КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Для проверки данной гипотезы вычисляется выборочная статистика
|
|
|
|
Статистическая значимость логит и пробит - моделей и факторов этих моделей
Проверка значимости модели при помощи теста отношения правдоподобия(тест Вальда), начинается с выдвижения основной гипотезы:
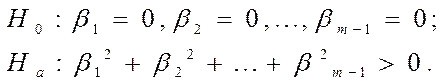
Z*=LR
(4.7.1)
LR=2(lnL-lnL0).
Здесь lnL величина максимального значения логарифма функции правдоподобия, а lnL0- величина логарифма функции правдоподобия в случае справедливости основной гипотезы.
Если основная гипотеза верна, то выборочная статистика (4.7.1) распределена по закону c2 с (m-1) степенью свободы. Границу правосторонней критической области К2 ищут по таблицам критических точек хи-квадрат по уровню значимости (1-α) и (m-1) степени свободы. Если выполняется неравенство:
Z*≥ К2,
то основную гипотезу отвергают, принимают альтернативную гипотезу и говорят, что модель статистически значима. В противном случае принимают гипотезу о не значимости модели и переходят к ее пересмотру.
Для моделей бинарного выбора, значимость факторов проверяется при помощи тестирования для каждого фактора х i, i=1,…, (m- 1) гипотез вида:
Н0: bi=0,
Ha: bi≠ 0.
(4.7.2)
Выборочные статистики, которые используются для тестирования этих гипотез, имеют асимптотически нормальное распределение и называются z-статистиками. Границу двусторонней критической области ищут по таблицам Лапласа по заданному уровню значимости (1-α).
Если выполняется неравенство:
К 1<Z*<К2
то принимают основную гипотезу о незначимом отличии от нуля коэффициента bi и делают вывод, что соответствующий ему фактор незначим для модели.
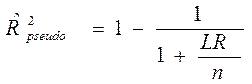
Для моделей бинарного выбора не определяется понятие коэффициента детерминации. Однако для них определяют так называемый псевдо коэффициент детерминации, который уже не характеризует объясняющую силу модели
Определение 4.7.1. Псевдо - коэффициентом детерминации называют следующую величину:
Определение 4.7.2. Индексом отношения правдоподобия Макфаддена (McFadden) называют характеристику:
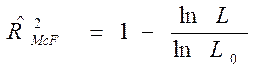
Следует подчеркнуть, что если параметры модели бинарного выбора незначимо отличаются от нуля, то оба введенных коэффициента равны нулю.
На лекции мы рассмотрели нелинейные регрессионные модели, в частности, модели для бинарной зависимой переменной. Эти модели мы рассмотрели для двух функций регрессий: логит (использовали логистическую функцию) и пробит (использовали функцию распределения стандартного нормального закона распределения). Оценки параметров таких функций регрессии получают при помощи метода максимального правдоподобия. Модель тестируют при помощи теста Вальда, в основе которого статистика, имеющая хи-квадрат распределение.
При изучении многофакторных регрессионных моделей мы интерпретировали оценки параметров вj, как предельный эффект влияния независимых переменных на у.
Вернемся к моделям бинарного выбора. Если мы попытаемся найти производную от P{Y=1|X}, то придем к следующему выражению:
 P{Y=1|X}=
P{Y=1|X}=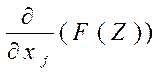
где Z= b0+b1х1+...bm-1xm-1.
По теореме о производной сложной функции, и из свойства плотности (производная от функции распределения это плотность распределения f(Z)), получаем:
P{Y=1|X}=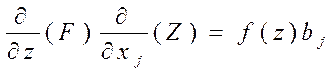
или, используя второе обозначение для оценок параметров:
P{Y=1|X}=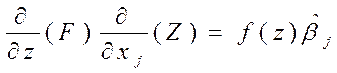
P{Y=1|X}=вjf(Z)
Как и раньше, через вj обозначены оценки неизвестных параметров.
Тогда, мы можем рассуждать следующим образом: плотность распределения всегда неотрицательна, поэтому знак производной 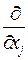 P{Y=1|X} будет зависеть только от знака оценки параметров, но будет являться функцией всех независимых переменных. Причем, если оценка параметра будет положительной, то увеличение переменной xj будет приводить к увеличению вероятности P{Y=1|X}, а если оценка параметра будет отрицательной, то, соответственно, к уменьшению указанной вероятности.
P{Y=1|X} будет зависеть только от знака оценки параметров, но будет являться функцией всех независимых переменных. Причем, если оценка параметра будет положительной, то увеличение переменной xj будет приводить к увеличению вероятности P{Y=1|X}, а если оценка параметра будет отрицательной, то, соответственно, к уменьшению указанной вероятности.
Замечание. Если фактор х является бинарной переменной, то для него нельзя ввести понятие предельного эффекта.
Для каждой переменной х (количественной!!!) вводят так называемый средний предельный эффект. Для этого вычисляют выборочные средние для количественных переменных и процент «1» для бинарных, и подставляют их в выражение для плотности распределения вместо переменных.
Еще один вопрос для обсуждения: как после оценивания параметров логит (пробит) модели прогнозировать значение у? Поступают, например, следующим образом. Подставляют найденные значения оценок параметров и значения хj в Z и вычисляют значение переменной. Если Z>0, то считают, что У=1, если Z<0, то считают, что У=0. Замечание. Мы рассмотрели ситуацию, когда переменная у была измерена в номинальной шкале, но принимала всего два значения: 0 и 1. В общем случае, когда у может принимать несколько значений, например 0, 1, 2, 3, используют множественный (по у!!) логит или пробит. Кроме того, у может быть измерен в порядковой шкале, тогда в Стате используют порядковый логит (пробит) ologit (oprobit).
Замечание. Очень часто в исследованиях приходится проводить исследования на усеченной выборке. Например, если изучают доходы домохозяйств, то бывают ситуацию, когда респондентов с очень большим доходом (например, больше 1 млн.рубл.) следует исключить из исследования, то есть
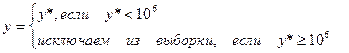
То в таких случаях используют Тобит-модели.
| Yi | ||
| Pi | 1- F(b0+b1х1+...bm-1xm-1) | F(b0+b1х1+...bm-1xm-1) |
| E[Y] | F(b0+b1х1+...bm-1xm-1) | |
| V[Y] | F(b0+b1х1+...bm-1xm-1) - (F(b0+b1х1+...bm-1xm-1))2 |
|
|
|
|
Дата добавления: 2013-12-13; Просмотров: 992; Нарушение авторских прав?; Мы поможем в написании вашей работы!