КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Характеристика генетичних операцій і основних етапів роботи ГА
|
|
|
|
Хотілося б відзначити, що ГА є досить ефективним і разом з тим досить складним інструментом для рішення великого класу задач, внаслідок чого сам ГА вимагає досить тонкого й складного настроювання. При рішенні прикладних задачь у кожному конкретному випадку можливе використання ГА з досить специфічними особливостями, що полягають в обраному дослідником наборі генетичних операцій, порядку застосування цих операцій, значенні власних параметрів ГА й ряду інших характеристик.
При конкретній практичній реалізації ГА його структурна схема може абсолютно не збігатися зі схемою на рисунок 9.3. Процес синтезу структури ГА є ітераційним.
а) кодування
Кодування як автоматична операція в процесі роботи ГА не виконується (!) – це один з найбільш важливих попередніх, творчих процесів здійснюваних дослідником (інженером) при проектуванні роботи ГА.
Даний етап припускає визначення способу компонування, побудови хромосоми, способу представлення в ній інформації.
Від якості рішення задачі кодування принципово залежить ефективність роботи ГА, аж до можливості рішення задачі взагалі.
Таблиця 9.2
Дешифрування фрагментів хромосом
| Код Гріючи | Двійково–десятковий код | Десяткове значення зрушення |
Процедура кодування дозволяє перейти від фенотипу до генотипу, тобто представити набір шуканих змінних у вигляді деякого закодованого рядка – хромосоми. Найбільш широке поширення при використанні ГА одержало двійкове кодування з використанням 0 і 1. Перевагою даного способу є простота, природність і висока ефективність застосування генетичних операцій. Відносно широке поширення одержав спосіб подання інформації в хромосомі у десятковій системі числення. Даний підхід дозволяє зекономити частину обчислювальних ресурсів при декодуванні генотипу у фенотип (тому що не вимагає перерахування значень параметрів з однієї системи числення в іншу). Крім того в деяких випадках доцільно використовувати підхід до кодування інформації з використанням алфавіту з 3–ех елементів: 1, 0 і #, де # – означає, що на даній позиції може бути як 1 так і 0, тобто значення цієї позиції не істотно для фенотипу. Використання інших видів кодування знайшло менш широке вживання.
При використанні двійкового кодування в ГА необхідно використати не двійково–десятковий код, а спеціальний код Грєя (таб. 9.2).
Крім вибору коду для подання інформації варто звернути увагу на наступні моменти:
1. Більш творчо ставитись до вибору змісту шуканого параметра, який кодується – це може бути не просто значення деякого параметра системи: у деяких випадках це може бути номер певної операції, при визначенні оптимального ланцюжка операцій; це може бути фіксована назва деякої змінної, а значима інформація може бути в положенні гена в хромосомі; це може бути вага деякого правила при настроюванні бази знань; при генетичному (еволюційному) програмуванні це можуть бути змінні, константи, операції й навіть окремі функції й процедури тощо.
2. Визначившись зі змістом параметра, який кодується кожним геном необхідно чітко визначити алельний алфавіт, тобто перелік всіх можливих припустимих значень гена. Іншими словами необхідно визначити перелік тих значень генів які при декодуванні не втратять сенс у рамках розв'язуваної задачі.
3. При компонуванні хромосоми гени відповідальні за кодування параметрів однієї й тієї ж підсистеми (підзадачі) повинні бути розташовані максимально близько одна від іншої. Чим сильніше взаємозалежні підсистеми (підзадачі) одна від іншої, тим ближче повинні бути розташовані гени в хромосомі відповідальні за кодування параметрів цих підсистем (підзадач).
4. Будь–яка інформація в ГА представляється по суті в дискретному виді (таб. 9.2). В зв’язку з чим при кодуванні необхідно вибрати таку розмірність коду для кожного гена, якаб забезпечила перекриття динамічного діапазону параметра, що кодується з необхідною точністю, що буде визначатись ціною однієї дискрети.
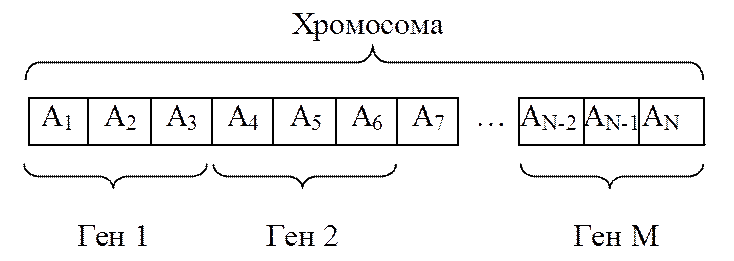
Рисунок 9.4 – Приклад хромосоми
При розгляді інших етапів і операцій для прикладів будемо використовувати хромосоми із двійковим кодуванням. Будемо вважати, що кожна змінна Xj кодується певним фрагментом хромосоми – геном (див. рисунок 9.4). У будь–якій позиції хромосоми може стояти як нуль, так і одиниця. Розташовані поруч фрагменти не відокремлюють один від одного якими–небудь маркерами, проте, при декодуванні хромосоми протягом усього періоду моделювання еволюційного процесу використовується одна й та сама маска розташування генів.
Згадаємо про деякі менш розповсюджені способи кодування й подання інформації в хромосомі.
В [7-13] описується диплоідний спосіб кодування інформації в хромосомі, що в природних умовах відповідає статевому способу розмноження і є більше досконалим способом відтворення потомства. Раніше ми розглядали гаплоідний спосіб кодування при якому генотип однозначно відповідає фенотипу. При диплоідному кодуванні немає однозначного зв'язку між фенотипом і генотипом. Алельний алфавіт при бінарному кодуванні складається з 4 символів: А – домінантної одиниці, а – рецесивної одиниці, В – домінантного нуля, b – рецесивного нуля. Кожна особина (генотип) складається з 2–х батьківських хромосом. Декодування виробляється у два етапи. Спершу із двох хромосом з урахуванням ознак домінантності–рецесивності формується бінарний рядок згідно таблиці 9.3. Після чого бінарний рядок декодуєтся в вектор параметрів як при гаплоідному кодуванні.
Таблиця 9.3 – Таблиця декодування при диплоідному кодуванні інформації в ГА
| Хромосома 1 | Хромосома 2 | Бінарний рядок |
| А | А | |
| А | а | |
| а | А | |
| a | a | |
| B | B | |
| B | b | |
| b | B | |
| b | b | |
| A | B | |
| A | b | |
| B | a | |
| b | a |
Диплоідний спосіб кодування вимагає додаткових ресурсів при його моделюванні, крім того ГА з таким способом кодування, як правило, має гіршу швидкість збіжності (у порівнянні з гаплоідним способом кодування), однак дозволяє більш ретельно досліджувати простір пошуку й з меншою ймовірністю «застряє» у локальних екстремумах, що особливо важливе при нестаціонарній цільовій функції. Розглянутий варіант кодування інформації в ГА в більшій мірі схожий із природними процесами, однак і він є істотним спрощенням цих процесів.
Висновок: Вибір способу кодування визначає припустимий перелік і різновид операцій зміни (схрещування, мутації, інверсії).
б) формування початкової (вихідної) популяції
Хромосоми генеруються випадковим чином (за рівномірним законом розподілу ймовірності), шляхом послідовного заповнення розрядів (генів), відразу в бінарному вигляді, і всякі наступні зміни в популяції зачепають спочатку генетичний рівень, а тільки потім аналізуються фенотипічні наслідки цих змін, але ніколи не навпаки. Можливо, якщо апріорно відомі деякі характеристики простору пошуку, вихідна популяція може формуватися не за рівномірним законом, а по нормальному з урахуванням відомих околиць екстремумів, хоча це в деякому розумінні суперечить ідеям еволюційних обчислень.
Величина популяції (тобто кількість хромосом) – один з найважливіших параметрів при практичному використанні ГА. У випадку занадто малої величини популяції відносно швидко відбувається збіжність ГА до локального оптимуму. У противному випадку затрачаються більші обчислювальні ресурси й час очікування поліпшення результатів може бути дуже тривалим. Розмір популяції може бути фіксованої й змінної довжини.
Існують ГА, у яких одночасно можуть існувати не одна, а відразу кілька популяцій. При цьому обов'язково передбачається спеціальний механізм, що визначає порядок взаємодії особин з різних популяцій між собою (через фіксовану кількість епох, через фіксований проміжок часу, при досягненні певного значення функції пристосованості, при досягненні певного поліпшення функції пристосованості, при певному взаємному положенні хромосом у просторі пошуку; випадкові хромосоми, тільки кращі, тільки гірші, кращі хромосоми з однієї популяції й гірші з інший і т.п.). Кожній популяції може приділятися різна роль: популяції можуть бути приблизно однаковими по своїх характеристиках і призначенню, або ж використовуватись для різних цілей (наприклад, одна популяція – для дослідження простору пошуку, інша – для поліпшення рішень в околицях локальних екстремумів).
в) відбір
Етап відбору в ГА припускає здійснення вибору для подальшого використання частини хромосом з популяції (або якщо подивитися на це з іншого боку – це етап відсівання, відкидання менш ефективних хромосом). Даний етап включає операції декодування, оцінки (обчислення функції пристосованості) і власне вибору.
г) декодування
Дана операція передбачає перетворення зворотні кодуванню, тобто перехід від генотипу до фенотипу (таб.1), що необхідно для обчислення значення функції пристосованості.
д) оцінка
Етап оцінки – етап обчислення ФП. Необхідно підкреслити, що в генетичному алгоритмі лише одна деталь має прив'язку до конкретної розв'язуваної завдачі – це функція пристосованості. Інші оператори можуть бути вільно перенесені для рішення інших задач без змін і в будь–яких комбінаціях.
Спосіб обчислення ФП у значній мірі визначається способом кодування (мається на увазі не вид коду: двійковий або десятковий, а спосіб компонування хромосоми, сенс значення гена й т.п.).
При визначенні ФП потрібно виділити наступні головні моменти:
1. ФП повинні бути адекватні задачі, яка вирішується. Це означає, що для успішного пошуку необхідно, щоб розподіл значень ФП збігались з розподілом реальної якості рішень (не завжди "якість" рішення еквівалентна його оцінці по ФП). Простіше кажучи, ФП завжди повинна прагнути задовольнити умові: для всіх рішень X виконується F(X1)<F(X2) при K(X1)<K(X2), де K(X) – реальна якість рішення, а F(X) – його оцінка по ФП.
2. ФП повинна мати рельєф. Більш того, рельєф повинен бути різноманітним. Це означає, що ГА має мало шансів на успіх, якщо на поверхні ФП є величезні "плоскі" ділянки. Це призводить до того, що багато рішень в популяції (або, що гірше – усі рішення) при розходженні в генотипі будуть мати однакове значення ФП, алгоритм не буде мати можливості вибрати краще рішення, вибрати напрямок подальшого розвитку.
3. Обчислення ФП повинне вимагати мінімум ресурсів. Так, як ця деталь алгоритму найбільш часто використовується, швидкість її обчислення має істотний вплив на швидкість роботи алгоритму в цілому.
4. Для виключення передчасної збіжності ГА до локального екстремуму, значення ФП необхідно масштабувати.
Масштабування проводиться для забезпечення відповідного рівня конкуренції хромосом під час репродукції. У випадку відсутності масштабування проявляється прагнення до домінування в процесі селекції з боку невеликої кількості «суперіндивідів». У такій ситуації значення ФП повинні бути зменшені, щоб уникнути домінування в популяції. Найбільш часто застосовуються наступні методи масштабування: лінійне масштабування, σ– відрізання, і ступеневе масштабування.
При лінійному масштабуванні модифіковану ФП 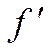 отримують із початкової f, застосовуючи лінійне перетворення виду
отримують із початкової f, застосовуючи лінійне перетворення виду 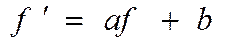 , де a, b – коефіцієнти лінійного перетворення. Ці коефіцієнти варто підбирати таким чином, щоб були виконані умови:
, де a, b – коефіцієнти лінійного перетворення. Ці коефіцієнти варто підбирати таким чином, щоб були виконані умови:
1. Незмінність середнього значення ФП у популяції.
2. Максимальне значення промасштабованої ФП повинне бути на рівні певної кратності середнього пристосування.
У методі σ– відрізання, 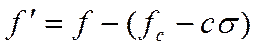 , де с – кратність, рівна 1–З,
, де с – кратність, рівна 1–З, 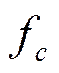 – середнє значення f по популяції.
– середнє значення f по популяції.
Ступеневе масштабування пов'язане зі зведенням вихідної ФП у деякий ступінь: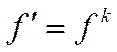 , де k – масштабний коефіцієнт.
, де k – масштабний коефіцієнт.
Приведемо приклад визначення значення ФП, для випадку рішення завдання класифікації. Значення ФП для конкретної хромосоми, у цьому випадку визначається як відношення кількості правильних відповідей до загальної кількості прикладів, які застосовувались при навчанні.
Також на даному етапі з подальшого розгляду виключаються хромосоми з неприпустимим (не маючим сенсу) значенням алелей.
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 391; Нарушение авторских прав?; Мы поможем в написании вашей работы!