КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Типы данных. Опции компоновщика (редактора связей) TLINK
|
|
|
|
Опции компоновщика (редактора связей) TLINK
Опции транслятора TASM
Трансляция текстов программ
В процессе своей работы транслятор TASM формирует два типа ошибок: сообщения о неправильных или некорректных конструкциях в исходном ассемблерном тексте и сообщения о фатальных ошибках. Особенность последних в том, что при их возникновении TASM выдает соответствующее сообщение и немедленно прекращает ассемблирование исходного файла.
| /h, /? | Вывод на экран справочной информации. Это эквивалентно запуску TASM без параметров |
| /x | Включить в листинг все блоки условного ассемблирования для директив IF, IFNDEF, IFDEF и т. п., в том числе и невыполняющиеся |
| /z | При возникновении ошибок наряду с сообщением о них выводить соответствующие строки текста |
| /zi, /zd, /zn | /zi — включить в объектный файл информацию для отладки; /zd — поместить в объектный файл информацию о номерах строк, что необходимо для работы отладчика на уровне исходного текста программы; /zn — запретить помещение в объектный файл отладочной информации. |
| /x | Не создавать файл карты (map) |
| /m | Создать файл карты |
| /c | Различать строчные и прописные буквы в идентификаторах (в том числе и внешних) |
| /v | Включить отладочную информацию в выполняемый файл |
| /3 | Поддержка 32-битного кода |
| /t | Создать файл типа.com (по умолчанию.exe) |
При программировании на языке ассемблера используются данные следующих типов:
- Непосредственные данные, представляющие собой числовые или символьные значения, являющиеся частью команды, формируются в процессе написания программы для конкретной команды ассемблера.
- Данные простого типа, описываются с помощью ограниченного набора директив резервирования памяти, позволяют выполнить самые элементарные операции по размещению и инициализации числовой и символьной информации. При обработке этих директив ассемблер сохраняет в своей таблице символов информацию о местоположении данных (значения сегментной составляющей адреса и смещения) и типе данных, то есть единицах памяти, выделяемых для размещения данных в соответствии с директивой резервирования и инициализации данных.
Эти два типа данных являются элементарными, или базовыми; работа с ними поддерживается на уровне системы команд микропроцессора. Используя данные этих типов, можно формализовать и запрограммировать практически любую задачу.
С точки зрения размерности, микропроцессор аппаратно поддерживает следующие основные типы данных:
- байт — восемь последовательно расположенных битов, пронумерованных от 0 до 7, при этом бит 0 является самым младшим значащим битом;
- слово — последовательность из двух байт, имеющих последовательные адреса. Размер слова — 16 бит; биты в слове нумеруются от 0 до 15. Байт, содержащий нулевой бит, называется младшим байтом, а байт, содержащий 15-й бит - старшим байтом. Микропроцессоры Intel имеют важную особенность — младший байт всегда хранится по меньшему адресу. Адресом слова считается адрес его младшего байта. Адрес старшего байта может быть использован для доступа к старшей половине слова.
- двойное слово — последовательность из четырех байт (32 бита), расположенных по последовательным адресам. Нумерация этих бит производится от 0 до 31. Слово, содержащее нулевой бит, называется младшим словом, а слово, содержащее 31-й бит, - старшим словом. Младшее слово хранится по меньшему адресу. Адресом двойного слова считается адрес его младшего слова. Адрес старшего слова может быть использован для доступа к старшей половине двойного слова.
- учетверенное слово — последовательность из восьми байт (64 бита), расположенных по последовательным адресам. Нумерация бит производится от 0 до 63. Двойное слово, содержащее нулевой бит, называется младшим двойным словом, а двойное слово, содержащее 63-й бит, — старшим двойным словом. Младшее двойное слово хранится по меньшему адресу. Адресом учетверенного слова считается адрес его младшего двойного слова. Адрес старшего двойного слова может быть использован для доступа к старшей половине учетверенного слова.
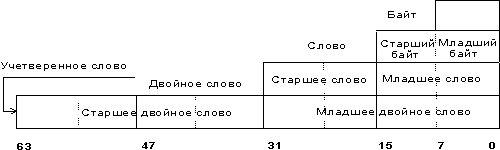
Рис. 1. Основные типы данных микропроцессора
Кроме трактовки типов данных с точки зрения их разрядности, микропроцессор на уровне команд поддерживает логическую интерпретацию этих типов:
- Целый тип со знаком — двоичное значение со знаком, размером 8, 16 или 32 бита. Знак в этом двоичном числе содержится в 7, 15 или 31-м бите соответственно. Ноль в этих битах в операндах соответствует положительному числу, а единица — отрицательному. Отрицательные числа представляются в дополнительном коде. Числовые диапазоны для этого типа данных следующие:
- 8-разрядное целое — от –128 до +127;
- 16-разрядное целое — от –32 768 до +32 767;
- 32-разрядное целое — от –231 до +231–1.
- Целый тип без знака — двоичное значение без знака, размером 8, 16 или 32 бита. Числовой диапазон для этого типа следующий:
- байт — от 0 до 255;
- слово — от 0 до 65 535;
- двойное слово — от 0 до 232 –1.
- Указатель на память двух типов:
- ближнего типа — 32-разрядный логический адрес, представляющий собой относительное смещение в байтах от начала сегмента. Эти указатели могут также использоваться в сплошной (плоской) модели памяти, где сегментные составляющие одинаковы;
- дальнего типа — 48-разрядный логический адрес, состоящий из двух частей: 16-разрядной сегментной части — селектора, и 32-разрядного смещения.
- Цепочка — представляющая собой некоторый непрерывный набор байтов, слов или двойных слов максимальной длины до 4 Гбайт.
- Битовое поле представляет собой непрерывную последовательность бит, в которой каждый бит является независимым и может рассматриваться как отдельная переменная. Битовое поле может начинаться с любого бита любого байта и содержать до 32 бит.
- Неупакованный двоично-десятичный тип — байтовое представление десятичной цифры от 0 до 9. Неупакованные десятичные числа хранятся как байтовые значения без знака по одной цифре в каждом байте. Значение цифры определяется младшим полубайтом.
- Упакованный двоично-десятичный тип представляет собой упакованное представление двух десятичных цифр от 0 до 9 в одном байте. Каждая цифра хранится в своем полубайте. Цифра в старшем полубайте (биты 4–7) является старшей.
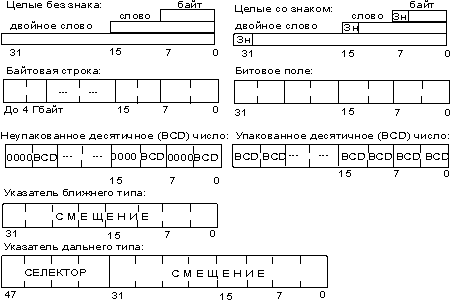
Рис. 2. Основные логические типы данных микропроцессора.
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 746; Нарушение авторских прав?; Мы поможем в написании вашей работы!