КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Текст лекции. Лекция 41 Алгоритмы сжатия данных
|
|
|
|
Лекция 41 Алгоритмы сжатия данных.
Упражнения
Вопросы
Набор для практики
1. Почему поиск на бинарных деревьях не дает выигрыша по сложности по сравнению с линейными структурами?
2. С какой целью производится балансировка деревьев?
3. Какое из деревьев: упорядоченное, случайное, оптимальное или сбалансированное по АВЛ – дает наибольший выигрыш по трудоемкости? Рассмотрите различные случаи.
4. Выполните левое малое вращение дерева, приведенного на рис 3.
5. Выполните левое большое вращение дерева, приведенного на рис 4.
6. Как выполняется балансировка элементов в упорядоченных после вставки или удаления элемента?
7. Всегда ли возможна балансировка упорядоченных деревьев? Ответ обоснуйте.
8. Как выполняется балансировка элементов в АВЛ-деревьях после вставки или удаления элемента?
1. На основании приведенных в лекции кодов реализуйте основные операции, производимые в бинарном дереве поиска и АВЛ-дереве.
2. Реализуйте алгоритм удаления элемента из АВЛ-дерева.
3. В упорядоченном двоичном дереве с целочисленными ключами возведите в квадрат корневой элемент. Выполните балансировку дерева.
4. Найдите в АВЛ-дереве такое поддерево, которое является упорядоченным бинарным деревом.
5. Найдите в АВЛ-дереве такое поддерево максимальной высоты, которое является упорядоченным бинарным деревом.
Литература
1. Ахо А., Хопкрофт Дж., Ульман Д. Структуры данных и алгоритмы. Уч. пособие. — М.: Вильямс, 2000. – 384с.
2. Кнут Д.Э. Искусство программирования. Том 3. Сортировка и поиск, 3-е изд.: Пер. с англ.: Уч. пос. – М.: Вильямс, 2000. – 832 с.
3. Кормен Т., Леверсон Ч.., Ртвест Р. Алгоритмы. Построение и анализ. — М.: МЦНМО, 1999. – 960 с.
4. Подбельский, В.В. Программирование на языке Си: учеб. пособие / В.В. Подбельский, С.С. Фомин. – М.: Финансы и статистика, 2004. – 600 с.
5. Подбельский, В.В. Язык Си++: учеб. пособие / В.В. Подбельский. – М.: Финансы и статистика, 2005. – 560 с.
6. Сэджвик Р. Фундаментальные алгоритмы на С++. Части 1-4. Анализ, структуры данных, сортировка, поиск. — М.: Диасофт, 2001. – 687 с.
7. Хусаинов Б.С. Структуры и алгоритмы обработки данных. Примеры на языке Си. Учебное пособие. – М.: Финансы и статистика, 2004. – 464 с.
Краткая аннотация лекции.
В лекции рассматриваются основные понятия и алгоритмы сжатия данных, приводятся примеры программной реализации алгоритма Хаффмана через префиксные коды и на основе кодовых деревьев.
Цель лекции: изучить основные виды и алгоритмы сжатия данных и научиться решать задачи сжатия данных по методу Хаффмана и с помощью кодовых деревьев.
Основоположником науки о сжатии информации принято считать Клода Шеннона. Его теорема об оптимальном кодировании показывает, к чему нужно стремиться при кодировании информации и насколько та или иная информация при этом сожмется. Кроме того, им были проведены опыты по эмпирической оценке избыточности английского текста. Шенон предлагал людям угадывать следующую букву и оценивал вероятность правильного угадывания. На основе ряда опытов он пришел к выводу, что количество информации в английском тексте колеблется в пределах 0,6 – 1,3 бита на символ. Несмотря на то, что результаты исследований Шеннона были по-настоящему востребованы лишь десятилетия спустя, трудно переоценить их значение.
Сжатие данных – это процесс, обеспечивающий уменьшение объема данных путем сокращения их избыточности. Сжатие данных связано с компактным расположением порций данных стандартного размера. Сжатие данных можно разделить на два основных типа:
· Сжатие без потерь (полностью обратимое) – это метод сжатия данных, при котором ранее закодированная порция данных восстанавливается после их распаковки полностью без внесения изменений. Для каждого типа данных, как правило, существуют свои оптимальные алгоритмы сжатия без потерь.
· Сжатие с потерями – это метод сжатия данных, при котором для обеспечения максимальной степени сжатия исходного массива данных часть содержащихся в нем данных отбрасывается. Для текстовых, числовых и табличных данных использование программ, реализующих подобные методы сжатия, является неприемлемыми. В основном такие алгоритмы применяются для сжатия аудио- и видеоданных, статических изображений.
Алгоритм сжатия данных (алгоритм архивации) – это алгоритм, который устраняет избыточность записи данных.
Введем ряд определений, которые будут использоваться далее в изложении материала.
Алфавит кода – множество всех символов входного потока. При сжатии англоязычных текстов обычно используют множество из 128 ASCII кодов. При сжатии изображений множество значений пиксела может содержать 2, 16, 256 или другое количество элементов.
Кодовый символ – наименьшая единица данных, подлежащая сжатию. Обычно символ – это 1 байт, но он может быть битом, тритом {0,1,2}, или чем-либо еще.
Кодовое слово – это последовательность кодовых символов из алфавита кода. Если все слова имеют одинаковую длину (число символов), то такой код называется равномерным (фиксированной длины), а если же допускаются слова разной длины, то – неравномерным (переменной длины).
Код – полное множество слов.
Токен – единица данных, записываемая в сжатый поток некоторым алгоритмом сжатия. Токен состоит из нескольких полей фиксированной или переменной длины.
Фраза – фрагмент данных, помещаемый в словарь для дальнейшего использования в сжатии.
Кодирование – процесс сжатия данных.
Декодирование – обратный кодированию процесс, при котором осуществляется восстановление данных.
Отношение сжатия – одна из наиболее часто используемых величин для обозначения эффективности метода сжатия.
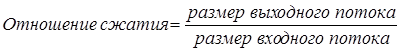
Значение 0,6 означает, что данные занимают 60% от первоначального объема. Значения больше 1 означают, что выходной поток больше входного (отрицательное сжатие, или расширение).
Коэффициент сжатия – величина, обратная отношению сжатия.
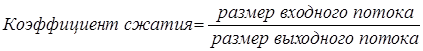
Значения больше 1 обозначают сжатие, а значения меньше 1 – расширение.
Средняя длина кодового слова – это величина, которая вычисляется как взвешенная вероятностями сумма длин всех кодовых слов.
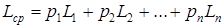 ,
,
где 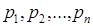 – вероятности кодовых слов;
– вероятности кодовых слов;
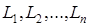 – длины кодовых слов.
– длины кодовых слов.
Существуют два основных способа проведения сжатия.
· Статистические методы – методы сжатия, присваивающие коды переменной длины символам входного потока, причем более короткие коды присваиваются символам или группам символам, имеющим большую вероятность появления во входном потоке. Лучшие статистические методы применяют кодирование Хаффмана.
· Словарное сжатие – это методы сжатия, хранящие фрагменты данных в «словаре» (некоторая структура данных). Если строка новых данных, поступающих на вход, идентична какому-либо фрагменту, уже находящемуся в словаре, в выходной поток помещается указатель на этот фрагмент. Лучшие словарные методы применяют метод Зива-Лемпела.
Рассмотрим несколько известных алгоритмов сжатия данных более подробно.
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 989; Нарушение авторских прав?; Мы поможем в написании вашей работы!