КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Синтезаторы третьего типа используют метод цифрового моделирования голосового тракта человека
|
|
|
|
Аналоговые методы синтеза формантных частот.
Выше было дано определение формантной частоты речевого сигнала. Для удовлетворительного распознавания и синтеза речи достаточно использовать 3 из 6-и старших формант. Тем не менее, использование формантных частот даёт
неестественное звучание речи, что объясняется особенностью источника речи. В устройствах этого типа естественная речь человека не используется, так как синтез речи основан на электронном моделировании голосового тракта человека, поэтому синтезатор «говорит» голосом робота. Кратко процесс синтеза заключается в следующем.
Орфографический текст разбивается на фонемы, которые преобразуются в фонетическое описание текста, затем формируются последовательности управляющих слов, которые используются для управления собственно синтезатором.
Отличительной особенностью этого метода является принципиальная возможность создания синтезатора с неограниченным словарём, так как в основу его положена элементарная частица речи – фонема. Возможность неограниченного словаря никакому другому типу синтезаторов недоступна. Это в значительной степени искупает основной недостаток синтезатора – неестественное звучание речи.
Наиболее распространённая реализация этого метода известна под названием Линейного Предиктивного Кодирования (ЛПК), а синтезаторы называют ЛПК - синтезаторами (термин «предиктивный» означает предсказательный).
ЛПК синтезаторы обладают по сравнению с другими типами синтезаторов преимуществами, связанными с относительной простотой их реализации в виде цифровых микросхем, меньшей стоимостью их производства и меньшей эквивалентной скоростью передачи информации. Словарь в ЛПК - синтезаторе создаётся (как и в синтезаторах первой группы) с участием говорящего человека. Закодированная таким образом человеческая речь на этапе синтеза не подвергается прямому восстановлению. Она обрабатывается специальным цифровым анализатором, и в результате такого анализа образуются так называемые предикторные коэффициенты – параметры, которые используются непосредственно для управления собственно синтезатором. Предикторные коэффициенты представляют собой частотные и голосовые коэффициенты речи. Такой подход позволяет значительно снизить объём необходимой памяти.
3.2 Синтезаторы с непосредственным
кодированием/восстановлением человеческой речи.
Синтезаторы этого типа используют компилятивный метод синтеза. Это означает, что в основу построения синтезатора положен принцип работы по образцам. В качестве образца берётся живая человеческая речь, которая предварительно кодируется, то есть преобразуется в цифровую форму и сохраняется в памяти компьютера.
Принцип кодирования речевого сигнала иллюстрирует рис. 9, а.

На верхнем рисунке приведён фрагмент речевого сигнала А(t). Этот сигнал с помощью устройства, называемого схемой выборки, квантуется с частотой синхроимпульсов (СИ), и на выходе схемы выборки образуются отдельные значения речевого сигнала А*(t). Амплитуда этих сигналов соответствует величине сигнала А(t) в момент выборки, то есть в момент поступления СИ на схему выборки.
Затем, отдельные выборки произнесённого в микрофон слова или фразы преобразуются в код и записываются в память. Массиву байтов, соответствующих слову (фразе), присваивается идентификатор (имя), по которому на этапе синтеза речи можно обратиться к области памяти, где хранится это слово, (фраза). Как видно на рис. 9, а, десяти выборкам речевого сигнала соответствуют 10 байтов, записанных в память компьютера.
На рисунке 9, б приведена простейшая схема выборки, реализованная на базе операционного усилителя (ОУ) с емкостью в цепи отрицательной обратной связи (С). Когда электронный ключ (К) закрыт ёмкость хранит напряжение, равное величине напряжения А(t) в момент закрытия ключа К. На выходе операционного усилителя (ОУ) при этом образуется напряжение -А*(t) равное А(t) (при равенстве резисторов R). С приходом очередного импульса СИ ключ открывается и ёмкость разряжается до напряжения А(t), действующего на входе. С прекращением импульса СИ ключ К закрывается и ёмкость хранит напряжение, поступившее на вход в момент закрытия ключа (с обратным знаком). Работу схемы выборки описывает временная диаграмма, приведённая на рис. 9, а.
Структура синтезатора приведена на рис. 10.
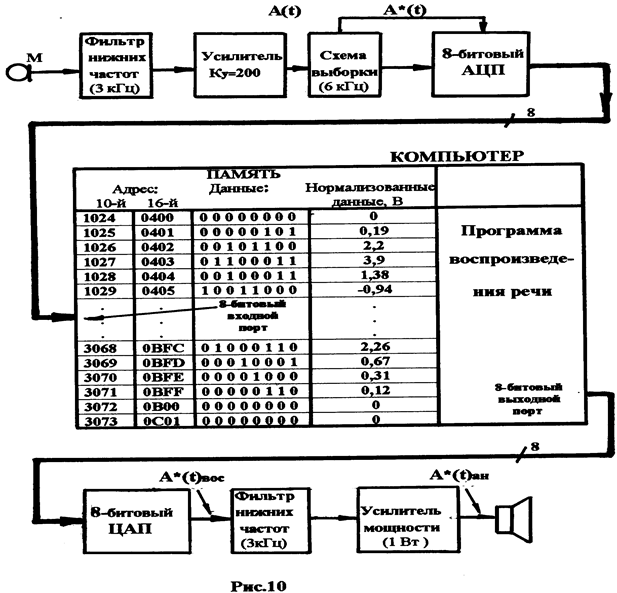
В приведённой структуре можно выделить 3 основных узла:
1. Входной узел синтезатора, состоящий из микрофона (М), фильтра нижних частот (ФНЧ), усилителя (У), схемы выборки и 8-битового АЦП.
2. Компьютер.
3. Выходной узел синтезатора, включающий в себя 8-битный ЦАП, фильтр нижних частот (ФНЧ), усилитель мощности и динамик (Д).
Работа входного узла синтезатора описана выше и не требует особых комментариев. Следует лишь отметить, что фильтр нижних частот, используемый в этом узле, и настроенный на частоту фильтрации сигнала с микрофона (ниже 3 кГц), выполняет задачу подавления высокочастотных помех, приводящих к искажению речевого сигнала А(t). Усилитель (У) доводит амплитуду речевого сигнала до уровня, принятого в синтезаторе.
Схема выборки с частотой 6 кГц производит выборки речевого сигнала A*(t), а аналого-цифровой преобразователь (АЦП) преобразует выборки в цифровые коды (байты). При частоте выборки сигнала 6 кГц среднее количество выборок для слова длительностью 0,3 секунды составляет около 2000 байтов (включая короткие паузы в начале и в конце слова).
Компьютер имеет параллельный 8-битный порт ввода данных с АЦП и параллельный 8-битный порт вывода, откуда данные поступают на вход 8-битного цифро-аналогового преобразователя (ЦАП).
В процессе сбора данных компьютером его резидентная программа переносит информацию из 8-битного АЦП и последовательно записывает её в память.
После произнесения слова процесс выборки заканчивается, а в памяти оказывается записанным цифровое представление слова.
Выходной узел синтезатора представляет воспроизводящую часть синтезатора. Он содержит 8-битный цифро-аналоговый преобразователь, фильтр нижних частот (ФНЧ), который отфильтровывает нежелательные высокочастотные сигналы c выхода ЦАП – A(t)вос, возникающие в восстановленном сигнале. Отфильтрованный сигнал поступает на усилитель мощности, а затем в виде сигнала A*(t)вос на динамик-Д.
Программа воспроизведения речи, хранимая в памяти, – это простая индексирующая программа, которая последовательными шагами просматривает записанную ранее информацию и выводит её побайтно на 8-битный ЦАП.
Речь, которую услышит пользователь по своему звучанию, соответствует голосу говорящего и имеет модуляцию и тональность, как и входной речевой сигнал.
3.3. Аналоговый синтез формантных частот
В отличие от метода «непосредственного кодирования / восстановления речи», описанного ранее, метод синтеза формантных частот не использует человеческую речь в качестве исходного материала. В этом методе используется известное приближение к человеческой речи с использованием формантных частот.
Существует много вариантов реализации формантного синтеза. Но основные функциональные операции для генерации речи при разных способах формантного синтеза в принципе одинаковы. Все они основываются на детальном знании фонем и фонетическом расчленении речи. По этой причине эта группа методов в литературе получила название «формирование речи по правилам».
При синтезе речи по правилам используется электронная модель голосового тракта человека, то есть синтезатор организован, как некоторое приближение к голосовому тракту. При этом настройка синтезатора в этом случае производится отдельно для каждого фонетического элемента алфавита.
Фонетическое описание представляет собой последовательность элементов фонетического алфавита (включая паузы) с указанием длительности звучания каждого из них. Таким образом, каждому элементу фонетического алфавита ставят в соответствие набор параметров настройки синтезатора.
Наборы параметров настройки синтезатора для каждого элемента фонетического алфавита (ФА) в виде управляющих слов (УС) хранятся в памяти (как правило, в ПЗУ). Код элемента ФА используется, таким образом, в качестве адреса и позволяет найти УС или их последовательность. Каждое УС содержит помимо набора параметров настройки синтезатора { pi } параметр длительности звучания фонологического элемента, флаг цепи УС и ряд других флагов.
Для того, чтобы связать фонему с конкретными формантными частотами, которые характерны для некоторых фонем фонетического алфавита английского языка, рассмотрим таблицу 3.1 соответствия фонем формантным частотам:
| Фонема | Как в слове | F1 (Гц) | F2 (Гц) | F3 (Гц) |
| ee | feet | |||
| i | hid | |||
| eh | head | |||
| ае | had | |||
| aw | talk |
Для каждого звука в таблице даны три основные (старшие) формантные частоты.
Они наблюдаются в спектрограммах соответствующих фонем, произносимых «средним» мужским голосом. Эти частоты, F1, F2, F3, можно различать визуально на спектрограммах каждой произносимой гласной. Поскольку каждая из этих гласных является «статической», частоты остаются стабильными на протяжении всего времени их произнесения. Нетрудно представить электронную схему, состоящую из трёх параллельных полосовых фильтров, частоты которых настроены на F1 F2 и F3 и возбуждаются задающим генератором с выходным сигналом, аналогичным импульсу, формируемому голосовым аппаратом. Как ни проста эта схема, она может служить основой для создания фонемного синтезатора гласных при условии, что формантные частоты регулируются в пределах, указанных в таблице 3.1.
Таким образом, необходимо задавать параметры, регулирующие характеристики полосовых фильтров, амплитуды генератора шума для воспроизведения шумных согласных, фрикативных согласных, амплитуды носовых (нозальных) гласных, и т.п.
В формантных синтезаторах используется набор от 8 до 15 параметров. Количество параметров влияет на качество синтезируемой речи.
Наиболее часто используется набор, состоящий из следующих параметров:
· F0 – частота сигналов голосового аппарата (частота основного тона);
· A0 – амплитуда сигналов основного тона;
· F1 - F3 – частота фильтров первой, второй и третьей формант произносимой фонемы;
· FN – частота резонатора носовых гласных;
· AFR – амплитуда фрикативных согласных;
· FR – частота резонатора фрикативных согласных;
· AN – амплитуда носовых гласных;
· AГЛ – амплитуда гласных.
Справка ( примеры согласных звуков ):
Носовые гласные – м, н;
Шумные: взрывные – б, г, д; щелевые – в, з, ж;
Фрикативные: ц, ч;
Глайды: р, л;
Взрывные: п, т, к и т.д.
Один из вариантов (практически полный) модели синтезатора приведён на рис. 11.
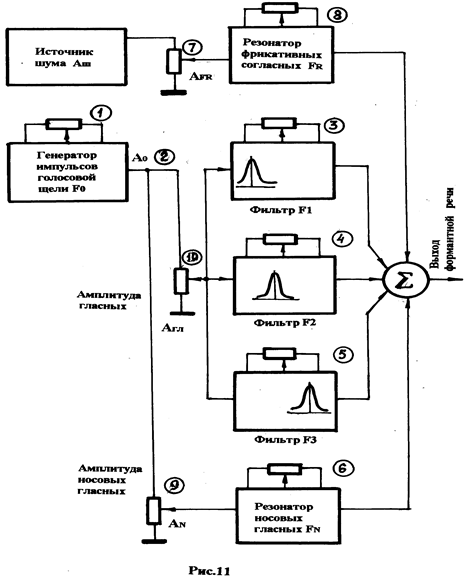
На рисунке с помощью потенциометров, подключённым к отдельным блокам модели, задаются параметры, управляющие синтезом речи. В указанной схеме используются 10 таких параметров. Такую модель несложно реализовать, но практически она будет неработоспособна, так как задание параметров с помощью потенциометров приводит к чрезвычайно большому времени синтеза.
Выходом из сложившейся ситуации является включение в модель вместо потенциометров резистивных матриц, управляемых с помощью цифрового кода, которые имеют приемлемое время установки параметра.
Структура одной из таких резистивных матриц приведена на рис. 12.
Матрица содержит резисторы Ri, которыеподключаются (отключаются) с помощью быстродействующих ключевых схем (ключей) Ki. В свою очередь состояние ключа (открытое или закрытое) определяется наличием двоичной единицы или нуля в разряде регистра управления Ry. Таким образом, двоичный код, задаваемый с регистра (параметр), быстро преобразуется в величину проводимости матрицы от точки «ВХОД» до точки «ВЫХОД» схемы матрицы, а всё остальное не вызывает затруднений, так как быстрое переключение параллельного выходного порта управляющего компьютера к регистрам управления резистивной матрицей реализуется с приемлемой скоростью.
Выходные напряжения резонаторов фрикативных согласных, н носовых гласных, а также трёх фильтров подаются в смеситель (СМ), на выходе которого образуется формантная речь.

Все 10 регулируемых элементов модели, определяющих величину параметров, составляют так называемые управляющие слова, которые хранятся в памяти компьютера и последовательно подаются в синтезатор. Перенастройка управления синтезатора происходит с частотой 100 Гц. Учитывая, что каждое управляющее слово состоит из 8-битового байта, синтезатором можно управлять при параллельной передаче управляющих слов со скоростью 900 байт/c. Но это ещё не скорость выдачи фонем на выход синтезатора, а всего лишь скорость передачи данных в самом синтезаторе, необходимая для текущих регулировок фильтров, высоты голосового тона и амплитуд при воспроизведении каждой отдельной фонемы. Данная информация хранится, как правило, в специальной управляющей таблице в памяти компьютера отдельно для каждой фонемы и её вариаций – аллофонов. Она вызывается в виде последовательности, которая определяется входной последовательностью фонем в речевом выходе управляющей программы. Например, по каждой фонеме, которая вводится в компьютер, компьютерное управление синтезатором может потребовать до 30 полных перенастроек системы фильтров. Это означает следующее: чтобы компьютер выдавал схеме управления формантного синтезатора по 900 байт в секунду, в программу опроса справочной таблицы, которая управляет синтезатором, требуется вводить всего по 30 байт в секунду. Это соответствует тому, что выдача данных конечному пользователю производится со скоростью около 240 бит в секунду.
В то время как указанные выше скорости перенастройки фильтров могут меняться от системы к системе, зависимость между числом воспроизводимых фонем и размерами управляющей таблицы остаётся практически неизменной. Естественно, чем больше число обращений к справочной таблице по каждой фонеме, тем большей плавностью будет отличаться синтетическая речь и тем ближе будет она по звучанию к естественной артикуляции.
На рис. 13 приведена структурная схема синтезатора формантного типа, реализованного на практике одной из западных фирм. В данной структуре используются всего 8 параметров настройки: частота и амплитуда основного тона (F0, A0), три формантные частоты (F1, F2, F3), амплитуда и частота сигнала шума, задающие свистящие и шипящие звуки (Аш, Fш), а также параметр «придыхания». Приведённая структура синтезатора соответствует модели, рассмотренной выше.
На структуре синтезатора, состоящего из двух трактов, использованы следующие обозначения блоков устройства.
Первый тракт:
ГВОТ – управляемый генератор (F0, A0) высоты основного тона;
У1 – усилитель;
Ф1, Ф2, Ф3, Ф4 – фильтры (сглаживающий – Ф1 и фильтры формантных частот – Ф2,Ф3 Ф4)
Эти компоненты структуры участвуют в формировании гласных звуков. Формирование большинства согласных звуков производится с помощью тех же фильтров при подаче на них сигналов с управляемого аттенюатора (делителя напряжения)(AT) и сигнала шума с генератора шума (ГШ).
Второй тракт:
ГШ – генератор шума;
У2 – управляемый усилитель (ГШ);
Ф5 – управляемый фильтр (ГШ);
СМ – смеситель сигналов первого и второго трактов.
Сигналы от этих трактов подаются на смеситель (СМ) далее на усилитель, к выходу которого подключён громкоговоритель (Гр). Эта схема довольно точно воспроизводит голосовой тракт человека.
На рис. 14, а приведён пример изменения параметров в процессе синтеза речевого сигнала «SIKS», соответствующего произношению английского слова «SIX».
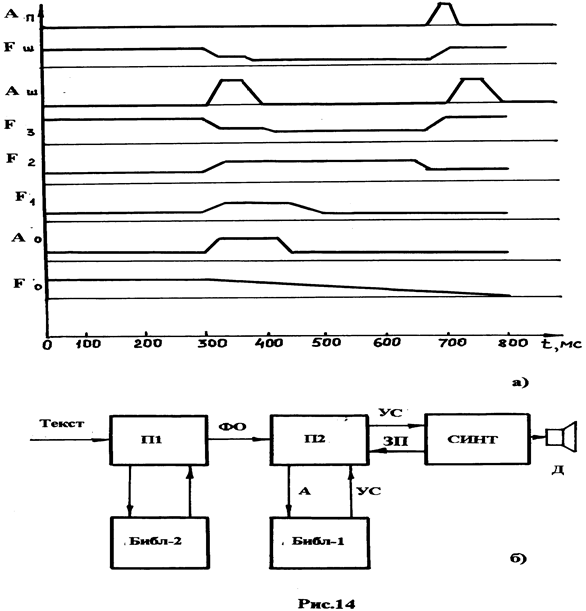
Конструирование речевого сообщения (РС) при формантном синтезе и (вообще по правилам) включает в себя два этапа:
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 507; Нарушение авторских прав?; Мы поможем в написании вашей работы!