в младший разряд регистра 3’=1. Содержимое регистра 3’ передается в регистр 3. При очередном получении частичных (текущих?)разностей содержимое регистра 3 передается в 3’ со сдвигом ß на 1 разряд.
Счетчик циклов содержит количество цифровых разрядов частного. После получения очередной цифры частного значение счетчика уменьшается на 1. При достижении 0 операция заканчивается. Если в процессе получения частичных разностей текущее значение в регистре сумматора <0, то в качестве цифры Zi заносится 0, а предыдущее значение частичных разностей восстанавливается(оно хранилось в регистре В) и сдвигается ß на 1 разряд; с занесением из регистра 2 очередной цифры делимого в младший разряд регистра сумматора при обнулении регистра А. Затем производится передача полученного значения текущей разности в регистр В.
В регистре В производится сдвиг ß оставшейся части делимого для последующих операций.
Рассмотренный алгоритм предполагает при получении значения <0 частичного остатка его восстановление до предыдущего значения. Это требует дополнительного промежутка времени. Поэтому на практике используется алгоритм деления без восстановления остатка со сдвигаемым значением частичной разности и неподвижным делителем. Алгоритм:
1.Берутся модули от делимого и делителя.
2.Значение частичного остатка полагается равным старшим разрядам делимого
3.Значение частичного остатка удваивается путем сдвига ß на 1 разряд.
4.Из значения частичных остатков вычитается делитель; если частичный остаток >0!!!! то прибавляется делитель если <0!!!!
5.Цифра частного полагается =1, если после выполнения предыдущего шага частичные остатки >=0 и 0 в противном случае.
6.Пункты 3,4,5 выполняются до получения всех цифр частного.
7.Если в конце цикла частичный остаток <0 то он восстанавливается путем добавления делителя.
Знак частного =0, если знаки делимого и делителя совпадают, и 1 если они различны.
Содержание деления без восстановления остатков заключается в том, что при сдвиге ß значение частичного остатка а удваивается 2а,поэтому вычитание делителя эквивалентно 2а-в=2(а-в)+в его добавлению на следующем шаге.
Данный алгоритм может применяться и для деления целых операндов, представленных прямым кодом для положительных чисел и дополнительным кодом для отрицательных. При этом необходимо производить определение цифр частного в зависимости от соотношений знаков частичных остатков и делителя в соответствии со следующей таблицей:
| Частичные остатки | Делитель | Операция | Цифра частного |
| + | + | Вычитание Y | |
| + | - | Добавление Y | |
| - | + | Добавление Y | |
| - | - | Вычитание Y |
Если x>0,a y<0 то частное следует увеличить на 1
Если x<0,a y>0 то частное следует увеличить на 1 в случае если остаток!=0
Если x<0,a y<0 то частное следует увеличить на 1если остаток=0.
Правила умножения:
X=±qx*SPx
Y=±qy*SPy
Z=X*Y= ± qx* qy* SPx+Py = ± qz *SPz
T.o. qz= qx* qy; Pz= Px+ Py;
В соответствии с данными выражениями мантисса произведения равна произведению мантисс сомножителей.
Результат нормализуется. Знаку результата соответствует:
+ если мантиссы сомножителей имеют одинаковые знаки;
- если мантиссы сомножителей имеют разные знаки.
Учитывая то, что порядки сомножителей имеют смещение, то при прямом копировании приведенных действий порядок результата должен быть уменьшен на 1 смещения. Поэтому, если при сложении смещённых порядков старшие разряды суммы имеют нулевые значения, то это означает, что мы не можем извлечь смещение, т.к. значение 00 меньше чем извлекаемое смещение. Поэтому в качестве результата операции принимается 0 т.к. мантисса не может быть размещена в разрядной сетке при таком значении порядка.
1) Р[0]=0; P[1]=0 в качестве результата операции принимается 0
2) Р[0]=0; P[1]=1
Тогда производится коррекция, путём инвертирования этого разряда, т.о. получаем требуемый смещённый порядок.
3) Р[0]=1; P[1]=0
Мы получили отрицательное значение суммы смещённых порядков и смещённый порядок суммы получается путём инвертирования.
4) Р[0]=1; P[1]=1
Мы получили отрицательное значение суммы смещённых порядков, разрядная сетка переполняется, но переполнение может исчезнуть при выполнении нормализации мантисс. Эта ситуация отражается в специальном триггере, который характеризует ситуацию возможного переполнения порядков.
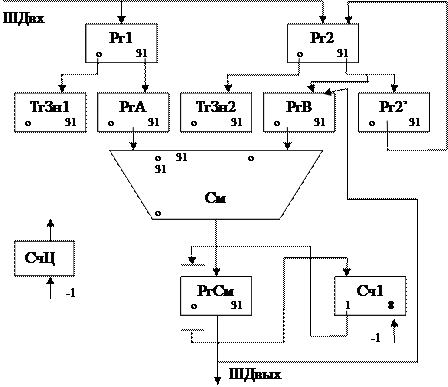
В Рг1 размещается множимое, в Рг2-множитель. В начале для сложения смещённых порядков в РгА и РгВ передаются только биты смещённых порядков. Биты мантисс в РгА и РгВ обнуляются. Соответственно обнуляются и регистры знаков. Сами знаки пишутся в ТрЗн. После размещения порядков в РгА и РгВ сумматор формирует код суммы смещённых порядков. Он размещается в соответствующем поле РгСм.
Производится анализ двух старших разрядов в этом поле в соответствии с приведенными выше рассуждениями. В результате формируется смещённый порядок произведения с необходимыми корректировками кода, который помещается в Сч1.
После этого идёт произведение мантисс. Для этого:
В РгА идёт код мантиссы Х(8-31 разр.). РгВ используется для хранения текущего значения суммы частичных произведений. Идёт анализ младших разрядов мантиссы Y в Рг2 и добавление или не добавление к текущему значению суммы частичных произведений мантиссы Х.
Результат в виде суммы частичных произведений передаётся в РгСм со сдвигом вправо и последующей передачей в РгВ.
Процесс идёт до получения требуемого количества разрядов произведения мантисс.
Отличие данного умножения мантисс от умножения мантисс целых чисел в том, что мантисса произведения имеет тот же размер, что и мантиссы сомножителей. После окончания умножения мантисс результат нормализуется (возможно изменяется значение Сч1). Результат Сч1 идёт в поле для смещённого порядка.
ОПЕРАЦИЯ ДЕЛЕНИЯ ЧИСЕЛ С ПЛАВАЮЩЕЙ ТОЧКОЙ
X = 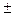 qx*SPx
qx*SPx
Y = qy*SPy
Z = X/Y = (qx*SPx)/(qy*SPy) = (qx/qy)*SPx – Py = qz*SPz
В соответствии с этим выражением мантисса частного = рез-ту деления мантисс порядков, а порядок частного = разности порядков операндов. Знак определяется как «+», если знаки мантисс совпадают и «-» в противном случае.
Операция деления производится аналогично операции умножения в таком порядке:
1. Вычисляется разность порядков
2. Анализируются старшие разряды разности порядков
3. Формируется порядок частного в виде смещённого кода
4. Вычис-ся частное от деления мантисс
5. Рез-т нормализируется.
При анализе разности смещённых порядков исходн. смещение исчезает, поэтому разность порядков должна быть смещена путём добавления 1 к старш. разряду. Поэтому если разность смещ. порядков в старш. разрядах Р[0] и P[1] имеет значение:
1) 00 – то мы превращаем в смещ. порядок путем инвертирования старш.
____
разряда Р[0] = P[1]
2) 01 – то добавление 1 соотв. невозможности разместить порядок в выдел. разрядной сетки. Эта ситуация вызывает штатн. ситуацию переполнения порядка и соотв. прерывание. Эта ситуация может измениться, если мантисса частного в рез-те нормализации будет сдвигаться влево и уменьшится значение порядка.
3) 10 – то имеем отриц. разность порядков и ситуация соотв. отрицат. переполнению порядка.
4) 11 – мы получим отриц. порядок, кот. перевод-ся в смещенный инвертированием 0-го и 1-го разрядов
____ ____
Р[0] = P[0] Р[1] = P[1]
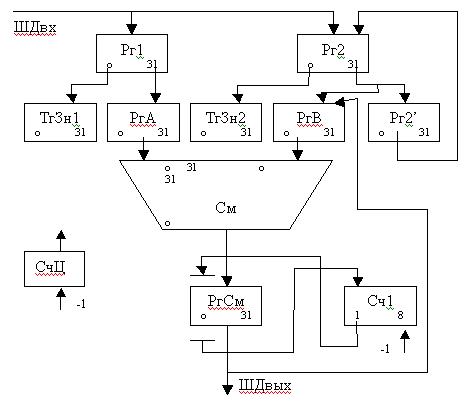
Для выполнения указ. операций может быть использована схема умножения, при этом в Рг1 размещается делитель, в Рг2 – делимое. Аналогично для вычитания порядков: порядок делителя передаётся в РгА в обр. коде, а к 7-му разряду сумматора прибавл. 1.
В РгВ – разряды 1-7 передаётся порядок делимого. Разность порядков размещается в РгСм и подвг-ся анализу, в рез-те которого форм-ся смещ. порядок частного, кот. размещается в Сч1. Выполняется деление мантисс с получ. частного разности. В кач-ве начального значения берется мантисса делимого, из кот. вычитается путем добавления дополнит. кода мантисса делителя. Для этого к младшему разряду делителя добавл. 1. Рез-т сложения кодов передаётся со смещ. влево в РгСм, затем рез-т получения част. разностей размещается в РгВ и процесс продолжается с отличит. особенностью в том, что все операнды и рез-т имеют одинаковую разрядность.
После завершения получения мантиссы, она может подвергаться нормализации (при необходимости) с соотв. изменением смещ-ия порядка. Смещ. порядок размещается в поле РгСм и рез-т из РгСм становится доступным на ШДвых.
Управляющие устройства (УУ)
Операционные устройства позволяют выполнить преобразование некоторых кодов в соответствии с логикой выполняемой операции. При этом операционное устройство может быть представлено множеством микроопераций, которые могут бать выполнены последовательно или параллельно при инициировании определённых составляющих узлов с помощью выделенных сигналов управления. Например, сложение/вычитание двоичных кодов выполняется следующей последовательностью сигналов:
 Т.о. возникает необходимость в использовании спец. устройства (устройство управления), которое предназначено для формирования распределённой во времени последовательности управляющих сигналов, подаваемых на компоненты операционного блока вместе с сигналом синхронизации и обеспечивающие выполнение заданной операции.
Т.о. возникает необходимость в использовании спец. устройства (устройство управления), которое предназначено для формирования распределённой во времени последовательности управляющих сигналов, подаваемых на компоненты операционного блока вместе с сигналом синхронизации и обеспечивающие выполнение заданной операции.
Существуют 2 принципиально разных подхода к УУ: 1)УУ с жесткой логикой; 2) УУ с микропрограммной логикой или МПУУ
УУ с жесткой логикой строятся на основе жестко заданных связей между его компонентами, реализующих формирование и передачу сигналов управления в требуемой последовательности, учитывая состояние УУ, выполняемую операцию и значения т.н. «осведомительных сигналов», характеризующих результаты выполнения предыдущей операции, а также состояния требуемых компонент операционного устройства.
УУ с жесткой логикой не поддаются модификации и при необходимости изменений должны быть полностью заменены.
Основное их достоинство – высокая производительность, связанная с формированием управляющих сигналов с помощью комбинационных схем.
МПУУ – требуемый набор управляющих сигналов сохраняется в т.н. «микропрограммной памяти» с доступом только для чтения (read-only).
Каждый набор таких сигналов соответствует некоторой микрооперации и представлен в виде микрокоманд.
В соответствии с логикой выполнения операции каждая микрокоманда в микропрограмме определяет (содержит) адрес следующей микрокоманды, необходимой для выполнения операции.
МПУУ функционируют с использованием доступа к МП-памяти, поэтому их применение стало оправданным лишь с появлением быстрых модулей памяти.
Основное достоинство МПУУ – возможность модернизации процессора или замены множества выполняемых операций путём перехода к новым модулям МП-памяти.
Т.к. МП-память входит в состав процессора в виде компонента УУ, то данное преимущество даёт возможность автоматизированного и автоматического проектирования компонент УУ и микропроцессора в целом.
Для выработки управляющих сигналов используются следующие обозначения:
- каждый управляющий сигнал соответствует некоторой операции, реализуемой операционным блоком. Пусть V1…Vm – совокупность управляющих сигналов, причём Vi инициирует выполнение соответствующей микрооперации.
- При выработке управляющих сигналов используются U1…Un – значения «осведомительных сигналов» о результатах выполнения предыдущей операции, а также о состоянии компонент операционного устройства.
- УУ может находиться в одном из состояний множества Q={Q1,Q2,…,QL}
- Множество выполняемых операций y1…ys
УУ можно представить некоторым конечным автоматом, соответствующим логике автомата Мура или автомата Мили.
Переход в новое состояние для автомата Мура определяется некоей функцией А от текущего состояний, выполняемой операции и значения.
Q(t+1)=A(Q(t),yi,u1…un) вых. сигналы: V1=F1(Q(t),yi), V2=F2(Q(t),yi), …Vm=Fm(Q(t),yi)
Т.о. значения управляющих сигналов при построении УУ как автомата Мура, зависят только от состояния УУ.
При построении УУ как автомата Мили, выработка управляющих сигналов зависит также от значений «осведомительных сигналов»
V1=f1(Q(t),yi,u1…un), V2=f2(Q(t),yi,u1…un), …Vm=fm(Q(t),yi,u1…un)
Построение автомата Мура требует большего использования компонент для отражения состояния автомата (памяти).
Построение автомата Мили снижает количество элементов памяти для отражения его состояния и требует больше сложных преобразований всех входящих аргументов, поэтому применяют оба подхода.
Каждая микрооперация имеет определенную длительность. Для использования min количества тактовых импульсов синхросигнала все микрооперации «выравнивают» по самой долгой. Любая микрооперация может быть инициирована только на границе тактов. Т.о. последовательность микроопераций реализуется последовательностью управляющих сигналов, подаваемых в начале каждого такта сигналов синхронизации.
Не смотря на то, что идея МПУУ была известна с 1951г. как подход к построению УУ с упорядочением формирования управляющих сигналов.
 УУ состоит из памяти (матрица С), содержащей 2S различных микрокоманд, где S – код, адрес соотв-щей микрокоманды. Если по каким-либо правилам задать адрес первой микрокоманды, выполняющей заданную операцию и разместить её в РгАдреса МикроКоманды, а затем подать на дешифратор с сигналами синхронизации, то на выходе ДШ будет активизирована одна выходная горизонтальная линия, соответствующая выполняемой микрооперации. В таком случае на вертикальных шинах матрицы С, которые связаны с соответствующей горизонтальной линией, появятся сигналы управления.
УУ состоит из памяти (матрица С), содержащей 2S различных микрокоманд, где S – код, адрес соотв-щей микрокоманды. Если по каким-либо правилам задать адрес первой микрокоманды, выполняющей заданную операцию и разместить её в РгАдреса МикроКоманды, а затем подать на дешифратор с сигналами синхронизации, то на выходе ДШ будет активизирована одна выходная горизонтальная линия, соответствующая выполняемой микрооперации. В таком случае на вертикальных шинах матрицы С, которые связаны с соответствующей горизонтальной линией, появятся сигналы управления.
Матрица С связана с Т, которая аналогичным образом позволяет формировать адрес следующей микрокоманды. Использование специального триггера условий позволяет учесть значения «осведомительных сигналов» и выполнить разветвление в микропрограмме путём перехода к другой горизонтальной линии, которая задаёт другой адрес следующей микрокоманды. Задержка сигналов нужна, чтобы формировать новые управляющие сигналы после выполнения текущей микрокоманды.
Последовательность микрокоманд должна получить естественное завершение. Практическая реализация МПУУ связана с использованием различных форматов микрокоманд и различных модулей МП-памяти.
МП-управление с одной стороны позволяет адаптировать систему команд к потребностям выполнения алгоритмов программ. С другой стороны позволяет упростить и автоматизировать процессы проектирования УУ и микропроцессоров в целом.
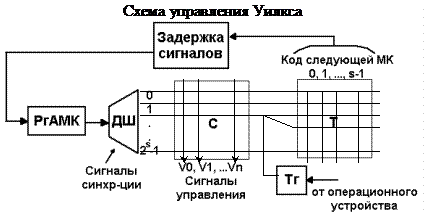
 Состав: УФАМК – устройство формирования адреса микрокоманды; РгАМК – регистр адреса микрокоманды; ПМК – память микрокоманды; РгМК – регистр микрокоманды; ДШМК – дешифратор микрокоманд (дешифратор микрооперации); КОП - код операции.
Состав: УФАМК – устройство формирования адреса микрокоманды; РгАМК – регистр адреса микрокоманды; ПМК – память микрокоманды; РгМК – регистр микрокоманды; ДШМК – дешифратор микрокоманд (дешифратор микрооперации); КОП - код операции.
Начальный источник операции – регистр команд, из которого используется код операции микрокоманды. На основании этого кода УФАМК формирует первой микрокоманды в составе МП-программы, обеспечивающей выполнение данной команды.
Один из вариантов формата микрокоманды следующий: код МО из РгМК попадает в ДшМК, который используется для образования управляющих сигналов.
| код МО | адрес след. МК |
Управляющие сигналы идут на операционное устройство и совместно с сигналами синхронизации обеспечивают (синхронизируют) выполнение одной или нескольких микроопераций в составе операционного устройства (АЛУ).
Адресная часть микрокоманды идет в УФАМК для выбора следующей микрокоманды. На выбор следующей микрокоманды влияют результаты выполнения предыдущей микрооперации, поступающей из операционного блока. Процесс идет до выполнения всех операций в составе команды.
Для кодирования микрокоманд используется несколько форматов:
1. Горизонтальное кодирование: поле команды, соответствующее коду микрооперации представлялось в виде V1|V2|…|Vn|Адрес. Каждый разряд поля соответствует одному функциональному сигналу УУ, соответствующему некоторой микрооперации операционного устройства. Если в этом поле - «1» то это значит, что соответствующая микрооперация будет инициализирована независимо от содержания других рядов этого поля. В таком случае каждой микрокоманде единичные разряды поля микрооперации обеспечивают выполнение соответствующих функций операционного устройства.
Недостаток - длина микрокоманды, учитывая, что количество микроопераций может составлять несколько сот. С другой стороны, учитывая, что многие микрокоманды несовместимы, соответствующее поле микрокоманды будет состоять практически из нулей.
2. Вертикальное кодирование. В поле микрооперации находится код микрооперации, который для дальнейшего использования требует дешифратора. Недостаток – «длинный» микропрограммы, т.к. в каждом такте сигналов синхронизации может быть активизирована только одна микрооперация.
3. На практике распространено смешанное кодирование в 2-х вариантах: вертикально-горизонтальное и горизонтально-вертикальное.
Ветртикално-горизонтальное: всё множество операций V разбивается на k подмножеств Vi. Каждое подмножество размещается в составе поля микрооперации, занимая фиксированный размер в составе поля.
Такие микрокоманды называют микрокоманды с полевой структурой. Каждое такое выделенной поле управляет некоторым подмножеством микроопераций, задавая код данной микрооперации. В результате требуется k дешифраторов.
Данный подход позволяет объединять в одном такте выполнение k микроопераций.
Горизонтально-вертикальное содержит поле микрооперации из двух частей:
V1|V2|…|Vk| l
Первая область содержит некоторые управляющие сигналы, содержание и значение которых зависит от кода во второй области.
Если нужно совместить в одном такте сигналов синхронизации принципиально несовместимые микрооперации, то используют т.н. многофазные микрокоманды, в которых период сигналов синхронизации делится на фазы, в течении которых выполняются определённые компоненты микрокоманды.
Все форматы микрокоманд обеспечивают одни цели: увеличение производительности, уменьшение времени выполнения, уменьшение требуемых объемов памяти для хранения микрокоманд.
Если микропроцессор предназначен для выполнения строго очерченного множества операций с максимально высокой производительностью, то УУ строится как автомат с жесткой логикой.
УСТРОЙСТВА УПРАВЛЕНИЯ С ЖЕСТКОЙ ЛОГИКОЙ
Устр. упр. с ж. л. предст. координационными схемами, кот. обеспечивают построение распределен. во времени последовательности сигналов упр., в зависимости от кода операции и № такта сигн. синхронизации. При этом учитыв. значение осведомительного сигнала от операционного усройства.
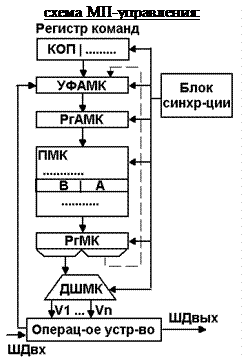
 По ходу операции из Рг команд, дешифратор кода активирует 1 выходную линию, соотв. выполняемой команде. Счетчик тактов запускается с мом. выполнения тек. команды. Дешифратор нового такта активизирует 1 вых. линию, соотв. № такта. В результате устр. обр. упр. сигналов, в зависимости от № такта и вып. команды, с помощью логических схем «и/или», формирует требуемую последовательность управляющих сигналов, инициализирующих выполняемые последовательности МО в операционных устройствах.
По ходу операции из Рг команд, дешифратор кода активирует 1 выходную линию, соотв. выполняемой команде. Счетчик тактов запускается с мом. выполнения тек. команды. Дешифратор нового такта активизирует 1 вых. линию, соотв. № такта. В результате устр. обр. упр. сигналов, в зависимости от № такта и вып. команды, с помощью логических схем «и/или», формирует требуемую последовательность управляющих сигналов, инициализирующих выполняемые последовательности МО в операционных устройствах.
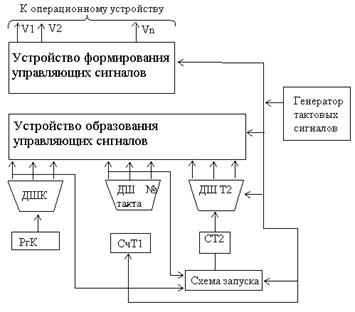 Недостаток данной схемы (1) – ориентация на выполнение команд, требующих одинакового количества тактов, поэтому для ее исп. необх. «выровнять» все команды по команде, треб. max числа тактов.
Недостаток данной схемы (1) – ориентация на выполнение команд, требующих одинакового количества тактов, поэтому для ее исп. необх. «выровнять» все команды по команде, треб. max числа тактов.
 Команды, треб. min количества тактов – однобайтные команды, или команды с min количеством бит (команды обр. регистров, изм. режимов, команды установки и т.д.). В отличие от них, длинные команды исп. смешанную адрессацию (регистровую и непосредственную, косвенную). Поэтому выравнивание команд приводит к неэф-му исп. памяти. Для повышения эф-ти устр. упр. с ж. л. исп. счетчики тактов, обеспечивающие выполнение требуемого типа команд.
Команды, треб. min количества тактов – однобайтные команды, или команды с min количеством бит (команды обр. регистров, изм. режимов, команды установки и т.д.). В отличие от них, длинные команды исп. смешанную адрессацию (регистровую и непосредственную, косвенную). Поэтому выравнивание команд приводит к неэф-му исп. памяти. Для повышения эф-ти устр. упр. с ж. л. исп. счетчики тактов, обеспечивающие выполнение требуемого типа команд.
В кач. примера рассм. устр. упр., обеспечивающее выполнение, или поддержку коротких и длинных команд(2).
В зав-ти от типа команды по длине, схема упр. предост. возможность активизировать или только счетчик тактов 1, или на опр. такте запускать счетчик тактов 2, реализуя вып. команд, треб. большего кол-ва тактов. Очевидно, схема м.б. дополнена н????????
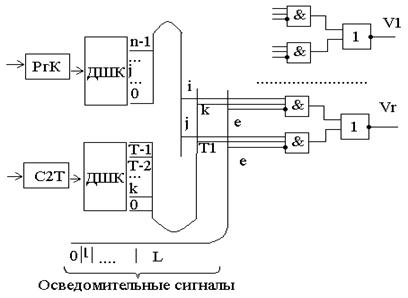
Рассмотрим, каким обр. можно обесп. образование сигналов упр (3). Для этих целей исп. комбинации логических эл-ов «и/или», кот. в зависимости от типа команды (код команды), № такта и знач. осведомительных сигналов, формируют необходимые сигналы упр.
На примере форм-я сигнала упр. ВР можно говорить, что этот сигнал генерируется при вып. j-й команды во всех тактах, кроме к-го при наличии освидомит. сигнала L. Для построения устр. упр. с ж. л. используется объединение микропрограмм, включая все выполняемые микропрограммы, кажд. из кот. соотв. некоторому коду команды. Микропр-ма предст. собой последовательность, а также разветвление выполнения отдельных микропрограмм, в зависимости от кода вып. команды и знач. осведомит. сигналов. Объедененная микропрограмма м.б. построена по след. схеме:
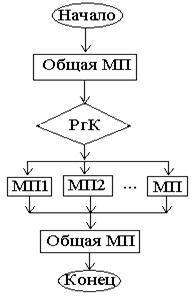 Для искл. микроопер., вход. во все микропр-ы, их общие части, связ. с начальной инициализацией, а также корректным завершением выполнения, выделяются в общие части микрокоманды. Исключенные части каждой микропер., инициализируются в зав. от кода выполняемой микропрограммы.
Для искл. микроопер., вход. во все микропр-ы, их общие части, связ. с начальной инициализацией, а также корректным завершением выполнения, выделяются в общие части микрокоманды. Исключенные части каждой микропер., инициализируются в зав. от кода выполняемой микропрограммы.
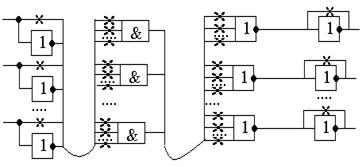 Для исп. понятий автоматов при постр. устр. упр. необходимо выделить состояния устр. упр., а также усл. перехода из 1 сост. в др. Для автомата Мура, в кач. состояний исп. события генерации (возникновение соотв. сигналов упр.). Некоторые сост. могут порождать в т. сл. формирование нескольких сигналов упр. После этого усл. перехода из сост. в сост. будут иметь значения соотв. осведомит. сигналов. В т. сл. для хранения инф. о тек. сост. автомата упр. можно исп. набор триггеров, кол-во кот. k=ln r, r – кол-во состояний. Иными словами мыпронумеруем все сост. и сопоставим всем сост. некоторый 2-й код, соотв. данному сост. Зная порождаемые сигналы упр. каждым сост., можно, исп. логическую схему «или» и дешифратор состояния, обеспечить формир-е требуемых сигналов упр.Автомат Мили требует меньшего кол-ва триггеров для отобр. состояний, т.к. описывается меньшим кол-ом состояний, но его недостаток – изменение состояния происходит при изм. освед. сигн., что может повлеч изм. упр. сигн., кот. будут преждевременными для текущей выполняемой команды. Поэтому аппарат Мили применяют со схемами задержки, либо в комбинации: Мура – Мили. Для построения устр. упр. с ж. л. исп. программируемые логические матрицы:
Для исп. понятий автоматов при постр. устр. упр. необходимо выделить состояния устр. упр., а также усл. перехода из 1 сост. в др. Для автомата Мура, в кач. состояний исп. события генерации (возникновение соотв. сигналов упр.). Некоторые сост. могут порождать в т. сл. формирование нескольких сигналов упр. После этого усл. перехода из сост. в сост. будут иметь значения соотв. осведомит. сигналов. В т. сл. для хранения инф. о тек. сост. автомата упр. можно исп. набор триггеров, кол-во кот. k=ln r, r – кол-во состояний. Иными словами мыпронумеруем все сост. и сопоставим всем сост. некоторый 2-й код, соотв. данному сост. Зная порождаемые сигналы упр. каждым сост., можно, исп. логическую схему «или» и дешифратор состояния, обеспечить формир-е требуемых сигналов упр.Автомат Мили требует меньшего кол-ва триггеров для отобр. состояний, т.к. описывается меньшим кол-ом состояний, но его недостаток – изменение состояния происходит при изм. освед. сигн., что может повлеч изм. упр. сигн., кот. будут преждевременными для текущей выполняемой команды. Поэтому аппарат Мили применяют со схемами задержки, либо в комбинации: Мура – Мили. Для построения устр. упр. с ж. л. исп. программируемые логические матрицы:
Матрица сод. Слой входных инверторов, слой эл-ов «и», слой эл-ов «или» и слой вых. инверторов. Крестики – возможность разорвать соотв. цепь в процессе программирования матрицы. Матрица образована т.о., что на любой эл-т «и» м.б. поданы все знач. прямых и инвертных входных сигн. На вход любого эл-та «или» м.б. поданы выходы любого эл-та «и».
МП называется программное устройство обработки данных, выполняемое средствами микроэлектронных технологий в корпусе одной или нескольких больших интегральных схем.
Общая структура МП может быть представлена:
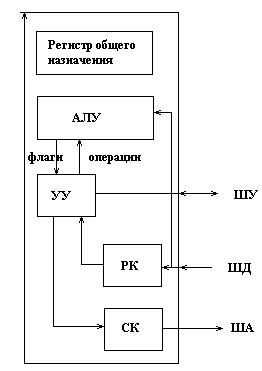 В состав МП входит:
В состав МП входит:
– операционное устройство в виде АЛУ и регистра общего назначения;
– устройство управления (УУ), включающие регистры общего назначения;
– регистр команд (РГ);
– счетчик команд (СК);
СК хранит адрес команды, которую подлежит выполнению. По этому адресу из оперативной памяти извлекается соответствующая команда, занимающая от 1 до нескольких байт и код команды, размещающийся в 1 байте, записывается в РК. В соответствии с кодом команды устройство управления обеспечивает выполнение либо 1 микрооперации, либо микропрограммы, включающей совокупность микроопераций.
В регистре общего назначения размещаются операнды выполняемой операции и промежуточные операции вычисления. Результат выполнения команды может быть размещен либо в регистре общего назначения либо записывается в памяти по сформированному адресу.
В процессе выполнения команды могут быть обращения к памяти за операндами. Архитектура МП определяет множество выполняемых команд, разрядные шины адреса, шины данных, составные шины управления, составных регистров общего и специального назначения, наличием промежуточной буферной памяти. Это КЭШ-память для размещения команд выполнения команды и блоков данных. Возможна модернизация системы команд количеством одновременной обработки бит в операционном устройстве, количеством самих операционных устройств.
Особенности архитектуры 8-разрядных МП.
Под разрядностью МП понимают количество двоичных разрядов, обрабатываемых операционным устройством МП. Типичным представителем 8-разрядного МП есть Intel 8080, КР 580. МП имеет 8-разрядную шину данных и 8-разрядное операционное устройство, 16-разрядную шину адреса. МП, выполненный на основе n-МОП технологий. Питание имеют уровни 12В, ±5В.
Общая структура МП имеет следующий вид:
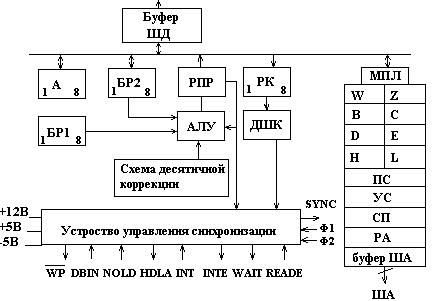 Операционное устройство представлено: АЛУ, схемой десятичной коррекции, регистр общего назначения А (аккумулятор), в котором размещается 1 из операндов и после выполнения операции результат выполнения:
Операционное устройство представлено: АЛУ, схемой десятичной коррекции, регистр общего назначения А (аккумулятор), в котором размещается 1 из операндов и после выполнения операции результат выполнения:
2 буферных регистра БР1 и БР2. Помимо этого в составе регистра общего назначения имеются 8-разрядные регистры B-L, доступ к которым происходит через мультиплексор МПП. Регистры W и Z программно не доступны. Регистры B-L могут использоваться парами как 16-разрядные.
ПС – программный счетчик, хранящий адрес текущей выполняемой команды, а после ее выборки из памяти увеличивается в соответствии с длиной выполняемой команды в байтах.
УС – указатель стека. Хранит адрес верхушки стека, который размещается в оперативной памяти.
СП – схема приращений. Используется для изменения содержимого программного счетчика и содержимого стека.
РА – регистр адреса.
Буфер шины адреса представляет собой устройство, обеспечивающие подключение и отключение внутренней и внешней шины. Построение такого одноразрядного буфера может быть выполнено по следующей схеме:
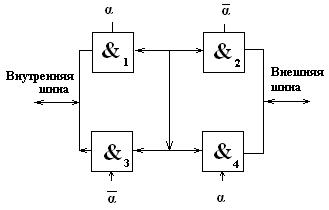 При сигнале управления
При сигнале управления  = 1 будут открыты логические элементы 1 и 4. В результате значение с внутренней шины данных передается на внешнюю. Если = 0, то значения с внешней шины данных будут поступать на внутреннюю.
= 1 будут открыты логические элементы 1 и 4. В результате значение с внутренней шины данных передается на внешнюю. Если = 0, то значения с внешней шины данных будут поступать на внутреннюю.
Устройство управления и синхронизации собрано по схеме с «жесткой» логикой и формирует сигнал управления подаваемый на все элементы МП. Распределение их во времени обеспечивает сигнал синхронизации. Помимо этого устройство формирует сигнал 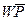 при записи информации в память или на внешнее устройство. При передачи информации в МП по шинам данных формируется сигнал DB.
при записи информации в память или на внешнее устройство. При передачи информации в МП по шинам данных формируется сигнал DB.
HOLD – сигнал захвата. Формируется после окончания выполнения текущей команды до начала выполнения следующей команды.
HDLA – сигнал подтверждения сигнала захвата.
INT – запрос на прерывание. Воспринимается МП после выполнения текущей команды. После этого, содержащаяся программа счетчика и регистра команд записывается в стек. Записанный адрес первой команды обрабатывает прерывание.
INT E – сигнал разрешения прерывания. Может быть установлен программой.
WAIT – сигнал режима ожидания МП, в котором находится МП при подготовке внешних устройств к процессу обмена информации.
READY – сигнал готовности от внешних устройств.
F1 и F2 – сигнал, поступающий от тактового генератора.
Команды МП могут быть 1-, 2-, 3-х байтными. Для извлечения операндов (обработанных данных) используют следующие методы адресации:
- непосредственная адресация. При этом обработка данных размещается непосредственно в теле команды – во 2-м или 2-м и 3-м байтах.
- прямая адресация. Адрес операнда размещается во 2-м и 3-м байтах. Во 2-м размещается младший байт адреса.
- косвенная адресация. В составе 2-го или 2-го и 3-го байтах указывается регистр, содержащий адрес памяти, по которому размещаются обратные операнды.
- регистровая. Применяется в однобайтных командах, в котором используется регистр, определяемый кодом команды.
Все команды делятся на следующие группы:
- команды пересылки;
- арифметические, включающие алгоритмы сложения, вычитания, инкремента, декремента. Умножение и деление выполняемой команды отрицательного числа, представляются дополнительным кодом.
- логические: «и», «или», сдвиговые.
- команды управления и команды вводавывода с внешних устройств.
- команды перехода и вызова подпрограмм условного и безусловного перехода.
|
|
|
|
|
Дата добавления: 2013-12-12; Просмотров: 625; Нарушение авторских прав?; Мы поможем в написании вашей работы!