КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Особенности использования БД
|
|
|
|
Ø Данные в БД создаются и хранятся как единое целое для решения всех задач предметной области, то есть отпадает необходимость дублирования данных (экономия памяти компьютера);
Ø каждая прикладная программа выбирает из БД данные для решения только своей задачи;
Ø независимость прикладных программ от данных (изменения в данных не вызывают необходимость изменения программы, и наоборот).
Схема 2. Основные возможности СУБД
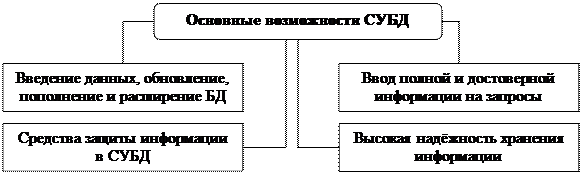
Основной составной частью СУБД является ее ядро — управляющая программа для автоматизации всех процессов, связанных с обращением к базам данных. После запуска СУБД ее ядро постоянно находится в основной памяти и организует обработку данных, управляет очередностью выполнения операций, взаимодействует с прикладным программным обеспечением и операционной системой, контролирует завершение операций доступа к БД. Важнейшей функцией ядра является организация параллельного выполнения запросов.
По способу доступа к данным БД различают системы файл — сервер и клиент — сервер.
В системе файл — сервер одна из вычислительных машин служит хранилищем централизованной базы данных, а доступ к базе осуществляется с других машин, которые носят название рабочих станций. Файлы базы данных передаются на рабочие станции, где и производится их обработка.
Для этой архитектуры характерен коллективный доступ к общей базе данных на файловом сервере. Запрошенные данные транспортируются с файлового сервера на рабочие станции, где их обработка выполняется средствами СУБД.
В системе клиент — сервер кроме хранения базы данных на центральную машину ложатся и функции обработки данных, а на клиентских машинах выполняется только представление информации. Запрос на обработку данных выдается клиентом и передается по сети на сервер баз данных, где осуществляется поиск. Обработанные данные транспортируются по сети от сервера к клиенту.
Структурированное представление данных называется моделью данных.
Информационно-логическая (инфологическая) модель является логическим представлением взаимосвязей объектов базы данных. Известны три разновидности инфологических моделей:
Ø иерархическая,
Ø сетевая
Ø реляционная.
Иерархическая модель данных основана на графическом способе связей данных, и схема взаимосвязей объектов имеет вид перевернутого дерева. Каждому элементу соответствует только одна связь от элемента более высокого уровня. Поиск данных происходит по одной из ветвей дерева.
 Это интересно
Это интересно
Одной из наиболее популярных иерархических СУБД была Information Management System (IMS) фирмы IBM, появившаяся в 1968 г. Она использовалась на больших ЭВМ компании IBM.
Достоинства СУБД иерархической модели — простота, быстродействие. Правда, если структура данных оказывалась сложнее, чем обычная иерархия, то простота структуры иерархической базы становилась ее недостатком.
В связи с этим для таких задач, как обработка заказов, была разработана новая сетевая модель данных. Она стала улучшенной: иерархической моделью.
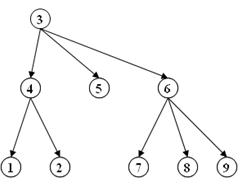
Рис.1. Иерархическая модель данных
В сетевой модели данных каждый элемент может иметь более одного порождающего элемента, а графическое представление модели очень напоминает сеть. Она допускает усложнение «дерева» без ограничения количества связей, входящих в его вершину!
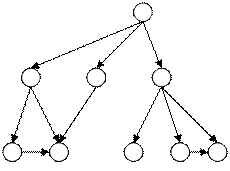
Рис. 2. Сетевая модель данных
Это интересно
В 1971 г. на конференции по языкам систем данных был опубликован официальный стандарт сетевых баз данных, который известен как модель CODASYL. В 70-х гг. независимые производители программного обеспечения реализовали сетевую модель в таких программных продуктах, как IDMS компании Cullinet, Total компании Cincom и СУБД Adabas, которые были в свое время очень популярны.
К достоинствам сетевых баз данных можно отнести гибкость, стандартизацию и быстродействие.
Но и иерархические, и сетевые базы данных были очень жесткими, наборы отношений и структуру записей приходилось задавать наперед, а изменение структуры базы данных обычно означало перестройку всей базы. Ко всему прочему, они были инструментами программистов. Чтобы получить ответ на вопрос типа: «Какой товар наиболее часто заказывает компания XX?», программисту приходилось писать программу для навигации по базе данных. Реализация пользовательских запросов часто затягивалась на недели и месяцы, и к моменту появления запрошенной информации она часто уже оказывалась бесполезной.
Недостатки иерархической и сетевой моделей привели к появлению новой реляционной модели, созданной Коддом в 1970 г. и вызвавшей всеобщий интерес. Реляционная модель была попыткой упростить структуру базы данных, и теперь все данные представлялись в виде простых таблиц, разбитых на строки и столбцы.
В 1985 г. Кодд написал статью, где сформулировал двенадцать правил, которым должна удовлетворять любая база данных, претендующая на звание реляционной. С тех пор двенадцать правил Кодда считаются определением реляционной СУБД.
Можно сформулировать более простое определение.
Реляционной называется база данных, в которой все данные, доступные пользователю, организованы в виде таблиц, а все операции над данными сводятся к операциям над этими таблицами.
В реляционной базе данных информация организована в виде таблиц, разделенных на строки и столбцы, на пересечении которых содержатся значения данных. У каждой таблицы имеется свое уникальное имя, описывающее ее содержание.
Строки реляционной таблицы являются записями и хранят информацию об одном экземпляре объекта данных, представленного в таблице. Одинаковых записей в таблице не должно быть. Основное требование к реляционной базе данных состоит в том, что значения полей (столбцов таблицы) должны быть элементарными и неделимыми информационными единицами, что создает возможность применять в целях обработки информации математический аппарат, реляционной алгебры. Наиболее популярны реляционные СУБД — dBase, FoxBase, FoxPro, Clarion, Paradox, Оracle, Access и др.
Примером реляционной базы данных может служить таблица «Сотрудники» (табл. 1), где одна строка (запись) — сведения об одном из сотрудников.
Таблица 1.
| Табельный № | Фамилия | Имя | Отчество | Дата рождения |
| Петров | Олег | Сергеевич | 15.02.1954 | |
| Сидоров | Иван | Петрович | 23.02.1976 | |
| Панин | Петр | Борисович | 07.09.1986 |
Поле (столбец таблицы) — элементарная единица логической организации данных. Каждое поле таблицы имеет уникальное имя, при этом каждое из полей однородно, т. е. данные в нем имеют одинаковые тип и длину. Для описания поля используют имя и тип данных.
Поле, значение которого однозначно определяет соответствующую запись, называется ключевым полем. Если ключевое поле одно, то это — простой ключ, если ключевых полей несколько, то ключ называется составным.
Запись — это совокупность значений связанных элементов данных. Экземпляр записи — это отдельная строка таблицы, содержащая конкретные значения ее полей.
Таблица базы данных — это совокупность экземпляров записей одной структуры. Описание структуры базы данных содержит перечень полей записи и их основные характеристики.

2. Обобщённая технология работы с БД
Технология работы с базами данных имеет несколько этапов, а именно:
Ø построение мифологической модели БД,
Ø создание структуры таблиц базы данных,
Ø обработку данных, содержащихся в таблицах,
Ø и вывод информации из БД.
На первом этапе создания базы данных строится инфологическая модель.
Для построения мифологической модели необходимо сделать анализ существующей базы данных, определить источник данных, посмотреть решаемые с помощью базы задачи и продумать проблемы, которые следует решать в будущем. Идентифицировав данные и задачи, которые следует решать, необходимо разделить их на группы, которые впоследствии станут таблицами БД.
Создание структуры таблиц базы данных предполагает определение групп и типов данных, которые будут храниться в таблицах, задание размера полей в каждой таблице и определение общих элементов таблиц-ключей.
Ввод и редактирование данных могут производиться двумя способами: с помощью специальных форм и непосредственно в таблице без использования форм.
Обработка информации в базе данных производится путем выполнения запросов или в процессе выполнения, специально разработанной программы.
Запрос — это команда, формулируемая для СУБД, которая требует представить определенную, указанную в запросе информацию. Язык SQL — это структурированный язык запросов (Structured Query Language). Запросы являются наиболее часто используемым аспектом SQL. Все запросы в SQL конструируются на базе команды SELECT (выбор).
Результатом выполнения запроса является таблица с временным набором данных (динамический набор). Записи динамического набора могут включать поля из одной или нескольких таблиц. На основе запроса можно построить отчет или форму.
Для вывода информации из базы данных существует специальное средство — отчеты. Они позволяют:
• включать в отчет выборочную информацию из таблиц базы данных;
• добавлять информацию, не содержащуюся в базе;
• выводить итоговую информацию из базы данных;
• располагать выводимую информацию в любом удобном виде;
• включать в отчет информацию из разных таблиц.

|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 1399; Нарушение авторских прав?; Мы поможем в написании вашей работы!