КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Восстанавливаемость файловой системы NTFS
|
|
|
|
Файловая система NTFS является восстанавливаемой файловой системой, однако восстанавливаемость обеспечивается только для системной информации файловой системы, то есть каталогов, атрибутов безопасности, битовой карты занятости кластеров и других системных файлов. Сохранность данных пользовательских файлов, работа с которыми выполнялась в момент сбоя, в общем случае не гарантируется.
Для повышения производительности файловая система NTFS использует дисковый кэш, то есть все изменения файлов, каталогов и управляющей информации выполняются сначала над копиями соответствующих блоков в буферах оперативной памяти и только спустя некоторое время переносятся на диск. Однако кэширование, как уже было сказано, повышает риск разрушения файловой системы. В таких условиях NTFS обеспечивает отказоустойчивость с помощью технологии протоколирования транзакций и восстановления системных данных. Пользовательские данные, которые в момент краха находились в дисковом кэше и не успели записаться на диск, в NTFS не восстанавливаются.
Журнал регистрации транзакций в NTFS делится на две части: область рестарта и область протоколирования (рис. 8.8).
- Область рестарта содержит информацию о том, с какого места необходимо будет начать читать журнал транзакций для проведения процедуры восстановления системы после сбоя или краха ОС. Эта информация представляет собой указатель на определенную запись в области протоколирования. Для надежности в файле журнала регистрации хранятся две копии области рестарта.
- Область протоколирования содержит записи обо всех изменениях в системных данных файловой системы, произошедших в результате выполнения транзакций в течение некоторого, достаточно большого периода. Все записи идентифицируются логическим последовательным номером LSN (Logical Sequence Number). Записи о подоперациях, принадлежащих одной транзакции, образуют связанный список: каждая последующая запись содержит номер предыдущей записи. Заполнение области протоколирования идет циклически: после исчерпания всей памяти, отведенной под область протоколирования, новые записи помещаются на место самых старых.

Рис. 8.8. Записи модификации в журнале транзакций
Существует несколько типов записей в журнале транзакций: запись модификации, запись контрольной точки, запись фиксации транзакции, запись таблицы модификации, запись таблицы модифицированных страниц.
Запись модификации заносится в журнал транзакций относительно каждой подоперации, которая модифицирует системные данные файловой системы. Эта запись состоит из двух частей: одна содержит информацию, необходимую системе для повторения этого действия, а другая — информацию для его отмены. Информация о модификации хранится в двух формах — в физическом и в логическом описаниях. Логическое описание используется программным обеспечением уровня приложений и формулируется в терминах операций, например «выделить файловую запись в MFT» или «удалить имя из корневого индекса». На нижнем уровне программного обеспечения, к которому относятся модули самой NTFS, используется менее компактное, но более простое физическое описание, сводящееся к указанию диапазона байт на диске, в которые необходимо поместить определенные значения.
Пусть, например, регистрируется транзакция создания файла lotus.doc, которая включает, как показано на рисунке, три подоперации. Тогда в журнале будут сделаны три записи модификации, содержимое которых приведено в табл. 8.1.
Таблица 8.1. Структура записи модификации
| Запись модификации | Информация для повторения транзакции | Информация для отката транзакции |
| LSN-202 | Выделить и инициировать запись для нового файла lotus.doc в таблице MFT | Удалить запись о файле lotus.doc из таблицы MFT |
| LSN-203 | Добавить имя файла в индекс | Исключить имя файла из индекса |
| LSN-204 | Установить биты 3-9 в битовой карте | Обнулить биты 3-9 в битовой карте |
Журнал транзакций, как и все остальные файлы, кэшируется в буферах оперативной памяти и периодически сбрасывается на диск.
Файловая система NTFS все действия с журналом транзакций выполняет только путем запросов к специальной службе LFS (Log File Service). Эта служба размещает в журнале новые записи, сбрасывает на диск все записи до некоторого заданного номера, считывает записи в прямом и обратном порядке и выполняет некоторые другие действия над записями журнала.
Прежде чем выполнить любую транзакцию, NTFS вызывает службу журнала транзакций LFS для регистрации всех подопераций в журнале транзакций. И только после этого описанные подоперации действительно выполняются над копиями блоков данных файловой системы, находящимися в кэше. Когда все подоперации транзакции выполнены, с помощью службы LFS транзакция фиксируется. Это выражается в том, что в журнал заносится специальный вид записи — запись фиксации транзакции.
Параллельно с регистрацией и выполнением транзакций происходит процесс выталкивания блоков кэша на диск. Сброс на диск измененных блоков выполняется в два этапа: сначала сбрасываются блоки журнала, а потом — модифицированные блоки транзакций. Такой порядок реализуется следующим образом. Каждый раз, когда диспетчер кэша принимает решение о том, что определенные модифицированные блоки (не обязательно все) должны быть вытеснены на диск, он сообщает об этом службе LFS. В ответ на это сообщение LFS обращается к диспетчеру кэша с запросом о записи на диск всех измененных блоков журнала. После того как блоки журнала сброшены на диск, сбрасываются на диск модифицированные блоки транзакций, среди которых могут быть, конечно, и блоки системных данных файловой системы.
Такая двухэтапная процедура сброса данных кэша на диск делает возможным восстановление файловой системы, если во время записи модифицированных блоков из кэша на диск произойдет сбой. Действительно, какие бы неприятности не произошли во время записи модифицированных блоков на диск, вся информация об изменениях, произведенных в этих блоках, уже записана на диск в файл журнала транзакций. Заметим, что все действия, которые были выполнены файловой системой в интервале между последним сбросом данных на диск и сбоем, отменяются сами собой, поскольку все они проводятся только над блоками в кэше и не вызывают никаких изменений содержимого диска.
Какие же дефекты может иметь файловая система после сбоя?
Во-первых, это несогласованность системных данных, возникшая в результате незавершенности транзакций, которые были начаты еще до момента последнего сброса данных из кэша на диск. На рис. 8.9 показана транзакция А, две подоперации которой — ai и а2 — были сделаны до сброса кэша, а еще две — а3 и а4 — после сброса кэша. К моменту сбоя результаты первых двух подопераций могли быть записаны на диск, в то время как изменения, вызванные подоперациями аз и а4, отразились только на копиях блоков файловой системы в кэше и были потеряны в результате сбоя. Чтобы устранить несогласованность, вызванную этой причиной, требуется сделать откат для всех транзакций, незафиксированных к моменту последнего сброса кэша. Для примера, изображенного на рисунке, такими транзакциями являются транзакции А и С. В каждый момент времени NTFS располагает списком незафиксированных транзакций, называемым таблицей незавершенных транзакций (transaction table). Для каждой незавершенной транзакции эта таблица содержит последовательный номер LSN последней по времени подоперации, выполненной в рамках данной транзакции. По этому номеру может быть найдена вся цепочка подопераций транзакции.
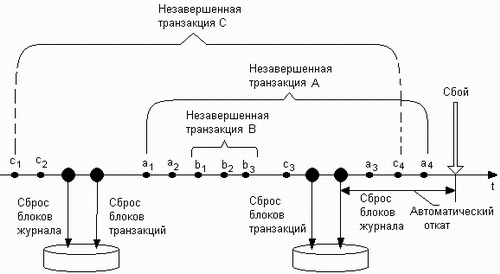
Рис. 8.9. Временная диаграмма событий в файловой системе
Во-вторых, противоречия в файловой системе могут быть вызваны потерей тех изменений, которые были сделаны транзакциями, завершившимися еще до сброса кэша, но которые не были записаны на диск в ходе последнего сброса. На рисунке такой транзакцией может оказаться транзакция В. Чтобы определить, какие завершенные транзакции надо повторять, система ведет таблицу модифицированных страниц1 {dirty page table), находящихся в данный момент в кэше. В таблице для каждой модифицированной страницы указывается, какая транзакция вызвала эти изменения. Повторение транзакций, которые имели дело со страницами, указанными в данном списке, гарантирует, что ни одно изменение не будет потеряно.
1 Дисковый кэш в Windows NT основан на использовании виртуальной памяти, поэтому он оперирует не блоками, а страницами.
Таблицы модифицированных страниц и незавершенных транзакций создаются NTFS на основании записей журнала транзакций и поддерживаются в оперативной памяти. Следует подчеркнуть, что обе эти таблицы не добавляют новой информации в журнал транзакций, они лишь представляют информацию, содержащуюся в записях журнала, в концентрированном виде, более удобном для использования при восстановлении. Содержимое таблиц фиксируется в журнале транзакций во время выполнения операции контрольная точка.
Операция контрольная точка выполняется каждые 5 секунд и включает выполнение следующих действий (рис. 8.10). Сначала в области протоколирования журнала транзакций создаются две записи — запись таблицы незавершенных транзакций и запись таблицы модифицированных страниц, содержащие копии соответствующих таблиц. Затем номера этих записей включаются в запись контрольной точки, которая также создается в области протоколирования журнала транзакций. Сделав запись контрольной точки, NTFS помещает ее номер LSN в область рестарта.
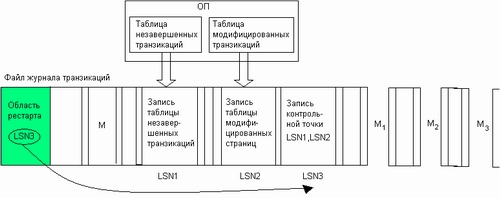
Рис. 8.10. Записи операции контрольная точка
Заметим, что процессы создания контрольных точек и сброса блоков данных из кэша на диск протекают асинхронно. Когда в результате сбоя из оперативной памяти исчезает вся информация, в том числе из таблиц незавершенных транзакций и модифицированных страниц, состояние этих таблиц, хотя и несколько устаревшее, сохраняется на диске в файле журнала транзакций. Кроме того, здесь же имеется несколько более поздних записей, которые были сделаны в период между сохранением таблиц и сбросом кэша (на рисунке это записи Ml, M2, МЗ). При восстановлении файловая система обрабатывает эти записи и вносит изменения в таблицы незавершенных транзакций и модифицированных страниц, сохраненные в журнале. Так, например, если запись Ml является записью фиксации транзакции, то соответствующая транзакция исключается из таблицы незавершенных транзакций, а если это запись модификации, то в таблицу модифицированных страниц заносится информация об еще одной странице.
Процесс восстановления файловой системы включает следующие шаги:
1. Чтение области рестарта из файла журнала транзакций и определение номера самой последней по времени записи о контрольной точке.
2. Чтение записи контрольной точки и определение номеров записей таблицы незавершенных транзакций и таблицы модифицированных страниц.
3. Чтение и корректировка таблиц незавершенных транзакций и модифицированных страниц на основании записей, сделанных в журнале транзакций уже после сохранения таблиц в журнале, но еще до записи журнала на диск (рис. 8.11).
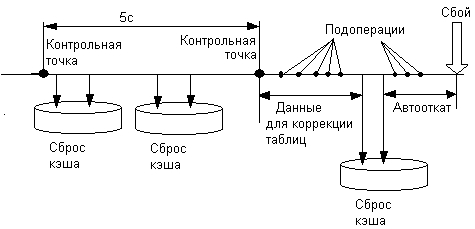
Рис. 8.11. Асинхронность процессов сброса кэша и создания контрольных точек
4. Анализ таблицы модифицированных страниц, определение номера самой ранней записи модификации страницы.
5. Чтение журнала транзакций в прямом направлении, начиная с самой ранней записи модификации, найденной при анализе таблицы модифицированных страниц. При этом система выполняет повторение завершенных транзакций, в результате которого устраняются все несоответствия файловой системы, вызванные потерями модифицированных страниц в кэше во время сбоя или краха операционной системы.
6. Анализ таблицы незавершенных транзакций, определение номера самой поздней подоперации, выполненной в рамках незавершенной транзакции.
7. Чтение журнала транзакций в обратном направлении. Учитывая, что все подоперации каждой транзакции связаны в список, система легко переходит от одной записи модификации к другой, извлекает из них информацию, необходимую для отмены, и выполняет откат незавершенных транзакций.
Операция отмены сама является транзакцией, поскольку связана с модификацией системных блоков файловой системы — поэтому она протоколируется обычным образом в журнале транзакций. По отношению к ней также могут быть применены операции повторения или отката.
Избыточные дисковые подсистемы RAID
В основе средств обеспечения отказоустойчивости дисковой памяти лежит общий для всех отказоустойчивых систем принцип избыточности, и дисковые подсистемы RAID (Redundant Array of Inexpensive Disks, дословно — «избыточный массив недорогих дисков») являются примером реализации этого принципа. Идея технологии RAID-массивов состоит в том, что для хранения данных используется несколько дисков, даже в тех случаях, когда для таких данных хватило бы места на одном диске. Организация совместной работы нескольких централизованно управляемых дисков позволяет придать их совокупности новые свойства, отсутствовавшие у каждого диска в отдельности.
RAID-массив может быть создан на базе нескольких обычных дисковых устройств, управляемых обычными контроллерами, в этом случае для организации управления всей совокупностью дисков в операционной системе должен быть установлен специальный драйвер. В Windows NT, например, таким драйвером является FtDisk — драйвер отказоустойчивой дисковой подсистемы. Существуют также различные модели дисковых систем, в которых технология RAID реализуется полностью аппаратными средствами, в этом случае массив дисков управляется общим специальным контроллером.
Дисковый массив RAID представляется для пользователей и прикладных программ единым логическим диском. Такое логическое устройство может обладать различными качествами в зависимости от стратегии, заложенной в алгоритмы работы средств централизованного управления и размещения информации на всей совокупности дисков. Это логическое устройство может, например, обладать повышенной отказоустойчивостью или иметь производительность, значительно большую, чем у отдельно взятого диска, либо обладать обоими этими свойствами. Различают несколько вариантов RAID-массивов, называемых также уровнями: RAID-0, RAID-1, RAID-2, RAID-3, RAID-4, RAID-5 и некоторые другие.
При оценке эффективности RAID-массивов чаще всего используются следующие критерии:
- степень избыточности хранимой информации (или тесно связанная с этим критерием стоимость хранения единицы информации);
- производительность операций чтения и записи;
- степень отказоустойчивости.
В логическом устройстве RAID-0 (рис. 8.12) общий для дискового массива контроллер при выполнении операции записи расщепляет данные на блоки и передает их параллельно на все диски, при этом первый блок данных записывается на первый диск, второй — на второй и т. д. Различные варианты реализации технологии RAID-0 могут отличаться размерами блоков данных, например в наборах с чередованием, представляющих собой программную реализацию RAID-0 в Windows NT, на диски поочередно записываются полосы данных (strips) по 64 Кбайт. При чтении контроллер мультиплексирует блоки данных, поступающие со всех дисков, и передает их источнику запроса.

Рис. 8.12. Организация массива RAID-0
По сравнению с одиночным диском, в котором данные записываются и считываются с диска последовательно, производительность дисковой конфигурации RAID-0 значительно выше за счет одновременности операций записи/чтения по всем дискам массива.
Уровень RAID-0 не обладает избыточностью данных, а значит, не имеет возможности повысить отказоустойчивость. Если при считывании произойдет сбой, то данные будут безвозвратно испорчены. Более того, отказоустойчивость даже снижается, поскольку если один из дисков выйдет из строя, то восстанавливать придется все диски массива. Имеется еще один недостаток — если при работе с RAID-0 объем памяти логического устройства потребуется изменить, то сделать это путем простого добавления еще одного диска к уже имеющимся в RAID-массиве дискам невозможно без полного перераспределения информации по всему изменившемуся набору дисков.
Уровень RAID-1 (рис. 8.13) реализует подход, называемый зеркальным копированием (mirroring). Логическое устройство в этом случае образуется на основе одной или нескольких пар дисков, в которых один диск является основным, а другой диск (зеркальный) дублирует информацию, находящуюся на основном диске. Если основной диск выходит из строя, зеркальный продолжает сохранять данные, тем самым обеспечивается повышенная отказоустойчивость логического устройства. За это приходится платить избыточностью — все данные хранятся на логическом устройстве RAID-1 в двух экземплярах, в результате дисковое пространство используется лишь на 50 %.

Рис. 8.13. Организация массива RAID-1
При внесении изменений в данные, расположенные на логическом устройстве RAID-1, контроллер (или драйвер) массива дисков одинаковым образом модифицирует и основной, и зеркальный диски, при этом дублирование операций абсолютно прозрачно для пользователя и приложений. Удвоение количества операций записи снижает, хотя и не очень значительно, производительность дисковой подсистемы, поэтому во многих случаях наряду с дублированием дисков дублируются и их контроллеры. Такое дублирование (duplexing) помимо повышения скорости операций записи обеспечивает большую надежность системы — данные на зеркальном диске останутся доступными не только при сбое диска, но и в случае сбоя дискового контроллера.
Некоторые современные контроллеры (например, SCSI-контроллеры) обладают способностью ускорять выполнение операций чтения с дисков, связанных в зеркальный набор. При высокой интенсивности ввода-вывода контроллер распределяет нагрузку между двумя дисками так, что две операции чтения могут быть выполнены одновременно. В результате распараллеливания работы по считыванию данных между двумя дисками время выполнения операции чтения может быть снижено в два раза! Таким образом, некоторое снижение производительности, возникающее при выполнении операций записи, с лихвой компенсируется повышением скорости выполнения операций чтения.
Уровень RAID-2 расщепляет данные побитно: первый бит записывается на первый диск, второй бит — на второй диск и т. д. Отказоустойчивость реализуется в RAID-2 путем использования для кодирования данных корректирующего кода Хэмминга, который обеспечивает исправление однократных ошибок и обнаружение двукратных ошибок. Избыточность обеспечивается за счет нескольких дополнительных дисков, куда записывается код коррекции ошибок. Так, массив с числом основных дисков от 16 до 32 должен иметь три дополнительных диска для хранения кода коррекции. RAID-2 обеспечивает высокую производительность и надежность, но он применяется в основном в мэйнфреймах и суперкомпьютерах. В сетевых файловых серверах этот метод в настоящее время практически не используется из-за высокой стоимости его реализации.
В массивах RAID-3 используется расщепление (stripping) данных на массиве дисков с выделением одного диска на весь набор для контроля четности. То есть если имеется массив из N дисков, то запись на N-1 из них производится параллельно с побайтным расщеплением, а N-й диск используется для записи контрольной информации о четности. Диск четности является резервным. Если какой-либо диск выходит из строя, то данные остальных дисков плюс данные о четности резервного диска позволяют не только определить, какой из дисководов массива вышел из строя, но и восстановить утраченную информацию. Это восстановление может выполняться динамически, по мере поступления запросов, или в результате выполнения специальной процедуры восстановления, когда содержимое отказавшего диска заново генерируется и записывается на резервный диск.
Рассмотрим пример динамического восстановления данных. Пусть массив RAID-3 состоит из четырех дисков: три из них — ДИСК 1, ДИСК 2 и ДИСК 3 — хранят данные, а ДИСК 4 хранит контрольную сумму по модулю 2 (XOR). И пусть на логическое устройство, образованное этими дисками, записывается последовательность байт, каждый из которых имеет значение, равное его порядковому номеру в последовательности. Тогда первый байт 0000 0001 попадет на ДИСК 1, второй, байт 0000 0010 - на ДИСК 2, а третий по порядку байт - на ДИСК 3. На четвертый диск будет записана сумма по модулю 2, равная в данном случае 0000 0000 (рис. 8.14). Вторая строка таблицы, приведенной на рисунке, соответствует следующим трем байтам и их контрольной сумме и т. д. Представим, что ДИСК 2 вышел из строя.

Рис. 8.14. Пример распределения данных по дискам массива RAID-3
При поступлении запроса на чтение, например, пятого байта (он выделен жирным шрифтом) контроллер дискового массива считывает данные, относящиеся к этой строке со всех трех оставшихся дисков — байты 0000 0100, 0000 ОНО, 0000 0111 — и вычисляет для них сумму по модулю 2. Значение контрольной суммы 0000 0101 и будет являться восстановленным значением потерянного из-за неисправности пятого байта.
Если же требуется записать данные на отказавший диск, то эта операция физически не выполняется, вместо этого корректируется контрольная сумма — она получает такое значение, как если бы данные были действительно записаны на этот диск.
Однако динамическое восстановление данных снижает производительность дисковой подсистемы. Для полного восстановления исходного уровня производительности необходимо заменить вышедший из строя диск и провести регенерацию всех данных, которые хранились на отказавшем диске.
Минимальное количество дисков, необходимое для создания конфигурации RAID-3, равно трем. В этом случае избыточность достигает максимального значения — 33 %. При увеличении числа дисков степень избыточности снижается, так, для 33 дисков она составляет менее 1 %.
Уровень RAID-3 позволяет выполнять одновременное чтение или запись данных на несколько дисков для файлов с длинными записями, однако следует подчеркнуть, что в каждый момент выполняется только один запрос на ввод-вывод, то есть RAID-3 позволяет распараллеливать ввод-вывод в рамках только одного процесса (рис. 8.15). Таким образом, уровень RAID-3 повышает как надежность, так и скорость обмена информацией.

Рис. 8.15. Организация массива RAID-3
Организация RAID-4 аналогична RAID-3, за тем исключением, что данные распределяются на дисках не побайтно, а блоками. За счет этого может происходить независимый обмен с каждым диском. Для хранения контрольной информации также используется один дополнительный диск. Эта реализация удобна для файлов с очень короткими записями и большей частотой операций чтения по сравнению с операциями записи, поскольку в этом случае при подходящем размере блоков диска возможно одновременное выполнение нескольких операций чтения.
Однако по-прежнему допустима только одна операция записи в каждый момент времени, так как все операции записи используют один и тот же дополнительный диск для вычисления контрольной суммы. Действительно, информация о четности должна корректироваться каждый раз, когда выполняется операция записи. Контроллер должен сначала считать старые данные и старую контрольную информацию, а затем, объединив их с новыми данными, вычислить новое значение контрольной суммы и записать его на диск, предназначенный для хранения контрольной информации. Если требуется выполнить запись в более чем один блок, то возникает конфликт по обращению к диску с контрольной информацией. Все это приводит к тому, что скорость выполнения операций записи в массиве RAID-4 снижается.
В уровне RAID-5 (рис. 8.16) используется метод, аналогичный RAID-4, но данные о контроле четности распределяются по всем дискам массива. При выполнении операции записи требуется в три раза больше оперативной памяти. Каждая команда записи инициирует ту же последовательность «считывание—модификация—запись» в нескольких дисках, как и в методе RAID-4. Наибольший выигрыш в производительности достигается при операциях чтения. Поскольку информация о четности может быть считана и записана на несколько дисков одновременно, скорость записи по сравнению с уровнем RAID-4 увеличивается, однако она все еще гораздо ниже скорости отдельного диска метода RAID-1 или RAID-3.
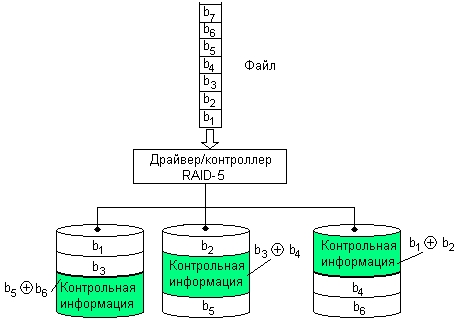
Рис. 8.16. Организация массива RAID-5
Кроме рассмотренных выше имеются еще и другие варианты организации совместной работы избыточного набора дисков, среди них можно особо отметить технологию RAID-10, которая представляет собой комбинированный способ, при котором данные «расщепляются» (RAID-0) и зеркально копируются (RAID-1) без вычисления контрольных сумм. Обычно две пары «зеркальных» массивов объединяются и образуют один массив RAID-0. Этот способ целесообразно применять при работе с большими файлами.
В табл. 8.2 сведены основные характеристики для некоторых конфигураций избыточных дисковых массивов.
Таблица 8.2. Характеристики уровней RAID
| Конфигу- рация RAID | Избы- точность | Отказо- устойчивость | Скорость чтения | Скорость записи |
| RAID-0 | Нет | Нет | Повышен- ная | Повышен- ная |
| RAID RAID-1 | 50% | Есть | Повышен- ная | Пониженная (в варианте без дуплекси- рования) |
| RAID-3, RAID-4, RAID-5 | До 33% | Есть | Повышен- ная | Пониженная (в разной степени) |
| RAID-10 | 50% | Есть | Повышен- ная | Повышен- ная |
Обмен данными между процессами и потоками
Если абстрагироваться от вопросов синхронизации, то обмен данными между потоками одного процесса не представляет никакой сложности — имея общее адресное пространство и общие открытые файлы, потоки получают беспрепятственный доступ к данным друг друга. Другое дело — обмен данными потоков, выполняющихся в рамках разных процессов. Для защиты процессов друг от друга ОС возводит мощные изолирующие преграды, которые не только защищают процессы, но и не позволяют им передавать друг другу данные. Потоки разных процессов работают в разных адресных пространствах. Однако операционная система имеет доступ ко всем областям памяти, поэтому она может играть роль посредника в информационном обмене прикладных потоков. При возникновении необходимости в обмене данными поток обращается с запросом к ОС. По этому запросу ОС, пользуясь своими привилегиями, создает различные системные средства связи, такие, например, как конвейеры или очереди сообщений.
Эти средства, так же как и рассмотренные выше средства синхронизации процессов, относятся к классу средств межпроцессного взаимодействия, то есть IPC (Inter-Process Communications).
Многие из средств межпроцессного обмена данными выполняют также и функции синхронизации: в том случае, когда данные для процесса-получателя отсутствуют, последний переводится в состояние ожидания средствами ОС, а при поступлении данных от процесса-отправителя процесс-получатель активизируется.
Набор средств межпроцессного обмена данными в большинстве современных ОС выглядит следующим образом:
- конвейеры (pipes); rj именованные конвейеры (named pipes);
- очереди сообщений (message queues);
- разделяемая память (shared memory).
Кроме этого достаточно стандартного набора средств в конкретных ОС часто имеются и более специфические средства межпроцессного обмена, например средства среды STREAMS для различных версий UNIX или почтовые ящики (mail slots) в ОС Windows.
Конвейеры
Конвейеры как средство межпроцессного обмена данными впервые появились в операционной системе UNIX. Системный вызов pipe позволяет двум процессам обмениваться неструктурированным потоком байт. Конвейер представляет собой буфер в оперативной памяти, поддерживающий очередь байт по алгоритму FIFO. Для программиста, использующего системный вызов pipe, этот буфер выглядит как безымянный файл, в который можно писать и читать, осуществляя тем самым обмен данными.
Системный вызов pipe имеет одно существенное ограничение — обмениваться данными могут только родственные процессы, точнее, процессы, которые имеют общего прародителя, создавшего данный конвейер. Если операционная система поддерживает потоки, то это же ограничение будет означать, что конвейером могут воспользоваться только потоки, относящиеся к такого рода процессам. Ограничение проистекает из-за того, что конвейер такого типа не имеет имени, а обращение к нему происходит по дескриптору файла, который, как это было сказано выше, имеет локальное для каждого процесса значение.
При выполнении системного вызова pipe в процесс возвращаются два дескриптора файла, один для записи данных в конвейер, а другой для чтения данных из конвейера. Обычно для выполнения некоторой общей работы ведущий процесс сначала создает конвейер, а затем — несколько процессов-потомков с помощью соответствующего системного вызова. В результате механизм наследования процессов копирует для всех процессов-потомков значения дескрипторов, указывающих на один и тот же конвейер, так что все кооперирующиеся процессы, включая процесс-прародитель, могут использовать этот конвейер для обмена данными. Данные читаются из конвейера с помощью системного вызова read с использованием первого из возвращенных вызовом pipe дескрипторов файла, а записываются в конвейер с помощью системного вызова write с использованием второго дескриптора. Синтаксис системных вызовов read и write тот же, что и при работе с обычными файлами.
Конвейер обеспечивает автоматическую синхронизацию процессов — если при использовании системного вызова read в буфере конвейера нет данных, то процесс, обратившийся к ОС с системным вызовом read, переводится в состояние ожидания и активизируется при появлении данных в буфере.
Механизм конвейеров доступен не только программистам, но и пользователям большинства современных операционных систем. Именно системные вызовы pipe используются оболочкой (командным процессором) операционной системы для организации конвейера команд, когда выходные данные одной команды пользователя становятся входными данными для другой команды. Примером такого конвейера команд может служить показанная ниже строка командного интерпретатора shell ОС UNIX, которая передает выходные данные команды Is (чтение списка имен файлов текущего каталога) на вход команды we (подсчет слов) с ключом -1:
ls | wc -1
Результатом работы этой командной строки будет количество файлов в текущем каталоге.
Именованные конвейеры
Именованные конвейеры представляют собой развитие механизма обычных конвейеров. Такие конвейеры имеют имя, которое является записью в каталоге файловой системы ОС, поэтому они пригодны для обмена данными между двумя произвольными процессами или потоками этих процессов.
Именованный конвейер является специальным файлом типа FIFO и не имеет области данных на диске. Создается именованный конвейер с помощью того же системного вызова, который используется и для создания файлов любого типа, но только с указанием в качестве типа файла параметра FIFO. Системный вызов порождает в каталоге запись о файле типа FIFO с заданным именем, после чего любой процесс может открыть этот файл и передавать данные другому процессу, также открывшему файл с этим именем.
Ввиду того что именованные конвейеры основаны на файловой системе, обычные конвейеры, создаваемые системным вызовом pipe, иногда называют программными конвейерами (software-pipes). Следует иметь в виду, что именованные конвейеры используют файловую систему только для хранения имени конвейера в каталоге, а данные между процессами передаются через буфер в оперативной памяти, как и в случае программного конвейера.
Очереди сообщений
Механизм очередей сообщений похож на механизм конвейеров с тем отличием, что он позволяет процессам и потокам обмениваться структурированными сообщениями. При этом синхронизация осуществляется по сообщениям, то есть процесс, пытающийся прочитать сообщение, переводится в состояние ожидания в том случае, если в очереди нет ни одного полного сообщения. Очереди сообщений являются глобальными средствами коммуникаций для процессов операционной системы, как и именованные конвейеры, так как каждая очередь имеет в пределах ОС уникальное имя. В ОС UNIX в качестве такого имени используется числовое значение — так называемый ключ. Ключ является числовым аналогом имени файла, при использовании одного и того же значения ключа процессы будут работать с одной и той же очередью сообщений. Существует также функция, которая преобразует произвольное символьное имя в значение ключа, что позволяет программисту использовать для указания уникальных очередей имена вместо трудно запоминаемых чисел.
Для работы с очередью сообщений процесс должен воспользоваться системным вызовом msgget, указав в качестве параметра значение ключа. Если очередь с данным ключом в настоящий момент не используется ни одним процессом, то для нее резервируется область памяти, а затем процессу возвращается идентификатор очереди, который, как и дескриптор файла, имеет локальное для процесса значение. Если же очередь уже используется, то процессу просто возвращается ее идентификатор. Системный администратор может управлять настройками операционной системы для изменения максимального объема памяти, отводимой очереди, а также максимального размера сообщения.
После открытия очереди процесс может помещать в него сообщения с помощью вызова msgsnd или читать сообщения с помощью вызова msgrsv. Программист может влиять на то, как ОС будет обрабатывать ситуацию, когда процесс пытается читать сообщения, которые еще не поступили в очередь, то есть на синхронизацию процесса с данными. При задании в системных вызовах msgsnd и msgrcv параметра IPC_NOWAIT операционная система в любом случае будет возвращать управление в вызывающий процесс, даже если он пытается прочитать несуществующее сообщение (в последнем случае в процесс возвращается код ошибки). Без этого параметра процесс при отсутствии данных переводится в состояние ожидания. Параметр IPC_NOWAIT используется не только в очередях сообщений, но и в некоторых других средствах IPC, например в семафорах. При использовании параметра IPC_NOWAIT программист должен самостоятельно организовать ожидание данных.
Разделяемая память
Разделяемая память представляет собой сегмент физической памяти, отображенной в виртуальное адресное пространство двух или более процессов. Механизм разделяемой памяти поддерживается подсистемой виртуальной памяти, которая настраивает таблицы отображения адресов для процессов, запросивших разделение памяти, так что одни и те же адреса некоторой области физической памяти соответствуют виртуальным адресам разных процессов.
Выводы
- Механизм специальных файлов дает упрощенное представление устройства в виде неструктурированного набора байт. Эта модель может непосредственно использоваться при работе с символьными устройствами или служить универсальной основой для построения более сложной логической модели устройств других типов.
- В подсистеме ввода-вывода каждой современной операционной системы существуют стандарты на структуру драйверов и способ взаимодействия драйверов с приложениями и остальными модулями ОС, а также друг с другом. Наличие таких стандартов упрощает разработку новых драйверов независимыми производителями и повышает стабильность ОС.
- Стандарт на структуру драйвера определяет состав и назначение основных процедур драйвера, таких как процедура инициализации, процедура старта операции, процедуры чтения и записи данных, процедура обработки прерываний и процедура завершения операции.
- Процедура обработки прерываний драйвера работает в общем случае в контексте процесса, отличающегося от того, для которого выполняется операция, поэтому ей запрещается пользоваться ресурсами текущего процесса или влиять на их распределение.
- Механизм отображаемых в память файлов является удобным для программиста средством доступа к файлам, при котором обращение к данным файла осуществляется тем же способом, что и к переменным, находящимся в оперативной памяти. Большую часть работы по отображению файлов в память выполняют стандартные модули подсистемы виртуальной памяти ОС, поэтому данный механизм очень экономичен в отношении реализации.
- Для ускорения обмена данными с дисковыми накопителями в операционных системах используется дисковый кэш, который располагается между слоем драйверов файловых систем и блок-ориентированными драйверами дисков.
- Негативным последствием кэширования диска может быть потеря при сбое системы или отключении питания той части кэшируемых данных, которая не успела переписаться на диск. Для борьбы с этим явлением периодически осуществляется принудительное выталкивание данных кэша на диск, а также используются восстанавливаемые файловые системы.
- Для организации дискового кэша в большинстве современных ОС используется отображение с помощью подсистемы виртуальной памяти частей файлов, к которым происходит обращение, в системную область памяти.
- Восстанавливаемость файловой системы — это свойство, которое гарантирует, что в случае отказа питания или краха системы, когда все данные в оперативной памяти безвозвратно теряются, все начатые файловые операции будут либо успешно завершены, либо отменены без всяких отрицательных последствий для работоспособности файловой системы. Это означает, что операции с диском рассматриваются как транзакции, которые протоколируются в специальном журнале.
- Свойство восстанавливаемости может распространяться на данные двух типов: пользовательские данные и служебную информацию файловой системы. В некоторых файловых системах, например NTFS, поддерживается только восстанавливаемость служебной информации, что обеспечивает работоспособность и непротиворечивость файловой системы после сбоев, но не гарантирует полной сохранности данных в файлах пользователей.
- Для обеспечения устойчивости хранимых данных к отказам самих дисков в вычислительных системах применяются избыточные дисковые массивы, известные под названием RAID. При отказе одного из дисков для восстановления его данных используются данные, хранящиеся на оставшихся дисках массива.
- Существует несколько уровней RAID (наиболее часто применяемые — RAID-0, RAID-1, RAID-3 и RAID-5), отличающихся степенью избыточности хранимой информации, производительностью операций чтения и записи, а также степенью отказоустойчивости.
- В операционных системах существуют специальные средства межпроцессного обмена, которые позволяют преодолеть защитные барьеры, разделяющие адресные пространства различных процессов. К этим средствам относятся простые и именованные конвейеры, очереди сообщений, разделяемые сегменты памяти и ряд других механизмов.
Задачи и упражнения
1. На какой стадии операция записи данных в специальный файл начинает отличаться от операций записи в дисковый файл в ОС UNIX?
2. Если при поступлении запроса от приложения к файлу система обнаруживает требуемые данные в системном буфере (кэше), то время доступа приложения к нужным ему данным будет:
- А) таким же, как время доступа к его внутренним переменным;
- В) немного больше, чем время доступа к его внутренним переменным;
- С) таким же, как время доступа к данным на диске.
3. Какая секция блок-ориентированного драйвера ОС UNIX выполняет вывод данных?
4. Какие преимущества связаны с включением в модель драйвера большого количества секций различного типа?
5. Чем функции секции nodev драйвера ОС UNIX отличаются от функций секции nulIdev?
6. Чем принципиально отличается отображение файла в память от кэширования файла с помощью средств менеджера виртуальной памяти?
7. Все ли типы файлов можно отображать в память в ОС UNIX?
8. В каких ситуациях целесообразно использовать асинхронные операции записи в файл?
9. Какие дополнительные меры должны предприниматься при восстановлении файловой системы при наличии дискового кэша?
10. Какие параметры операции с файлом фиксируются в журнале транзакций?
11. Восстанавливаются ли пользовательские данные в NTFS?
12. Из каких двух частей состоит запись о модификации в журнале транзакций Windows NT?
13. Можно ли организовать дисковый массив RAID без специального контроллера?
14. В чем преимущество дисковых массивов RAID-0 по сравнению с обычными дисками?
15. Скорость какого типа операций повышается при использовании дисковых массивов RAID-1?
16. Что такое «динамическое восстановление данных»?
17. В каких случаях обмен данными между процессами можно выполнить только с помощью именованных конвейеров?
ГЛАВА 9
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 2394; Нарушение авторских прав?; Мы поможем в написании вашей работы!