КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Комментарии
|
|
|
|
Комментарий либо начинается с двух символов «прямая косая черта» (//) и заканчивается символом перехода на новую строку, либо заключается между символами-скобками /* и */. Внутри комментария можно использовать любые допустимые на данном компьютере символы, а не только символы из алфавита языка C++, поскольку компилятор комментарии игнорирует. Вложенные комментарии-скобки стандартом не допускаются, хотя в некоторых компиляторах разрешены.
7. Типы данных С++
Основная цель любой программы состоит в обработке данных. Данные различного типа хранятся и обрабатываются по-разному. В любом алгоритмическом языке каждая константа, переменная, результат вычисления выражения или функции должны иметь определенный тип.
Тип данных определяет:
- внутреннее представление данных в памяти компьютера;
- множество значений, которые могут принимать величины этого типа;
- операции и функции, которые можно применять к величинам этого тина.
Исходя из этих характеристик, программист выбирает тип каждой величины, используемой в программе для представления реальных объектов. Обязательное описание типа позволяет компилятору производить проверку допустимости различных конструкций программы. От типа величины зависят машинные команды, которые будут использоваться для обработки данных.
Все типы языка C++ можно разделить на основные и составные. В языке C++ определено шесть основных типов данных для представления целых, вещественных, символьных и логических величин. На основе этих типов программист может вводить описание составных типов. К ним относятся массивы, перечисления, функции, структуры, ссылки, указатели, объединения и классы.
Основные (стандартные) типы данных часто называют арифметическими, поскольку их можно использовать в арифметических операциях. Для описания основных типов определены следующие ключевые слова:
• int (целый);
• char (символьный);
• wchar_t (расширенный символьный);
• bool (логический);
• float (вещественный);
• double (вещественный с двойной точностью).
Первые четыре тина называют целочисленными (целыми), последние два – типами с плавающей точкой. Код, который формирует компилятор для обработки целых величин, отличается от кода для величин с плавающей точкой.
Существует четыре спецификатора типа, уточняющих внутреннее представление и диапазон значений стандартных типов:
• short (короткий);
• long (длинный);
• signed (знаковый);
• unsigned (беззнаковый).
Целый тип (int). Размер типа int не определяется стандартом, а зависит от компьютера и компилятора.
Для 16-разрядного процессора под величины этого типа отводится 2 байта, для 32-разрядного – 4 байта.
Спецификатор short перед именем типа указывает компилятору, что под число требуется отвести 2 байта независимо от разрядности процессора. Спецификатор long означает, что целая величина будет занимать 4 байта. Таким образом, на 16-разрядном компьютере эквиваленты int и short int, а на 32-разрядном – int и long int.
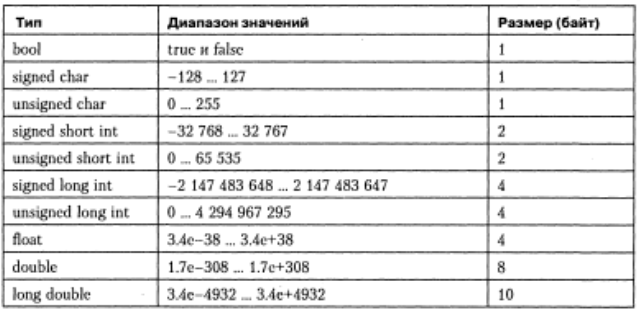
Внутреннее представление величины целого типа – целое число в двоичном коде. При использовании спецификатора signed старший бит числа интерпретируется как знаковый (0 — положительное число, 1 — отрицательное). Спецификатор unsigned позволяет представлять только положительные числа, поскольку старший разряд рассматривается как часть кода числа. Таким образом, диапазон значений типа 1nt зависит от спецификаторов. Диапазоны значений величин целого типа с различными спецификаторами для IBM PC-совместимых компьютеров приведены в табл. 4.
По умолчанию все целочисленные типы считаются знаковыми, то есть спецификатор signed можно опускать.
Константам, встречающимся в программе, приписывается тот или иной тип в соответствии с их видом. Если этот тип по каким-либо причинам не устраивает программиста, он может явно указать требуемый тип с помощью суффиксов L, 1 (long) и и, U (unsigned). Например, константа 32L будет иметь тип long и занимать 4 байта. Можно использовать суффиксы L и U одновременно, например, Ox22UL или 05LU.
Типы short int, long int, signed int и unsigned int можно сокращать до short, long, signed и unsigned соответственно.
Символьный тип (char). Под величину символьного типа отводится количество байт, достаточное для размещения любого символа из набора символов для данного компьютера, что и обусловило название типа. Как правило, это 1 байт. Тип char, как и другие целые типы, может быть со знаком или без знака. В величинах со знаком можно хранить значения в диапазоне от -128 до 127. При использовании спецификатора unsigned значения могут находиться в пределах от 0 до 255. Этого достаточно для хранения любого символа из 256-символьного набора ASCH. Величины типа char применяются также для хранения целых чисел, не превышающих границы указанных диапазонов.
Расширенный символьный тип (wchar_t). Тип wchar_t предназначен для работы с набором символов, для кодировки которых недостаточно 1 байта, например, Unicode. Размер этого типа зависит от реализации; как правило, он соответствует типу short. Строковые константы типа wchar_t записываются с префиксом L, например, L"Здравствуйте".
Логический тип (bool). Величины логического типа могут принимать только значения true и false, являющиеся зарезервированными словами. Внутренняя форма представления значения false — 0 (нуль). Любое другое значение интерпретируется как true. При преобразовании к целому типу true имеет значение 1.
Типы с плавающей точкой (float, double и long double). Стандарт C++ определяет три типа данных для хранения вещественных значений: float, double и long double.
Типы данных с плавающей точкой хранятся в памяти компьютера иначе, чем целочисленные. Внутреннее представление вещественного числа состоит из двух частей – мантиссы и порядка. В IBM PC-совместимых компьютерах величины типа float занимают 4 байта, из которых один двоичный разряд отводится под знак мантиссы, 8 разрядов под порядок и 23 под мантиссу. Мантисса – это число, большее 1.0, но меньшее 2.0. Поскольку старшая цифра мантиссы всегда равна 1, она не хранится.
Для величин типа double, занимающих 8 байт, под порядок и мантиссу отводится 11 и 52 разряда соответственно. Длина мантиссы определяет точность числа, а длина порядка — его диапазон. Как можно видеть из табл. 1.4, при одинаковом количестве байт, отводимом под величины типа float и long int, диапазоны их допустимых значений сильно различаются из-за внутренней формы представления.
Спецификатор long перед именем типа double указывает, что под величину отводится 10 байт.
Константы с плавающей точкой имеют по умолчанию тип double. Можно явно указать тип константы с помощью суффиксов F, f (float) и L, 1 (long). Например, константа 2E+6L будет иметь тип long double, а константа 1.82f – тип float.
Для вещественных типов в таблице приведены абсолютные величины минимальных и максимальных значений.
Тип void. Кроме перечисленных, к основным типам языка относится тип void, но множество значений этого типа пусто. Он используется для определения функций, которые не возвращают значения, для указания пустого списка аргументов функции, как базовый тип для указателей и в операции приведения типов.
Таблица 4
Диапазоны значений простых типов данных для IBM PC
8. Структура и компоненты простой программы на языке С++
Каждая программа на языке С++ есть последовательность препроцессорных директив, описаний и определений глобальных объектов и функций. Препроцессорные директивы управляют преобразованием текста программы до ее компиляции. Определения вводят функции и объекты. Объекты необходимы для представления в программе обрабатываемых данных. Функции определяют потенциально возможные действия программы. Описания уведомляют компилятор о свойствах и именах тех объектов и функций, которые определены в других частях программы (например, ниже по ее тексту или в другом файле).
Программа на языке С++ должна быть оформлена в виде одного или нескольких текстовых файлов. Текстовый файл разбит на строки. В конце каждой строки есть признак ее окончания (плюс управляющий символ перехода к началу новой строки).
Для того чтобы выполнить программу, требуется перевести ее на язык, понятный процессору – в машинные коды. Этот процесс состоит из нескольких этапов. Рисунок 2 иллюстрирует эти этапы для языка С++.
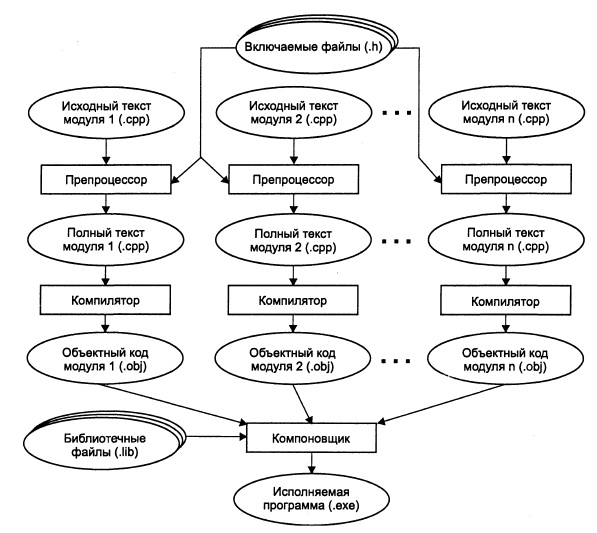
Рисунок 2 - Этапы создания исполняемой программы
Сначала программа передается препроцессору, который выполняет директивы, содержащиеся в ее тексте (например, включение в текст так называемых заголовочных файлов - текстовых файлов, в которых содержатся описания используемых в программе элементов).
Получившийся полный текст программы поступает на вход компилятора, который выделяет лексемы, а затем на основе грамматики языка распознает выражения и операторы, построенные из этих лексем. При этом компилятор выявляет синтаксические ошибки и в случае их отсутствия строит объектный модуль.
Компоновщик, или редактор связей, формирует исполняемый модуль программы, подключая к объектному модулю другие объектные модули, в том числе содержащие функции библиотек, обращение к которым содержится в любой программе (например, для осуществления вывода на экран). Если программа состоит из нескольких исходных файлов, они компилируются по отдельности и объединяются на этапе компоновки. Исполняемый модуль имеет расширение.ехе и запускается на выполнение обычным образом.
Определения и описания программы на языке С++ могут размещаться в строках текстового файла достаточно произвольно (в свободном формате.) Для препроцессорных директив существуют ограничения. Во-первых, препроцессорная директива обычно размещается в одной строке, т.е. признаком ее окончания является признак конца строки текста программы. Во-вторых, символ '#', вводящий каждую директиву препроцессора, должен быть первым отличным от пробела символом в строке с препроцессорной директивой.
Задача препроцессора - преобразование текста программы до ее компиляции. Правила препроцессорной обработки определяет программист с помощью директив препроцессора. Каждая препроцессорная директива начинается с символа '#'.
Препроцессор "сканирует" исходный текст программы в поиске строк, начинающихся с символа '#'. Такие строки воспринимаются препроцессором как команды (директивы), которые определяют действия по преобразованию текста. #define указывает правила замены в тексте.
Директива #include определяет, какие текстовые файлы нужно включить в этом месте текста программы.
Директива #include <...> предназначена для включения в текст программы текста файла из каталога "заголовочных файлов", поставляемых вместе со стандартными библиотеками компилятора. Каждая библиотечная функция, определенная стандартом языка Си, имеет соответствующее описание (прототип библиотечной функции плюс определения типов, переменных, макроопределений и констант) в одном из заголовочных файлов. Список заголовочных файлов для стандартных библиотек определен стандартом языка.
Важно понимать, что употребление в программе препроцессорной директивы
#include < имя заголовочного файла >
не подключает к программе соответствующую стандартную библиотеку. Препроцессорная обработка выполняется на уровне исходного текста программы. Директива #include только позволяет вставить в текст программы описания из указанного заголовочного файла. Подключение к программе кодов библиотечных функций осуществляется только на этапе редактирования связей (этап компоновки), т.е. после компиляции, когда уже получен машинный код программы. Доступ к кодам библиотечных функций нужен только на этапе компоновки. Именно поэтому компилировать программу и устранять синтаксические ошибки в ее тексте можно без стандартной библиотеки, но обязательно с заголовочными файлами.
Отметим, что хотя в заголовочных файлах содержатся описания всех стандартных функций, в код программы включаются только те функции, которые используются в программе. Выбор нужных функций выполняет компоновщик на этапе, называемом "редактирование связей".
Термин "заголовочный файл" (header file) в применении к файлам, содержащим описания библиотечных функций стандартных библиотек, не случаен. Он предполагает включение этих файлов именно в начало программы. Описание или определения функций должны быть "выше" по тексту, чем вызовы функций. Именно поэтому заголовочные файлы нужно помещать в начале текста программы, т.е. заведомо раньше обращений к соответствующим библиотечным функциям.
Хотя заголовочный файл может быть включен в программу не в ее начале, а непосредственно перед обращением к нужной библиотечной функции, такое размещение директив #include <...> не рекомендуется.
Структура программы. После выполнения препроцессорной обработки в тексте программы не остается ни одной препроцессорной директивы. Теперь программа представляет собой набор описаний и определений. Если не рассматривать (в этой главе) определений глобальных объектов и описаний, то программа будет набором определений функций.
Среди этих функций всегда должна присутствовать функция с фиксированным именем main. Именно эта функция является главной функцией программы, без которой программа не может быть выполнена. Имя этой главной функции для всех программ одинаково (всегда main) и не может выбираться произвольно. Таким образом, исходный текст программы в простом случае (когда программа состоит только из одной функции) имеет такой вид:
директивы препроцессора
описания
void main()
{
определения объектов;
исполняемые_операторы; }
Перед именем каждой функции программы следует помещать сведения о типе возвращаемого функцией значения (тип результата). Если функция ничего не возвращает, то указывается тип void. Функция main() является той функцией программы, которая запускается на исполнение по командам операционной системы. Возвращаемое функцией main() значение также передается операционный системе. Если не предполагается, что операционная система будет анализировать результат выполнения программы, то проще всего указать, что возвращаемое значение отсутствует, т.е. имеет тип void. Если сведения о типе результата отсутствуют, то считается по умолчанию, что функция main возвращает целочисленное значение типа int.
Каждая функция (в том числе и main) в языке Си должна иметь набор параметров. Этот набор может быть пустым, тогда в скобках после имени функции помещается служебное слово void либо скобки остаются пустыми. В отличие от обычных функций главная функция main() может использоваться как с параметрами, так и без них.
Вслед за заголовком void main() размещается тело функции. Тело функции - это блок, последовательность определений, описаний и исполняемых операторов, заключенная в фигурные скобки. Определения и описания в блоке будем размещать до исполняемых операторов. Каждое определение, описание и каждый оператор завершается символом ';' (точка с запятой).
Определения вводят объекты, необходимые для представления в программе обрабатываемых данных. Примером таких объектов служат именованные константы и переменные разных типов. Описания уведомляют компилятор о свойствах и именах объектов и функций, определенных в других частях программы. Операторы определяют действия программы на каждом шаге ее выполнения.
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 1214; Нарушение авторских прав?; Мы поможем в написании вашей работы!