КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Входные данные. Имена таблиц с учетом разделов
|
|
|
|
Управление разделением
Имена таблиц с учетом разделов
Разделенные индексы
Размещение строк в разделах данных
Разделенные таблицы
Разделение данных
Установки по умолчанию для табличных областей
Установки по умолчанию для пользователей
Установки по умолчанию для хранения объектов
В большинстве случаев параметры хранения объектов не являются обязательными; они позволяют управлять хранением информации каждого объекта. Для параметров хранения всегда существуют установки по умолчанию. Далее показано, как задавать такие установки для объектов хранения данных базы данных Oracle.
Для каждого пользователя можно установить табличную область по умолчанию и временную табличную область. Когда пользователь создает новый объект базы данных и не указывает для него табличную область явно, Oracle сохраняет новый объект в табличной области по умолчанию для этого пользователя; Во временной табличной области пользователя Oracle, по мере необходимости, выделяет временное рабочее пространство для его SQL-операторов.
Если при создании в табличной области таблицы, кластера данных, индекса или моментального снимка не указываются параметры экстентов нового объекта, то для сегмента этого объекта устанавливаются значения, которые были заданы по умолчанию для этой табличной области. Для каждой табличной области можно указать по умолчанию значения:
• Размеров начального и последующих экстентов сегмента
• Минимального и максимального числа экстентов в сегменте
• Коэффициента возрастания последующих экстснтон сегмента.
При создании больших таблиц (или индексов) в производственных системах баз данных могут возникать различные проблемы, порождаемые размерами и характеристиками хранения таких таблиц. Для примера рассмотрп^сдующме ситуации:
• Таблица вырастает настолько, что для работы с ней нужно время, превышающее разрсшенный интервал.
• Для обработки запроса, необходимо выполнить полное сканирование очень большой таблицы. Пока происходит считывание множества блоков данных указанной таблицы, падает проузводительность приложения и системы.
• Одно из ответственных приложений работает в основном с единстненной большой таблнцей. Когда в результате сбоя диска хотя бы один блок данных в этой таблице становится недоступен, запрещается доступ ко всей таблице. Чтобы таблица и приложение могли продолжать функционирование, администратору приходится восстанавливать всю табличную область, в которой находится эта таблица.
Чтобы уменьшить вероятность возникновения проблем такого рода в Огас1е8 поддерживается разделение таблиц и индексов.
В Oracle8 можно разбивать области хранения таблиц на более мелкие единицы дисковой памяти, называемые разделами {partitions).
В каждом разделе таблицы содержатся одни и те же столбцы, имеющие один и те же типы данных и ограничения целостности. Однако каждый раздел таблицы может иметь соостнсняые физические атрибуты. Например, каждый раздел таблицы может храниться в отдельных табличных областях, и для каждого раздела могут быть заданы собственные, отличные от друтих, устанонки хранения информации для экстентов и блоков данных.
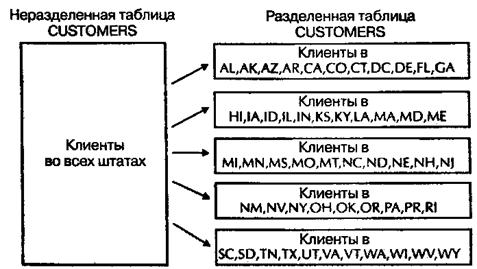
В Oracle8 применяются таблицы, разделенные по диапазонам (range partitioned tables). Значение ключа разделов для какой-либо строки определяет, в каком разделе она хранится. Ключ разделов (partition key) таблицы — это столбец или упорядоченный набор столбцов (до 16), характеризующий физическое разделение строк этой таблицы. Чтобы предотвратить нерациональное расходование ресурсов при переносе строк из раздела в раздел, приложениям никогда не следует обновлять данные, содержащиеся в ключе разделов таблицы.
Можно задать диапазоны данных для разделов некоторой таблицы, указав верхнюю границу для каждого (не входящую в состав данного раздела). В каждом из них (исключая первый) имеется скрытое нижнее значение, которое представляет собой верхнюю границу предшествующего раздела. Таким образом, нужно создавать табличные разделы так, чтобы их диапазоны возрастали по значениям.
Чтобы проиллюстрировать размещение строк в таблицах, разделенных по диапазонам, посмотрим, xто происходит, когда приложение вносит в таблицу запись о клиенте, живущем в штате Арканзас (AR — Arkansas). Oracle сравнивает первый символ кода штата AR со значением, определяющим первый раздел таблицы, P1. А меньше Н, поэтому новая строка помещается в раздел P1, который физически хранится в файле данных табличной области DATA01. Аналогично, когда вводятся данные о новом клиенте из Ныо-Джерси (NJ —New Jersey), запись о новом клиенте размещается в разделе P3 (NJ меньше NM), который физически хранится, в файле данных табличной области DATA03 и т.д.
Для некластеризонанных таблиц в Oracle8 поддерживается разделение индексов по диапазону. Как и в таблицах, каждый раздел индекса имеет те же самые логические атрибуты (столбцы индекса), но может иметь разные физические. характеристики (размещение табличных областей и параметры хранения). Ключ разделов индекса устанавливает, в каком разделе хранятся индексные злементы. Он должен состоять из одного или нескольких столбцов, определяющих этот индекс. Описание диапазонов разделов индекса аналогично описанию разделов таблицы:
В Oracle8 предлагается уникальная синтаксическая конструкция для команд, называемая именами таблиц с учетом разделов, которая, может использоваться разработчиками приложений при создании SQL-операторов, работающих с разделенными таблицами. Имя таблицы с учетом разделов (partition-extended table name) — это простой, но эффективный синтаксис, позволяющий приложениям просматривать как таблицы, так и их разделы. Например, с помощью следующего' запроса из нужного раздела таблицы выбираются все клиенты, проживающие в Калифорнии (СА - California):
SELECT * FROM usa.customers PARTITION (p1);
Хотя такие имена могут повысить производительность некоторых SQL-операторов, разработчикам следует внимательнее подходить к использованию этого синтаксиса в SQL-опсраторах приложений.
Дело в том, что в именах таблиц с учетом разделов указываются характеристики физического хранения табличных данных. Вообще говоря, не стоит использовать в программах приложений SQL-операторы, которые создают взаимосвязи между физическими областями диска и таблицами, — такие взаимосвязи могут привести к прекращению функционирования приложения, если впоследствии физическое место хранения одной из таблиц изменится.
Если имена таблиц с учетом разделов при разработке приложения все же применяются, не забывайте, что такие имена являются расширением ANSI/ISO (языка SQL), вводимым в Oracle. Когда нужно использовать имена таблиц с учетом разделов и'при этом сохранить переносимость приложения, создавайте представления с указанием таких имен и. применяйте, для этих., представлений стандартные SQL-операторы. Например:
CREATE VIEW v1 AS SELECT * FROM t1 PARTITION (pi)
SELECT* FROM v1;
Oracle8 полностью поддерживает работу с разделенными таблицами и индексами. Например:
• Можно преобразовать неразделенную таблицу в разделенную, и наоборот.
• Можно добавить новые разделы таблицы к уже существующим.
• Можно разбивать и объединять разделы, расположенные в середине таблицы.
• Можно удалять разделы таблицы, не содержащие строк.
• Можно укорачивать отдельные разделы таблицы, а не всю таблицу в целом.
Глава 22. Основные компоненты SQL*Loader
Для SQL*Loader необходима входная информация двух типов: внешние данные, которые могут располагаться на диске или ленте, и управляющая информация (содержащаяся в управляющем файле), описывающая входные данные, а также таблицы и столбцы, в которые осуществляется загрузка. Выходные данные включают таблицы Oracle, файл протокола, файл отсеянных и файл отвергнутых записей. От вывода некоторых файлов можно отказаться.
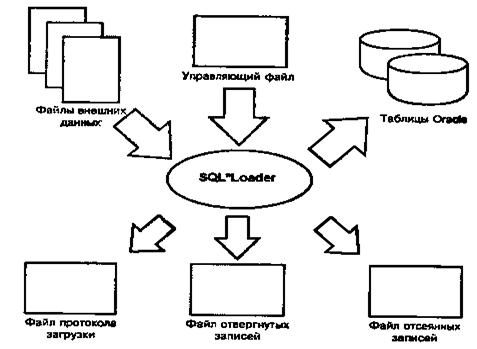
SQL*Loader может обрабатывать практически любые типы файлов данных и поддерживает "родные" типы данных почти всех платформ. Данные обычно читаются из одного или нескольких файлов данных; однако данные также могут быть помещены в управляющий файл после управляющей информации. Файл данных может иметь фиксированный или переменный формат.
В файле фиксированного формата данные находятся в записях фиксированной длины, которые имеют одинаковый формат. Поле данных определено позициями начала и конца поля в записи и содержит данные одного типа и одной длины во всех записях файла. Двоичные данные должны загружаться из файла фиксированного формата, так как SQL*Loader не может воспринимать их в переменном формате.
В файлах переменного формата данные находятся в записях, длина которых определяется суммой длин данных в полях. Поле имеет ровно такую длину, какая необходима для размещения данных. Поля в файлах переменного формата могут отделяться одно от другого символами-разделителями (такими как запятые или пробелы), быть окаймлены символами-ограничителями (такими как кавычки) или разделяются и тем, и другим.
При работе с файлами с символами-разделителями удостоверьтесь, что поля, содержащие символ-разделитель как часть данных, охвачены символами-ограничителями. Например, для файла с разделением запятой можно использовать двойные кавычки, чтобы окаймить ими поле, содержащее запятую.
Для увеличения производительности, используйте записи фиксированной длины. SQL*Loader тратит на обработку файла переменного формата приблизительно на 50 процентов времени больше, по сравнению с файлом фиксированного формата.
С помощью средства поддержки национальных языков (National Language Support — NLS) SQL*Loader может преобразовать данные с различными схемами кодирования символов, других компьютерных платформ и других стран. Например, SQL*Loader может загрузить файл EBCDIC в базу данных на ASCII платформе или файл с азиатским символьным набором — в базу данных с американским символьным набором.
|
|
|
|
Дата добавления: 2013-12-12; Просмотров: 629; Нарушение авторских прав?; Мы поможем в написании вашей работы!