КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Развитие 32- х разрядной архитектуры процессоров Intel
|
|
|
|
В процессе развития архитектуры IA-32 производилось расширение возможностей обработки данных, представленных в различных форматах (рис. 1). Процессоры i386 выполняли обработку только целочисленных операндов. Для обработки чисел с “плавающей точкой” использовался внешний сопроцессор i387, подключаемый к микропроцессору. В состав процессоров i486 и последующих моделей Pentium введён специальный блок FPU (Floating-Point Unit), выполняющий операции над числами с “плавающей точкой”. В процессорах Pentium MMX была впервые реализована групповая обработка нескольких целочисленных операндов разрядностью 1, 2, 4 или 8 байт с помощью одной команды. Такая обработка обеспечивается введением дополнительного блока MMX (Milti-Media Extension — Мультимедийное Расширение). Название блока отражает его направленность на обработку видео- и аудиоданных, когда одновременное выполнение одной операции над несколькими операндами позволяет существенно повысить скорость обработки изображений и звуковых сигналов. Начиная с модели Pentium III, в процессоры вводится блок SSE (Streaming SIMD Extension — Потоковое SIMD-расширение) для групповой обработки чисел с “плавающей точкой”.
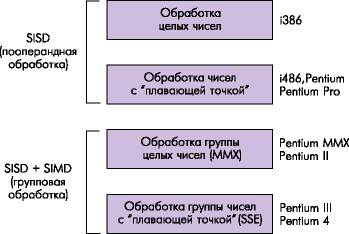
Рисунок 1 - Эволюция архитектуры IA-32
Таким образом, если первые модели процессоров Pentium выполняли только пооперандную обработку данных по принципу “Одна команда – Одни данные” (SISD — Single Instruction – Single Data), то, начиная с процессора Pentium MMX, реализуется также их групповая обработка по принципу “Одна команда – Много данных” (SIMD — Single Instruction – Multiple Data).
Соответственно, расширяется и набор регистров процессора, используемых для промежуточного хранения данных (рисунок 2). Кроме 32-разрядных регистров для хранения целочисленных операндов, процессоры Pentium содержат 80-разрядные регистры, которые обслуживают блоки FPU и MMX. При работе FPU регистры ST0-ST7 образуют кольцевой стек, в котором хранятся числа с “плавающей точкой”, представленные в формате с расширенной точностью (80 разрядов). При реализации MMX-операций они используются как 64-разрядные регистры MM0-MM7, где могут храниться несколько операндов (8 8-разрядных, 4 16-разрядных, 2 32-разрядных или один 64-разрядный), над которыми одновременно выполняется поступившая в процессор команда (арифметическая, логическая, сдвиг и ряд других).
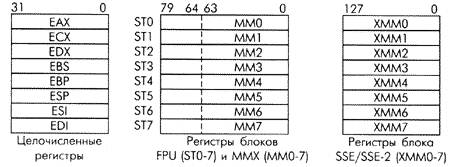
Рисунок 2 - Регистры хранения данных в процессорах Pentium
Блок SSE-2, введённый в состав процессора Pentium 4, значительно расширяет возможности обработки нескольких операндов по принципу SIMD, по сравнению с блоком SSE в модели Pentium III. Этот блок реализует 144 новые команды, обеспечивающих одновременное выполнение операций над несколькими операндами, которые раcполагаются в памяти и в 128-разрядных регистрах XMM0-XMM7. В регистрах могут храниться и одновременно обрабатываться 2 числа с “плавающей точкой” в формате двойной точности (64 разряда) или 4 числа в формате одинарной точности (32 разряда). Этот блок может также одновременно обрабатывать целочисленные операнды: 16 8-разрядных, 8 16-разрядных, 4 32-разрядных или 2 64-разрядных. В результате производительность процессора Pentium 4 при выполнении таких операций оказывается вдвое выше, чем Pentium III.
Операции SSE-2 позволяют существенно повысить эффективность процессора при реализации трёхмерной графики и Интернет-приложений, обеспечении сжатия и кодирования аудио- и видеоданных и в ряде других применений.
Введение большой группы команд SSE-2 является основной особенностью реализованного в Pentium 4 варианта архитектуры IA-32. Что касается базового набора команд и используемых способов адресации операндов, то они практически полностью совпадают с набором команд и способов адресации в предыдущих моделях Pentium. Процессор обеспечивает реальный и защищённый режимы работы, реализует сегментную и страничную организации памяти. Таким образом пользователь имеет дело с хорошо знакомым набором регистров и способов адресации, может работать с базовой системой команд и известными вариантами реализации прерываний и исключений, которые характерны для всех моделей семейства Pentium.
Микроархитектура процессоров Pentium 4
Основные особенности процессора Pentium 4 связаны с его микроархитектурой. Микроархитектура процессора определяет реализацию его внутренней структуры, принципы выполнения поступающих команд, способы размещения и обработки данных. Как анонсировала компания Intel, новая микроархитектура процессора Pentium 4, получившая название NetBurst (пакетно-сетевая), ориентирована на эффективную работу с Интернет-приложениями. Необходимо отметить, что в микроархитектуре NetBurst реализованы многие принципы, использованные в предыдущей модели Pentium III (микроархитектура P6). Характерными чертами этой микроархитектуры являются:
гарвардская структура с разделением потоков команд и данных;
- суперскалярная архитектура, обеспечивающая одновременное выполнение нескольких команд в параллельно работающих исполнительных устройствах;
- динамическое изменение последовательности команд (выполнение команд с опережением — спекулятивное выполнение);
- конвейерное исполнение команд;
- предсказание направления ветвлений.
Практическая реализация данных принципов в структуре процессора Pentium 4 имеет ряд существенных особенностей (рис. 3).
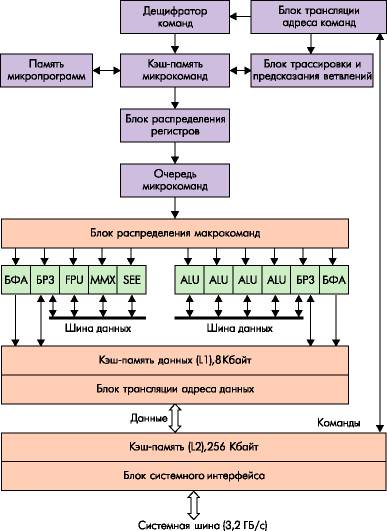
Рисунок 3 - Общая структура Pentium 4
Гарвардская внутренняя структура реализуется путём разделения потоков команд и данных, поступающих от системной шины через блок внешнего интерфейса и размещённую на кристалле процессора общую кэш-память 2-го уровня (L2) ёмкостью 256 Кбайт. Такое размещение позволяет сократить время выборки команд и данных по сравнению с Pentuim III, где эта кэш-память располагается на отдельном кристалле, смонтированном в общем корпусе (картридже) с процессором.
Блок внешнего интерфейса реализует обмен пpоцессоpа с системной шиной, к которой подключается память, контроллеры ввода/вывода и другие активные устройства системы. Обмен по системной шине осуществляется с помощью 64-разрядной двунаправленной шины данных, 41-разрядной шины адреса (33 адресных линии А35-3 и 8 линий выбора байтов BE7-0#), обеспечивающей адресацию до 64 Гбайт внешней памяти.
Дешифратор команд работает вместе с памятью микропрограмм, формируя последовательность микрокоманд, обеспечивающих выполнение поступивших команд. Декодированные команды загружаются в кэш-память микрокоманд, откуда они выбираются для исполнения. Кэш-память может хранить до 12000 микрокоманд. После её заполнения практически любая команда будет храниться в ней в декодированом виде. Поэтому при поступлении очередной команды блок трассировки выбирает из этой кэш-памяти необходимые микрокоманды, обеспечивающие её выполнение. Если в потоке команд оказывается команда условного перехода (ветвления программы), то включается механизм предсказания ветвления, который формирует адрес следующей выбираемой команды до того, как будет определено условие выполнения перехода.
После формирования потоков микрокоманд производится выделение регистров, необходимых для выполнения декодированных команд. Эта процедура реализуется блоком распределения регистров, который выделяет для каждого указанного в команде логического регистра (регистра целочисленных операндов EAX, ECX и других, регистра операндов с плавающей точкой ST0-ST7 или регистра блоков MMX, SSE, рис. 2) один из 128 физических регистров, входящих в состав блоков регистров замещения (БРЗ).
Эта процедура позволяет выполнять команды, использующие одни и те же логические регистры, одновременно или с изменением их последовательности.
Выбранные микрокоманды размещаются в очереди микрокоманд. В ней содержатся микрокоманды, реализующие выполнение 126 поступивших и декодированных команд, которые затем направляются в исполнительные устройства по мере готовности операндов. Отметим, что в процессорах Pentium III в очереди находятся микрокоманды для 40 поступивших команд. Значительное увеличение числа команд, стоящих в очереди, позволяет более эффективно организовать поток их исполнения, изменяя последовательность выполнения команд и выделяя команды, которые могут выполняться параллельно. Эти функции реализует блок распределения микрокоманд. Он выбирает микрокоманды из очереди не в порядке их поступления, а по мере готовности соответствующих операндов и исполнительных устройств. В результате команды, поступившие позже, могут быть выполнены до ранее выбранных команд. При этом реализуется одновременное выполнение нескольких микрокоманд (команд) в параллельно работающих исполнительных устройствах. Таким образом естественный порядок следования команд нарушается, чтобы обеспечить более полную загрузку параллельно включенных исполнительных устройств и повысить производительность процессора.
Суперскалярная архитектура реализуется путём организации исполнительного ядра процессора в виде ряда параллельно работающих блоков. Арифметико-логические блоки ALU производят обработку операндов, которые поступают из заданных регистров БРЗ. В эти же регистры заносится и результат операции. При этом проверяются также условия ветвления для команд условных переходов и выдаются сигналы перезагрузки конвейера команд в случае неправильно предсказанного ветвления. Исполнительное ядро работает с повышенной скоростью выполнения операций. Например, микрокоманда сложения целочисленных операндов при тактовой частоте процессора 1,5 МГц выполняется всего за 0,36 нс.
Адреса операндов, выбираемых из памяти, вычисляются блоком формирования адреса (БФА), который реализует интерфейс с кэш-памятью данных 1-го уровня (L1) ёмкостью 8 Кбайт. В соответствии с заданными в декодированных командах способами адресации формируются 48 адресов для загрузки операндов из памяти в регистр БРЗ и 24 адреса для записи из регистра в память (в Pentium III формируются 16 адресов для загрузки регистров и 12 адресов для записи в память). При этом БФА формирует адреса операндов для команд, которые ещё не поступили на выполнение. При обращении к памяти БФА одновременно выдаёт адреса двух операндов: один для загрузки операнда в заданный регистр БРЗ, второй — для пересылки результата из БРЗ в память. Таким образом реализуется процедура предварительного чтения данных для последующей их обработки в исполнительных блоках, которая называется спекулятивной выборкой.
Аналогичным образом организуется параллельная работа блоков SSE, FPU, MMX, которые используют отдельный набор регистров и блок формирования адресов операндов.
При выборке операнда из памяти производится обращение к кэш-памяти данных (L1), которая имеет отдельные порты для чтения и записи. За один такт производится выборка операндов для двух команд. Время обращения к этой кэш-памяти составляет 1,42 нс при тактовой частоте 1,5 ГГц, что в 2,1 раза меньше, чем при обращении к кэш-памяти данных в процессоре Pentium III, работающем на частоте 1,0 ГГц.
При формировании адресов обеспечивается обращение к заданному сегменту памяти. Каждый сегмент может делиться на страницы, размещаемые в различных местах адресного пространства. Блоки трансляции адреса обеспечивают формирование физических адресов команд и данных при использовании страничной организации памяти. Для сокращения времени трансляции используется внутренняя буферная память, которая хранит базовые адреса наиболее часто используемых страниц.
В Pentuim 4 используется гиперконвейерная технология выполнения команд, при которой число ступеней конвейера достигает 20 (в Pentium — 5 ступеней, в Pentium III — 11). Таким образом одновременно в процессе выполнения может находиться до 20 команд, находящихся на разных стадиях (ступенях) их реализации.
Эффективность конвейера резко снижается из-за необходимости его перезагрузки при выполнении условных ветвлений, когда требуется произвести очистку всех предыдущих ступеней и выбрать команду из другой ветви программы. Чтобы сократить потери времени, связанные с перезагрузкой конвейера, используется блок предсказания ветвлений. Его основной частью является ассоциативная память, называемая буфером адресов ветвлений (BTB — Branch Target Buffer), в которой хранятся 4092 адреса ранее выполненных переходов. Отметим, что в BTB процессора Pentium III хранятся адреса только 512 переходов. Кроме того, BTB содержит биты, хранящие предысторию ветвления, которые указывают, выполнялся ли переход при предыдущих выборках данной команды. При поступлении очередной команды условного перехода указанный в ней адрес сравнивается с содержимым BTB. Если этот адрес не содержится в BTB, то есть ранее не производились переходы по данному адресу, то предсказывается отсутствие ветвления. В этом случае продолжается выборка и декодирование команд, следующих за командой перехода. При совпадении указанного в команде адреса перехода с каким-либо из адресов, хранящихся в BTB, производится анализ предыстории. В процессе анализа определяется чаще всего реализуемое направление ветвления, а также выявляются чередующиеся переходы. Если предсказывается выполнение ветвления, то выбирается и загружается в конвейер команда, размещённая по предсказанному адресу. Усовершенствованный блок предсказания ветвления, используемый в Pentuim 4, обеспечивает 90-% вероятность правильного предсказания. Таким образом резко уменьшается число перезагрузок конвейера при правильном предсказании ветвления.
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 624; Нарушение авторских прав?; Мы поможем в написании вашей работы!