КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Основные алгоритмы сжатия
|
|
|
|
Типы архивов
Для сжатия используются различные алгоритмы, которые можно разделить на обратимые и методы сжатия с частичной потерей информации. Последние более эффективны, но применяются для тех файлов, для которых частичная потеря информации не приводит к значительному снижению потребительских свойств. Характерными форматами сжатия с потерей информации являются:
·.jpg - для графических данных;
·.mpg - для видеоданных;
·.mp3 - для звуковых данных.
Характерные форматы сжатия без потери информации:
·.tif,.pcx и другие - для графических файлов;
·.avi - для видеоклипов;
·.zip,.arj,.rar,.lzh,.cab и др. - для любых типов файлов.
Алгоритмы архивации без потерь
Алгоритм RLE
Первый вариант алгоритма
Данный алгоритм необычайно прост в реализации. Групповое кодирование — от английского Run Length Encoding (RLE) — один из самых старых и самых простых алгоритмов архивации графики. Изображение в нем (как и в нескольких алгоритмах, описанных ниже) вытягивается в цепочку байт по строкам растра. Само сжатие в RLE происходитза счет того, что в исходном изображении встречаются цепочки одинаковых байт. Замена их на пары <счетчик повторений, значение> уменьшает збыточность данных.
В данном алгоритме признаком счетчика (counter) служат единицы в двух верхних битах считанного файла:
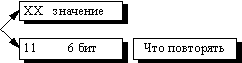 Соответственно оставшиеся 6 бит расходуются на счетчик, который может принимать значения от 1 до 64. Строку из 64 повторяющихся байтов мы превращаем в два байта, т.е. сожмем в 32 раза.
Упражнение: Составьте алгоритм компрессии для первого варианта алгоритма RLE.
Алгоритм рассчитан на деловую графику — изображения с большими областями повторяющегося цвета. Ситуация, когда файл увеличивается, для этого простого алгоритма не так уж редка. Ее можно легко получить, применяя групповое кодирование к обработанным цветным фотографиям. Для того, чтобы увеличить изображение в два раза, его надо применить к изображению, в котором значения всех пикселов больше двоичного 11000000 и подряд попарно не повторяются.
Вопрос к экзамену: Предложите два-три примера “плохих” изображений для алгоритма RLE. Объясните, почему размер сжатого файла больше размера исходного файла.
.
Характеристики алгоритма RLE:
Коэффициенты компрессии:Первый вариант: 32, 2, 0,5. Второй вариант: 64, 3, 128/129.(Лучший, средний, худший коэффициенты)
Класс изображений: Ориентирован алгоритм на изображения с небольшим количеством цветов: деловую и научную графику.
Симметричность: Примерно единица.
Характерные особенности: К положительным сторонам алгоритма, пожалуй, можно отнести только то, что он не требует дополнительной памяти при архивации и разархивации, а также быстро работает. Интересная особенность группового кодирования состоит в том, что степень архивации для некоторых изображений может быть существенно повышена всего лишь за счет изменения порядка цветов в палитре изображения.
Соответственно оставшиеся 6 бит расходуются на счетчик, который может принимать значения от 1 до 64. Строку из 64 повторяющихся байтов мы превращаем в два байта, т.е. сожмем в 32 раза.
Упражнение: Составьте алгоритм компрессии для первого варианта алгоритма RLE.
Алгоритм рассчитан на деловую графику — изображения с большими областями повторяющегося цвета. Ситуация, когда файл увеличивается, для этого простого алгоритма не так уж редка. Ее можно легко получить, применяя групповое кодирование к обработанным цветным фотографиям. Для того, чтобы увеличить изображение в два раза, его надо применить к изображению, в котором значения всех пикселов больше двоичного 11000000 и подряд попарно не повторяются.
Вопрос к экзамену: Предложите два-три примера “плохих” изображений для алгоритма RLE. Объясните, почему размер сжатого файла больше размера исходного файла.
.
Характеристики алгоритма RLE:
Коэффициенты компрессии:Первый вариант: 32, 2, 0,5. Второй вариант: 64, 3, 128/129.(Лучший, средний, худший коэффициенты)
Класс изображений: Ориентирован алгоритм на изображения с небольшим количеством цветов: деловую и научную графику.
Симметричность: Примерно единица.
Характерные особенности: К положительным сторонам алгоритма, пожалуй, можно отнести только то, что он не требует дополнительной памяти при архивации и разархивации, а также быстро работает. Интересная особенность группового кодирования состоит в том, что степень архивации для некоторых изображений может быть существенно повышена всего лишь за счет изменения порядка цветов в палитре изображения.
|
Алгоритм LZW
Название алгоритм получил по первым буквам фамилий его разработчиков — Lempel, Ziv и Welch. Сжатие в нем, в отличие от RLE, осуществляется уже за счет одинаковых цепочек байт.
Алгоритм LZ
Существует довольно большое семейство LZ-подобных алгоритмов, различающихся, например, методом поиска повторяющихся цепочек. Один из достаточно простых вариантов этого алгоритма, например, предполагает, что во входном потоке идет либо пара <счетчик, смещение относительно текущей позиции>, либо просто <счетчик> “пропускаемых” байт и сами значения байтов (как во втором варианте алгоритма RLE). При разархивации для пары <счетчик, смещение> копируются <счетчик> байт из выходного массива, полученного в результате разархивации, на <смещение> байт раньше, а <счетчик> (т.е. число равное счетчику) значений “пропускаемых” байт просто копируются в выходной массив из входного потока. Данный алгоритм является несимметричным по времени, поскольку требует полного перебора буфера при поиске одинаковых подстрок. В результате нам сложно задать большой буфер из-за резкого возрастания времени компрессии. Однако потенциально построение алгоритма, в котором на <счетчик> и на <смещение> будет выделено по 2 байта (старший бит старшего байта счетчика — признак повтора строки / копирования потока), даст нам возможность сжимать все повторяющиеся подстроки размером до 32Кб в буфере размером 64Кб.
 При этом мы получим увеличение размера файла в худшем случае на 32770/32768 (в двух байтах записано, что нужно переписать в выходной поток следующие 215 байт), что совсем неплохо. Максимальный коэффициент сжатия составит в пределе 8192 раза. В пределе, поскольку максимальное сжатие мы получаем, превращая 32Кб буфера в 4 байта, а буфер такого размера мы накопим не сразу. Однако, минимальная подстрока, для которой нам выгодно проводить сжатие, должна состоять в общем случае минимум из 5 байт, что и определяет малую ценность данного алгоритма. К достоинствам LZ можно отнести чрезвычайную простоту алгоритма декомпрессии.
Упражнение: Предложите другой вариант алгоритма LZ, в котором на пару <счетчик, смещение> будет выделено 3 байта, и подсчитайте основные характеристики своего алгоритма.
Алгоритм LZW
Рассматриваемый нами ниже вариант алгоритма будет использовать дерево для представления и хранения цепочек. Очевидно, что это достаточно сильное ограничение на вид цепочек, и далеко не все одинаковые подцепочки в нашем изображении будут использованы при сжатии. Однако в предлагаемом алгоритме выгодно сжимать даже цепочки, состоящие из 2 байт.
Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока и проверяем, есть ли в созданной нами таблице строк такая строка. Если строка есть, то мы считываем следующий символ, а если строки нет, то мы заносим в поток код для предыдущей найденной строки, заносим строку в таблицу и начинаем поиск снова.
Характеристики алгоритмаLZW:
Коэффициенты компрессии: Примерно1000, 4, 5/7 (Лучший, средний, худший коэффициенты). Сжатие в 1000 раз достигается только на одноцветных изображениях размером кратным примерно 7 Мб.
Класс изображений: Ориентирован LZW на 8-битные изображения, построенные на компьютере. Сжимает за счет одинаковых подцепочек в потоке.
Симметричность: Почти симметричен, при условии оптимальной реализации операции поиска строки в таблице.
Характерные особенности: Ситуация, когда алгоритм увеличивает изображение, встречается крайне редко. LZW универсален — именно его варианты используются в обычных архиваторах.
При этом мы получим увеличение размера файла в худшем случае на 32770/32768 (в двух байтах записано, что нужно переписать в выходной поток следующие 215 байт), что совсем неплохо. Максимальный коэффициент сжатия составит в пределе 8192 раза. В пределе, поскольку максимальное сжатие мы получаем, превращая 32Кб буфера в 4 байта, а буфер такого размера мы накопим не сразу. Однако, минимальная подстрока, для которой нам выгодно проводить сжатие, должна состоять в общем случае минимум из 5 байт, что и определяет малую ценность данного алгоритма. К достоинствам LZ можно отнести чрезвычайную простоту алгоритма декомпрессии.
Упражнение: Предложите другой вариант алгоритма LZ, в котором на пару <счетчик, смещение> будет выделено 3 байта, и подсчитайте основные характеристики своего алгоритма.
Алгоритм LZW
Рассматриваемый нами ниже вариант алгоритма будет использовать дерево для представления и хранения цепочек. Очевидно, что это достаточно сильное ограничение на вид цепочек, и далеко не все одинаковые подцепочки в нашем изображении будут использованы при сжатии. Однако в предлагаемом алгоритме выгодно сжимать даже цепочки, состоящие из 2 байт.
Процесс сжатия выглядит достаточно просто. Мы считываем последовательно символы входного потока и проверяем, есть ли в созданной нами таблице строк такая строка. Если строка есть, то мы считываем следующий символ, а если строки нет, то мы заносим в поток код для предыдущей найденной строки, заносим строку в таблицу и начинаем поиск снова.
Характеристики алгоритмаLZW:
Коэффициенты компрессии: Примерно1000, 4, 5/7 (Лучший, средний, худший коэффициенты). Сжатие в 1000 раз достигается только на одноцветных изображениях размером кратным примерно 7 Мб.
Класс изображений: Ориентирован LZW на 8-битные изображения, построенные на компьютере. Сжимает за счет одинаковых подцепочек в потоке.
Симметричность: Почти симметричен, при условии оптимальной реализации операции поиска строки в таблице.
Характерные особенности: Ситуация, когда алгоритм увеличивает изображение, встречается крайне редко. LZW универсален — именно его варианты используются в обычных архиваторах.
|
Алгоритм Хаффмана
Классический алгоритм Хаффмана
Один из классических алгоритмов, известных с 60-х годов. Использует только частоту появления одинаковых байт в изображении. Сопоставляет символам входного потока, которые встречаются большее число раз, цепочку бит меньшей длины. И, напротив, встречающимся редко — цепочку большей длины. Для сбора статистики требует двух проходов по изображению.
Для начала введем несколько определений.
Определение. Пусть задан алфавит Y ={ a 1,..., ar}, состоящий из конечного числа букв. Конечную последовательность символов из Y
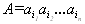 будем называть словом в алфавите Y, а число n — длиной слова A. Длина слова обозначается как l(A).
Пусть задан алфавит W, W ={ b 1 ,..., b q}. Через B обозначим слово в алфавите W и через S(W) — множество всех непустых слов в алфавите W.
Пусть S=S(Y) — множество всех непустых слов в алфавите Y, и S' — некоторое подмножество множества S. Пусть также задано отображение F, которое каждому слову A, A? S(Y), ставит в соответствие слово
B=F(A), B? S(W).
Слово В будем назвать кодом сообщения A, а переход от слова A к его коду — кодированием.
Определение. Рассмотрим соответствие между буквами алфавита Y и некоторыми словами алфавита W:
a 1 — B 1, a 2 — B 2,... a r — B r
Это соответствие называют схемой и обозначают через S. Оно определяет кодирование следующим образом: каждому слову из S'(W) = S(W) ставится в соответствие слово
будем называть словом в алфавите Y, а число n — длиной слова A. Длина слова обозначается как l(A).
Пусть задан алфавит W, W ={ b 1 ,..., b q}. Через B обозначим слово в алфавите W и через S(W) — множество всех непустых слов в алфавите W.
Пусть S=S(Y) — множество всех непустых слов в алфавите Y, и S' — некоторое подмножество множества S. Пусть также задано отображение F, которое каждому слову A, A? S(Y), ставит в соответствие слово
B=F(A), B? S(W).
Слово В будем назвать кодом сообщения A, а переход от слова A к его коду — кодированием.
Определение. Рассмотрим соответствие между буквами алфавита Y и некоторыми словами алфавита W:
a 1 — B 1, a 2 — B 2,... a r — B r
Это соответствие называют схемой и обозначают через S. Оно определяет кодирование следующим образом: каждому слову из S'(W) = S(W) ставится в соответствие слово  , называемое кодом слова A. Слова B 1 ... B r называются элементарными кодами. Данный вид кодирования называют алфавитным кодированием.
Определение. Пусть слово В имеет вид
B=B' B"
Тогда слово B' называется началом или префиксом слова B, а B" — концом слова B. При этом пустое слово L и само слово B считаются началами и концами слова B.
Определение. Схема S обладает свойством префикса, если для любых i и j (1? i, j? r, i? j) слово Bi не является префиксом слова B j.
Теорема 1. Если схема S обладает свойством префикса, то алфавитное кодирование будет взаимно однозначным.
Предположим, что задан алфавит Y ={ a 1,..., ar } (r>1) и набор вероятностей p1,..., p r , называемое кодом слова A. Слова B 1 ... B r называются элементарными кодами. Данный вид кодирования называют алфавитным кодированием.
Определение. Пусть слово В имеет вид
B=B' B"
Тогда слово B' называется началом или префиксом слова B, а B" — концом слова B. При этом пустое слово L и само слово B считаются началами и концами слова B.
Определение. Схема S обладает свойством префикса, если для любых i и j (1? i, j? r, i? j) слово Bi не является префиксом слова B j.
Теорема 1. Если схема S обладает свойством префикса, то алфавитное кодирование будет взаимно однозначным.
Предположим, что задан алфавит Y ={ a 1,..., ar } (r>1) и набор вероятностей p1,..., p r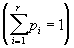 появления символов a1,..., ar. Пусть, далее, задан алфавит W, W ={ b 1,..., bq } (q>1). Тогда можно построить целый ряд схем S алфавитного кодирования
a1 — B 1,... a r — B r
обладающих свойством взаимной однозначности.
Для каждой схемы можно ввести среднюю длину l ср, определяемую как математическое ожидание длины элементарного кода: появления символов a1,..., ar. Пусть, далее, задан алфавит W, W ={ b 1,..., bq } (q>1). Тогда можно построить целый ряд схем S алфавитного кодирования
a1 — B 1,... a r — B r
обладающих свойством взаимной однозначности.
Для каждой схемы можно ввести среднюю длину l ср, определяемую как математическое ожидание длины элементарного кода:
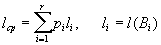 — длины слов.
Длина l ср показывает, во сколько раз увеличивается средняя длина слова при кодировании со схемой S.
Можно показать, что l ср достигает величины своего минимума l * на некоторой Sи определена как — длины слов.
Длина l ср показывает, во сколько раз увеличивается средняя длина слова при кодировании со схемой S.
Можно показать, что l ср достигает величины своего минимума l * на некоторой Sи определена как
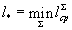 Определение. Коды, определяемые схемой S с l ср= l *, называются кодами с минимальной избыточностью, или кодами Хаффмана.
Коды с минимальной избыточностью дают в среднем минимальное увеличение длин слов при соответствующем кодировании.
В нашем случае, алфавит Y ={ a 1,..., ar } задает символы входного потока, а алфавит W ={0,1}, т.е. состоит всего из нуля и единицы.
Алгоритм построения схемы S можно представить следующим образом:
Шаг 1. Упорядочиваем все буквы входного алфавита в порядке убывания вероятности. Считаем все соответствующие слова Bi из алфавита W ={0,1} пустыми.
Шаг 2. Объединяем два символа air-1 и air с наименьшими вероятностями pi r-1 и pi r в псевдосимвол a' { air-1 air} c вероятностью pir-1 + pir. Дописываем 0 в начало слова B ir-1 (B ir-1 =0B i r-1), и 1 в начало слова B ir (B ir =1B ir).
Шаг 3. Удаляем из списка упорядоченных символов air-1 и air, заносим туда псевдосимвол a' { air-1 air}. Проводим шаг 2, добавляя при необходимости 1 или ноль для всех слов Bi, соответствующих псевдосимволам, до тех пор, пока в списке не останется 1 псевдосимвол.
Пример: Пусть у нас есть 4 буквы в алфавите Y ={ a 1,..., a 4} (r=4), p 1=0.5, p 2=0.24, p 3=0.15, p 4=0.11
Определение. Коды, определяемые схемой S с l ср= l *, называются кодами с минимальной избыточностью, или кодами Хаффмана.
Коды с минимальной избыточностью дают в среднем минимальное увеличение длин слов при соответствующем кодировании.
В нашем случае, алфавит Y ={ a 1,..., ar } задает символы входного потока, а алфавит W ={0,1}, т.е. состоит всего из нуля и единицы.
Алгоритм построения схемы S можно представить следующим образом:
Шаг 1. Упорядочиваем все буквы входного алфавита в порядке убывания вероятности. Считаем все соответствующие слова Bi из алфавита W ={0,1} пустыми.
Шаг 2. Объединяем два символа air-1 и air с наименьшими вероятностями pi r-1 и pi r в псевдосимвол a' { air-1 air} c вероятностью pir-1 + pir. Дописываем 0 в начало слова B ir-1 (B ir-1 =0B i r-1), и 1 в начало слова B ir (B ir =1B ir).
Шаг 3. Удаляем из списка упорядоченных символов air-1 и air, заносим туда псевдосимвол a' { air-1 air}. Проводим шаг 2, добавляя при необходимости 1 или ноль для всех слов Bi, соответствующих псевдосимволам, до тех пор, пока в списке не останется 1 псевдосимвол.
Пример: Пусть у нас есть 4 буквы в алфавите Y ={ a 1,..., a 4} (r=4), p 1=0.5, p 2=0.24, p 3=0.15, p 4=0.11 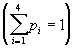 . Тогда процесс построения схемы можно представить так: . Тогда процесс построения схемы можно представить так:
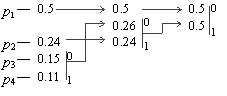 Производя действия, соответствующие 2-му шагу, мы получаем псевдосимвол с вероятностью 0.26 (и приписываем 0 и 1 соответствующим словам). Повторяя же эти действия для измененного списка, мы получаем псевдосимвол с вероятностью 0.5. И, наконец, на последнем этапе мы получаем суммарную вероятность 1.
Для того, чтобы восстановить кодирующие слова, нам надо пройти по стрелкам от начальных символов к концу получившегося бинарного дерева. Так, для символа с вероятностью p 4, получим B4=101, для p 3 получим B3=100, для p 2 получим B2=11, для p 1 получим B1=0. Что означает схему:
a 1 — 0, a 2 — 11 a 3 — 100 a 4 — 101
Эта схема представляет собой префиксный код, являющийся кодом Хаффмана. Самый часто встречающийся в потоке символ a 1 мы будем кодировать самым коротким словом 0, а самый редко встречающийся a 4 длинным словом 101.
Для последовательности из 100 символов, в которой символ a 1 встретится 50 раз, символ a 2 — 24 раза, символ a 3 — 15 раз, а символ a 4 — 11 раз, данный код позволит получить последовательность из 176 бит (
Производя действия, соответствующие 2-му шагу, мы получаем псевдосимвол с вероятностью 0.26 (и приписываем 0 и 1 соответствующим словам). Повторяя же эти действия для измененного списка, мы получаем псевдосимвол с вероятностью 0.5. И, наконец, на последнем этапе мы получаем суммарную вероятность 1.
Для того, чтобы восстановить кодирующие слова, нам надо пройти по стрелкам от начальных символов к концу получившегося бинарного дерева. Так, для символа с вероятностью p 4, получим B4=101, для p 3 получим B3=100, для p 2 получим B2=11, для p 1 получим B1=0. Что означает схему:
a 1 — 0, a 2 — 11 a 3 — 100 a 4 — 101
Эта схема представляет собой префиксный код, являющийся кодом Хаффмана. Самый часто встречающийся в потоке символ a 1 мы будем кодировать самым коротким словом 0, а самый редко встречающийся a 4 длинным словом 101.
Для последовательности из 100 символов, в которой символ a 1 встретится 50 раз, символ a 2 — 24 раза, символ a 3 — 15 раз, а символ a 4 — 11 раз, данный код позволит получить последовательность из 176 бит (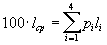 ). Т.е. в среднем мы потратим 1.76 бита на символ потока.
Доказательства теоремы, а также того, что построенная схема действительно задает код Хаффмана, смотри в [10].
Как стало понятно из изложенного выше, классический алгоритм Хаффмана требует записи в файл таблицы соответствия кодируемых символов и кодирующих цепочек.
На практике используются его разновидности. Так, в некоторых случаях резонно либо использовать постоянную таблицу, либо строить ее “адаптивно”, т.е. в процессе архивации/разархивации. Эти приемы избавляют нас от двух проходов по изображению и необходимости хранения таблицы вместе с файлом. Кодирование с фиксированной таблицей применяется в качестве последнего этапа архивации в JPEG и в рассмотренном ниже алгоритме CCITT Group 3.
Характеристики классического алгоритма Хаффмана:
Коэффициенты компрессии:8, 1,5, 1 (Лучший, средний, худший коэффициенты).
Класс изображений: Практически не применяется к изображениям в чистом виде. Обычно используется как один из этапов компрессии в более сложных схемах.
Симметричность: 2 (за счет того, что требует двух проходов по массиву сжимаемых данных).
Характерные особенности: Единственный алгоритм, который не увеличивает размера исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом). ). Т.е. в среднем мы потратим 1.76 бита на символ потока.
Доказательства теоремы, а также того, что построенная схема действительно задает код Хаффмана, смотри в [10].
Как стало понятно из изложенного выше, классический алгоритм Хаффмана требует записи в файл таблицы соответствия кодируемых символов и кодирующих цепочек.
На практике используются его разновидности. Так, в некоторых случаях резонно либо использовать постоянную таблицу, либо строить ее “адаптивно”, т.е. в процессе архивации/разархивации. Эти приемы избавляют нас от двух проходов по изображению и необходимости хранения таблицы вместе с файлом. Кодирование с фиксированной таблицей применяется в качестве последнего этапа архивации в JPEG и в рассмотренном ниже алгоритме CCITT Group 3.
Характеристики классического алгоритма Хаффмана:
Коэффициенты компрессии:8, 1,5, 1 (Лучший, средний, худший коэффициенты).
Класс изображений: Практически не применяется к изображениям в чистом виде. Обычно используется как один из этапов компрессии в более сложных схемах.
Симметричность: 2 (за счет того, что требует двух проходов по массиву сжимаемых данных).
Характерные особенности: Единственный алгоритм, который не увеличивает размера исходных данных в худшем случае (если не считать необходимости хранить таблицу перекодировки вместе с файлом).
|
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 377; Нарушение авторских прав?; Мы поможем в написании вашей работы!