КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция №20
|
|
|
|
Название лекции: Архитектура клиент/сервер. Распределенная обработка
План:
1. Анализ структуры СУБД с точки зрения поддержки приложений БД:
1.1. Понятия сервер и клиент;
1.2. Приложения и типы приложений;
1.3. Понятие распределенной обработки.
2. Распределенная обработка. Простая схема распределенной обработки. Преимущества такой схемы. Примеры.
1. Анализ структуры СУБД с точки зрения поддержки приложений БД.
Архитектура клиент/сервер. Ранее рассмотрена трехуровневая структура СУБД, в основу которой положены три уровня абстракции. Рассмотрим структуру СУБД с точки зрения основной цели, для достижения которой созданы СУБД, а именно поддержка и разработка приложений БД, через которые осуществляется доступ к информации. С этой точки зрения система БД состоит из двух частей: непосредственно СУБД (сервер или машина БД) и внешнего интерфейса (клиенты).
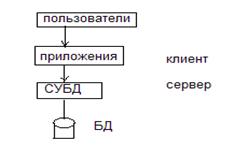 Сервер (машина БД) – это собственно СУБД. Таким образом, СУБД это, прежде всего, программное обеспечение. Хотя это программное обеспечение, для повышения производительности, иногда может быть реализовано на специальной ЭВМ. Сервер поддерживает все основные функции СУБД: определение данных, обработку данных, защиту и целостность и т.д. Обеспечивает поддержку на внешнем, концептуальном и внутреннем уровне. Таким образом в данном контексте сервер– это другое имя СУБД.
Сервер (машина БД) – это собственно СУБД. Таким образом, СУБД это, прежде всего, программное обеспечение. Хотя это программное обеспечение, для повышения производительности, иногда может быть реализовано на специальной ЭВМ. Сервер поддерживает все основные функции СУБД: определение данных, обработку данных, защиту и целостность и т.д. Обеспечивает поддержку на внешнем, концептуальном и внутреннем уровне. Таким образом в данном контексте сервер– это другое имя СУБД.
Клиент – это различные приложения, которые выполняются «над» СУБД.
Типы приложений:
- приложения, написанные пользователем;
- приложения, поставляемые поставщиками СУБД или другими поставщиками программного обеспечения.
Общим у всех приложений является то, что все приложения используют один и тот же интерфейс сервера, а именно интерфейс внешнего уровня.
Исключением являются специальные ''служебные'' приложения, которые работают на внутреннем уровне системы. Такие приложения (утилиты) скорее относятся к компонентам СУБД. Рассмотрим подробнее типы приложений:
Приложения, написанные пользователем. Это прикладные программы, написанные на одном из зыков программирования типа С или специализированном языке. В любом случае эти языки должны иметь интерфейс с подъязыком данных.
Приложения, поставляемые поставщиками (часто называют инструментальными средствами). В целом назначение таких средств – содействовать процессу создания и выполнения других приложений. К таким инструментальным средствам относятся, прежде всего:
- процессоры языков запросов (с помощью которых конечный пользователь может выдавать незапланированные запросы к системе);
- генераторы отчетов, т. е. системы визуализации результатов построенных запросов;
- графические бизнес – системы;
- электронные таблицы;
- процессоры обычных языков программирования;
- средства управления копированием;
- генераторы приложений;
- другие средства разработки приложений, включая CASE–продукты (COMPUTER AIDED SOFTWARE ENGINEERING);
- системы автоматизация разработки программного обеспечения.
Количество и качество имеющихся в СУБД клиентских инструментальных средств должно быть одним из основных факторов при выборе базы данных.
Понятие распределенной обработки. Т.к. СУБД в целом может быть четко разделена на две части (сервер БД и клиенты), то появляется возможность работы этих двух частей на разных машинах, т.е. возможность распределенной обработки. Распределенная обработка предполагает, что отдельные машины можно соединить какой-нибудь коммуникационной сетью, чтобы определенная задача, обрабатывающая данные, могла быть выполнена на нескольких машинах в сети. СУБД, которые не позволяют вести распределенную обработку, могут допускать обработку информации через коммуникационную сеть только в так называемом файл - серверном режиме. В этом режиме программное обеспечение СУБД должно быть загружено в компьютер пользователя и при выборке информации из файла удаленной БД весь файл должен быть перегружен по сети с файл-сервера в компьютер пользователя. Даже при небольшом числе пользователей такой дополнительный трафик может практически парализовать сеть.
Термин клиент/сервер часто подразумевает только распределённую обработку, как дающую максимальную выгоду, хотя такую технологию можно реализовать и на одной ЭВМ.
2. Распределенная обработка.
Один из простых случаев распределенной обработки – это архитектура, в которой сервер СУБД запускается на одной машине, а клиентские приложения на другой.
Термин клиент/сервер – фактически синоним такой схемы.
Преимущества такой схемы:
- параллельная обработка. Для всей задачи применяется несколько процессоров и обработка сервера (базы данных) и клиента (приложения) выполняются параллельно, время ответа уменьшается, производительность обработки растет;
- машина сервера может быть изготовлена по специальному заказу и приспособлена для работы с СУБД, что обеспечит лучшую производительность;
- машина клиента может быть персональной станцией, приспособленной к потребностям конечного пользователя, обеспечивать лучший интерфейс и в целом дополнительные удобства;
- несколько разных машин клиентов могут иметь доступ к одной и той же машине сервера. Таким образом, одна БД может совместно использоваться несколькими отдельными клиентами системы. Такая структура соответствует структуре большинства предприятий.
Пример: работы БД банка:
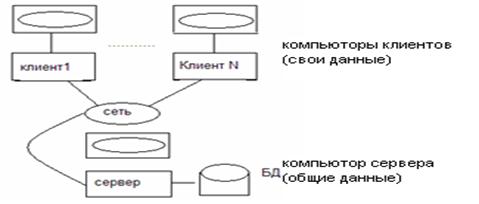
В некоторых случаях, например, для банка весьма вероятно, что пользователям одного отделения банка необходим доступ к данным, сохраняемым в другом отделении. Таким образом, вообще говоря, каждая машина будет выступать в роли сервера для одних пользователей и в роли клиента для других. Иначе каждая машина будет поддерживать полную систему БД.
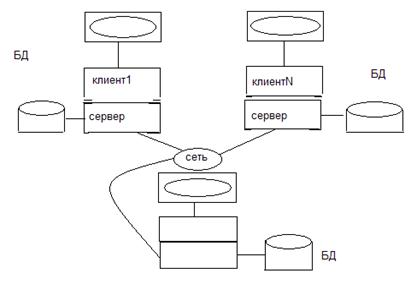 В последнем случае распределение информации, более точно описывает структуру предприятия. Доступ возможен двумя способами: Клиент может получить доступ к любому числу серверов, но лишь к одному в одно и тоже время. В этом случае нет возможности за один запрос получить комбинацию данных с двух и более серверов, кроме того, приложение «должно знать» на какой машине, какая часть данных содержится. При втором способе клиент получает доступ к любому числу серверов одновременно (возможны комбинации) в этом случае все серверы рассматриваются клиентом как один логический сервер и пользователь «может не знать» на какой именно машине, какая часть данных содержится. Такая реализация прозрачна для клиента, но сложна в реализации. Именно этот случай (последний рисунок) называется распределенной системой БД.
В последнем случае распределение информации, более точно описывает структуру предприятия. Доступ возможен двумя способами: Клиент может получить доступ к любому числу серверов, но лишь к одному в одно и тоже время. В этом случае нет возможности за один запрос получить комбинацию данных с двух и более серверов, кроме того, приложение «должно знать» на какой машине, какая часть данных содержится. При втором способе клиент получает доступ к любому числу серверов одновременно (возможны комбинации) в этом случае все серверы рассматриваются клиентом как один логический сервер и пользователь «может не знать» на какой именно машине, какая часть данных содержится. Такая реализация прозрачна для клиента, но сложна в реализации. Именно этот случай (последний рисунок) называется распределенной системой БД.
Лекция №21
Название лекции: Двухзвенные и трехзвенные модели распределения
функций.
План:
1. Двухзвенная модель распределение функций в модели клиент/сервер
2. Понятие о трехзвенной архитектуре модели клиент/сервер
3. Физическая организация данных.
4. Модель организации внешней памяти.
5. Закрепленные и не закрепленные записи.
6. Организация файлов в виде «кучи».
1. Двухзвенная модель распределение функций в модели клиент/сервер.
В БД выполняются 3 основные функции: управление данными, обработка и представление. Если эти 3 функции делятся между 2 ЭВМ, то говорят о двухзвенной модели клиент/сервер
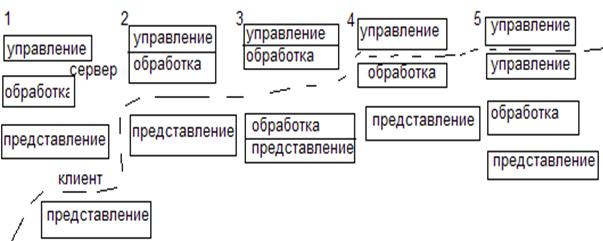
1. распределенное представление - клиент вырожден. Х – терминал, который может быть реализован на компьютере с процессором с ограниченным числом команд.
Преимущество: простота обслуживания, т.к все описание на сервере.
Недостаток: уязвимость центрального компьютера
2. удаленное представление. Процедуры обработки хранятся на сервере
Преимущества: хорошее центральное обслуживание приложений (в одном месте правятся все функции обработки); достаточно эффективное использование ресурсов сети и сервера. Недостатки: сложность выполнения обработки на сервере параллельно с доступом к данным; низкая эффективность использования ЭВМ клиента.
3. распределенная функция.
Преимущество: повышение эффективности использования клиент ЭВМ.
Недостаток: сложность поддержки
4. удаленный доступ к данным по отношению к клиенту.
Преимущества: управление и обработка полностью распределены; высокая эффективность использования клиента и сервера.
Недостатки: более высокая загрузка сети; сложность модификации и сопровождения (функции обработки установлены на всех клиентах, а из нужно сопровождать).
5. распределенная БД. Возможны два варианта реализации: локальная + удаленная БД хранимая как одно целое; - локальная БД является копиями удаленных (репрекация БД) – работа с локальной и синхронизации с удаленной.
Преимущества: гибкость создаваемой информационной системы; высокая живучесть.
Недостатки: затраты на приложения; нужен механизм синхронизации.
Доступ серверам возможен 2-мя способами:
1) Клиент может получить доступ к любому числу сервером, но лишь к 1-му в одно и то же время. Нет возможности за один запрос получить комбинацию данных с 2-х и более серверов.
2) Клиент получает доступ к любому числу серверов одновременно. Возможна комбинация информации. Все серверы клиент рассматривает как 1 логический сервер. (Доступ прозрачен для клиента). Именно этот вариант называется Распределенная БД.
2. Понятие о трехзвенной архитектуре модели клиент/сервер.
Если управление данными, обработка и представление делятся между 3 ЭВМ, то говорят о 3-х уровневой модели.
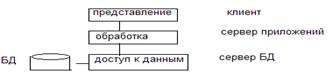 Преимущества: 1. Более полно используются технические возможности компьютеров, а именно сервер БД может быть реализован на компьютере который ориентирован на дисковые возможности, клиентская машина – на удобный интерфейс. 2. Высокая централизация (чтобы изменить, достаточно изменить на сервере). 3. Достаточно эффективное распараллеливание стадий информации (между 3-мя компьютерами).
Преимущества: 1. Более полно используются технические возможности компьютеров, а именно сервер БД может быть реализован на компьютере который ориентирован на дисковые возможности, клиентская машина – на удобный интерфейс. 2. Высокая централизация (чтобы изменить, достаточно изменить на сервере). 3. Достаточно эффективное распараллеливание стадий информации (между 3-мя компьютерами).
Недостаток: Повышенное требование к надежности. (Ломается сервер БД - ломается все).
3. Физическая организация данных.
Будем считать, что на физическом уровне информация хранится в файле, который содержит записи с идентичным форматом.
Формат записи – список имен полей, каждое поле занимает фиксированное число байт и имеет фиксированный тип. Запись состоит из значений каждого поля.
Над файлом требуется выполнить следующие типичные операции:
- включить запись;
- удалить запись;
- модифицировать запись;
- найти запись, удовлетворяющую заданным условиям.
Эффективность физической организации определяется эффективностью реализации этих 4-х операций.
4. Модель организации внешней памяти.
Под внешней памятью чаще всего понимают магнитные диски, но возможны и другие устройства (CD–ROM, ленты, барабаны…).
Отвлекаясь от действительной организации и адресации внешней памяти, предполагаем, что файловая система разделяет внешнюю память на логические блоки равного размера (кластеры). Файл хранится в одном или нескольких блоках. В каждом блоке могут храниться несколько записей. Запись может занимать несколько блоков. Внутри блока может быть пространство, незанятое какими либо записями. Мы предполагаем, что файловая система устанавливает соответствие между именем файла и адресами блоков, которые образуют этот файл. Можно считать, что запись так же имеет адрес, который можно рассматривать либо как абсолютный адрес её первого байта, либо как адрес блока, содержащего запись, плюс смещение записи внутри блока.
Отвлекаясь от действительной природы адресации, для ссылки на блок или запись будем использовать понятие «указатель» подразумевая – номер блока в некотором виртуальном линейном адресном пространстве, занимаемым некоторым файлом. Под указателем на запись иногда будем так же понимать её линейный адрес в некотором виртуальном линейном пространстве занимаемым файлом. Под таким адресом можно понимать, например, номер записи в таблице. Часто под термином «указатель» на запись будем понимать «указатель» на блок, в котором находится запись. В этом случае, для того, чтобы найти нужную запись, необходимо:
- прочитать блок, который её содержит;
- найти в оперативной памяти запись внутри блока.
При таком подходе запись внутри блока можно перемещать, при этом указатель на запись (фактически указатель на блок её содержащий) не изменится. Уменьшается вероятность «зависания указателя» – это когда «указатель» указывает на место, где записи на самом деле нет.
Основная операция с внешней памятью – это передача блока из внешней памяти в оперативную память и наоборот. Поэтому, если говорить о быстродействии различных алгоритмов доступа к данным, то следует подсчитать число блоков, которые должны быть прочитаны в основную память или записаны из неё. Это число и будет представлять оценку быстродействия алгоритма.
Мы предполагаем, что записи блока (т.е. файла) имеют фиксированный размер и состоят из полей фиксированного размера и типа. В этом случае можно легко найти абсолютный адрес записи в файле.
5. Закрепленные и незакрепленные записи.
Для определения стратегии реализации файлов важно, являются ли записи файла «закрепленными» по некоторому фиксированному адресу, или нет.
Записи становятся закрепленными, если где-либо в базе данных могут существовать (хранится) указатели на них.
При закреплении записей мы не можем перемещать записи об этих объектах, иначе указатели на них «зависнут», т.е. не будут указывать на данные, на которые они указывали первоначально.
При закреплении записей не может быть реализован общий случай организации файла, при котором запись удаляется (например, при включении других записей или удалении записей). В этом случае трудно найти, где именно в полной базе необходимо откорректировать указатели на перемещаемые записи.
6. Организация файлов в виде «кучи».
Наиболее очевидный подход к хранению записей файлов заключается в последовательном размещении их в необходимом числе блоков. Часто предполагается, что запись не может перекрывать границу блока (часть блока теряется). Эту организацию иногда называют «кучей».
Блоки, используемые для кучи, могут быть связаны в цепочку указателями (в конце блока указатель на следующий блок). При другой организации выделяют отдельный блок (блоки) в котором хранят список адресов блоков, образующих кучу.
Чтобы включить запись, её необходимо поместить в последний блок, если в нём имеется место, или получить новый блок из операционной системы, если места в последнем блоке больше нет.
Удаление может осуществляться установкой специального бита для каждой записью (признак удаления) в состояние «удалено».
Пример: в файлах формата.dbf под признак удаления записи отводится целый байт.
Повторное использование пространства удаленных записей опасно, и может быть осуществлено, если записи не закреплены. Для освобождения пространства с удаленными записями используют процедуру «сборки мусора», которая освобождает для использования пространство с удаленными записями.
Для поиска нужной записи (удовлетворяющей заданным условиям, например, при заданном значении ключа) в общем случае требуется просмотреть все записи файла (в «среднем» половину записей файла). Если число блоков, образующих файл велико, то такой поиск требует большого количества доступов к внешней памяти и, следовательно, приводит к снижению быстродействия БД. В следующих разделах лекций рассматриваются методы ускорения доступа к информации при организации поиска.
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 535; Нарушение авторских прав?; Мы поможем в написании вашей работы!