КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Модели данных
|
|
|
|
Понятие Данных, Типы Данных.
1.1. Понятие данных, Типы данных
Данные - набор конкретных значений параметров, характеризующих объекты, условия, ситуацию или любые другие факты. Однако данные — это абстракция; никто никогда не видел "просто данные"; они не возникают и не существуют сами по себе. Данные - суть отражения объектов реального мира. Данные не обладают какой-то определённой структурой. И становятся информацией, когда пользователь этой структурой их задаёт.
Рассмотрим, какие вообще типы данных обычно рассматриваются в программировании. Как правило, типы данных делятся на три группы:
- Простые типы данных.
- Структурированные типы данных.
- Ссылочные типы данных.
Простые типы данных
Простые, или атомарные, типы данных - не обладают внутренней структурой. Данные такого типа называют скалярами. К простым типам данных относятся следующие типы:
- Логический.
- Строковый.
- Численный.
Различные языки программирования могут расширять и уточнять этот список, добавляя такие типы как:
- Целый.
- Вещественный.
- Символьный.
- Дата.
- Время.
- Денежный.
- Перечислимый.
- Интервальный.
- И т.д.…
Конечно, понятие атомарности довольно относительно. Так, строковый тип данных можно рассматривать как одномерный массив символов, а целый тип данных - как набор битов. Важно лишь то, что при переходе на такой низкий уровень теряется семантика (смысл) данных. Если строку, выражающую, например, фамилию сотрудника, разложить в массив символов, то при этом теряется смысл такой строки как фамилии.
Структурированные типы данных
Структурированные типы данных предназначены для задания сложных структур данных. Структурированные типы данных конструируются из составляющих элементов, называемых компонентами, которые, в свою очередь, могут обладать структурой. В качестве структурированных типов данных можно привести следующие типы данных:
- Массивы.
- Записи (Структуры).
С математической точки зрения массив представляет собой функцию с конечной областью определения. Вспомните арифметическую последовательность, например. Рассмотрим конечное множество натуральных чисел 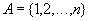 , называемое множеством индексов. Отображение
, называемое множеством индексов. Отображение 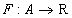 из множества
из множества 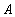 во множество вещественных чисел
во множество вещественных чисел 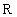 задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса
задает одномерный вещественный массив. Значение этой функции для некоторого значения индекса 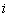 называется элементом массива, соответствующим . Аналогично можно задавать многомерные массивы.
называется элементом массива, соответствующим . Аналогично можно задавать многомерные массивы.
Запись (или структура) представляет собой кортеж из некоторого декартового произведения множеств. Действительно, запись представляет собой именованный упорядоченный набор элементов 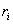 , каждый из которых принадлежит типу
, каждый из которых принадлежит типу 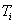 . Таким образом, запись
. Таким образом, запись 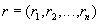 есть элемент множества
есть элемент множества 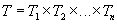 .
.
Структура похожа на массив с теми отличиями, что в ней данные могут быть разных типов. Представьте, что вы хотите положить в бумажник несколько денежных купюр, тогда отделение бумажника, в который вы их положите – будет массивом. А если вы в бумажник кладёте ещё и монеты – то бумажник можно рассматривать, как структуру.
Пример массива: {12, 43, 65, 67, 4}
Пример двумерного массива:
12, 43, 65, 67, 4
51, 24, 93, 68, 33
32, 72, 58, 27, 2
Пример структуры: {12, a, 65, 67, v}
Объявляя новые типы записей на основе уже имеющихся типов, пользователь может конструировать сколь угодно сложные типы данных.
Общим для структурированных типов данных является то, что они имеют внутреннюю структуру, используемую на том же уровне абстракции, что и сами типы данных.
Поясним это следующим образом. При работе с массивами или записями можно манипулировать массивом или записью и как с единым целым (создавать, удалять, копировать целые массивы или записи), так и поэлементно. Например, вы можете класть и вынимать купюры из бумажника по одной или несколько, а можно и весь бумажник отдать или найти. Для структурированных типов данных есть специальные функции - конструкторы типов, позволяющие создавать массивы или записи из элементов более простых типов.
Работая же с простыми типами данных, например с числовыми, мы манипулируем ими как неделимыми целыми объектами. Чтобы "увидеть", что числовой тип данных на самом деле сложен (является набором битов), нужно перейти на более низкий уровень абстракции. На уровне программного кода это будет выглядеть как ассемблерные вставки в код на языке высокого уровня или использование специальных побитных операций.
Ссылочные типы данных
Ссылочный тип данных (указатели) предназначен для обеспечения возможности указания на другие данные. Указатели характерны для языков процедурного типа, в которых есть понятие области памяти для хранения данных. Особенность таких языков программирования состоит в том, что задачи разбиваются на шаги и решаются шаг за шагом. Ссылочный тип данных предназначен для обработки сложных изменяющихся структур, например деревьев, которые эмулируют древовидную структуру в виде набора связанных узлов. Для примера – откройте проводник Windows, и увидите древовидную структуру.
1.2. Модели данных. Понятие и классификация.
Модель данных - это некоторая абстракция, которая будучи приложенной к конкретным данным позволяет пользователю и разработчику трактовать их, как информацию; в итоге, структурированные сведения содержат не только набор каких-то данных, но и связи между ними.
Другими словами, модель данных (МД) описывает некоторый набор родовых понятий и признаков, которыми должны обладать все конкретные Систему Управления Базами Данных (СУБД) и управляемые ими Базы Данных (БД), если они основываются на этой модели. Наличие модели данных позволяет сравнивать конкретные реализации, используя один общий язык.
Выделяют 3 вида моделей:
1.Инфологические - описывает смысловые содержания, здесь происходит выделение сущности объекта и связей между сущностями.
2.Даталогические - строятся на основе инфологических. Это модели для создания конкретных СУБД.
3.Физические - характеризуют распределение информационных ресурсов БД на конкретных физических носителях.
Ориентированные на формат документа
1. Документальные.
2. Тезаурусные.
3. Дескрипторные.
Документальные - соответствуют представлению слабоструктурированной информации.
Тезаурусные - основаны на принципах организации словарей. Пример: гипертекстовый документ. В настоящее время эти модели широко используются в программных переводчиках.
Дескрипторные - используются для создания БД. В этих моделях каждому документу соответствует описание. Этот описатель (дескриптор) имеет жёсткий формат и является ссылкой на определённую в документах информацию, текстовая информация дескриптора часто заменялась некоторыми цифровыми кодами. Традиционно это было обусловлено тем, что:
-объёмы носителей информации были слишком малы.
-процедура анализа текстовой информации сложна по сравнению с числовой (к примеру, книги разбиваются на разделы, разделы – на главы, главы – на параграфы, и т.д.).
1. Теоретико-графовые.
2. Теоретико-множественные (фактографические).
3. Объектно-ориентированные.
В основе Теоретико-графовых моделей лежит теория графов. Граф – это совокупность объектов со связями между ними. Объекты представляются как вершины, или узл ы графа, а связи – как дуги, или рёбра.
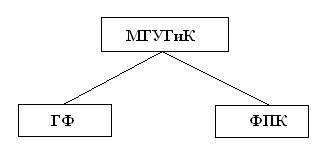
Рис.1.1. Пример теоретико-графовой модели данных.
Теоретико-графовые модели делятся на:
-Иерархические.
-Сетевые.
Теоретико-графовые модели.
Иерархическая модель.
1-ая версия СУБД появилась в 1968г. Именно в ней была использована модель, представляющая собой упорядоченные наборы деревьев. Иерархическая модель данных строится по принципу иерархии типов объектов, т.е. один тип объекта является главным, а остальные подчиненными.

Рис.1.2. Пример иерархической модели данных.
Узел дерева (вершина) – это совокупность атрибутов, описывающих объект.
Между главными и подчиненными объектами установлено отношение "один ко многим". Для каждого подчиненного типа объекта может быть только один исходный тип объекта.
Основным недостатком этой модели является то, что поиск необходимой информации достаточно длителен. Попробуйте в качестве эксперимента «добраться» до последней директории в какой-нибудь системной папке на своём компьютере.
Сетевая модель.
В этой модели понятие главного и подчиненного объекта несколько расширено. Любой объект может быть главным и подчиненным. Каждый объект может участвовать в любом числе взаимодействий. Т.е. любая информационная единица может иметь множество предков (исходных объектов) и множество потомков (подчинённых объектов).
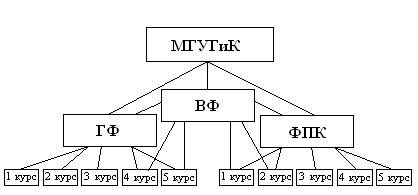
Рис.1.3. Пример сетевой модели данных.
В этих моделях связи заложены внутри описания каждого объекта.
Достоинство: гибкость - может увеличить быстродействие системы. Так как «альтернативный путь» к необходимой информации (И) может проходить «сквозь» несколько уровней.
Недостаток: нагрузка на информационные ресурсы. Потому что каждый узел (вершина) перегружен информацией о входящих и выходящих связях.
Достоинства и недостатки теоретико-графовых моделей.
Достоинства:
1. Развитое средство управления во внешней памяти на низком уровне. Внешняя память – это память, предназначенная для длительного хранения программ и данных.
2. Возможность построить вручную эффективные прикладные программы. Без особых знаний сможете на практике построить простейшую базу данных, основанную на файловой системе.
3. Возможность экономии памяти распределённой информации на объектах системы. В конкретном узле нам достаточно знать о связях, ведущих к другим узлам, и всё.
Недостатки:
1. Слишком сложно пользоваться. Просто представьте, что столетний дуб – ваша база данных.
2. Фактически необходимо знание о физической организации информации. Допустим, вы знаете, что в некой системной директории вашего компьютера находится файл setup.ini, но не знаете, в какой именно. А теперь попробуйте найти его, не пользуясь программным поиском.
3. Логика СУБД перегружена деталями организации доступа к данным. В каждом узле помимо информации об объекте прописаны связи ко всем «соседним» объектам.
Теоретико-множественные модели основаны на теории множеств, опираются на свойства множеств и операции, которые производятся над множествами. По Георгу Кантору: под «множеством» мы понимаем соединение в некое целое M определённых хорошо различимых предметов m нашего созерцания или нашего мышления (которые будут называться «элементами» множества M). Эти модели наиболее перспективны для создания БД.
Теоретико-множественные делятся на:
-Реляционные.
-Бинарных ассоциаций.
Теоретико-множественные и объектно-ориентированные модели будем рассматривать более подробно в следующих лекциях.
Лекция 2. Файлы.
|
|
|
|
|
Дата добавления: 2014-01-05; Просмотров: 1353; Нарушение авторских прав?; Мы поможем в написании вашей работы!