КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Кодирование текстовой информации
|
|
|
|
Традиционно для кодирования одного символа текстовой информации используется 1 байт (8 битов). Этого количества информации достаточно для кодировки 256 символов (28 = 256).
Каждому символу присваивается уникальный двоичный код от 00000000 (010) до 11111111 (25510) – это операция кодирования. Процесс вывода символа на экран или на печатающее устройство заключается в обратном преобразовании – декодировании.
Соответствие символов и кодов зафиксировано специальными кодовыми таблицами (таблица 2.3).
Первая часть всех кодовых таблиц (коды от 0 до 127) – постоянна и предназначена для кодировки заглавных и строчных латинских букв, цифр, знаков арифметических операций, знаков препинания и некоторых специальных символов.
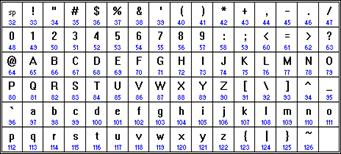
В качестве международного стандарта принята кодовая таблица ASCII (American Standard Code for Information Interchange), кодирующая первую половину символов с числовыми кодами от 0 до 127 (коды от 0 до 32 отведены не символам, а функциональным клавишам).
Международная организация по стандартизации (International Standards Organization, ISO) утвердила в качестве стандарта для русского языка еще одну кодировку под названием ISO 8859-5.
Таблица 2.3 – Основные таблицы кодировок
| Операционная система | Кодировки кириллицы | Размер кода обмена информацией |
| ОС ЕС ЭВМ, ОСUNIX | КОИ8 | 8 битный код |
| MS DOS | CP866 | |
| ОС Microsoft Windows | CP1251 | |
| ОС Macintosh (Apple) | Macintosh (Mac) | |
| Международный стандарт | Unicode UTF-8 и UTF-16 | 8 и 16 битный код |
| Международный стандарт ISO (для русского языка) | ISO 8859-5 | |
| Международный стандарт | ASCII |
Национальные стандарты кодировочных таблиц включают международную часть кодовой таблицы без изменений, а во второй половине содержат коды национальных алфавитов, символы псевдографики и некоторые математические знаки.
|
|
|
В настоящее время существуют 6 различных кодировок кириллицы (КОИ8-Р, Windows, MS-DOS, Macintosh, Unicode и ISO), что вызывает дополнительные трудности при работе с русскоязычными документами.
Хронологически одним из первых стандартов кодирования русских букв на компьютерах был КОИ8 ("Код обмена информацией, 8-битный"). Эта кодировка применялась еще в 70-ые годы на компьютерах серии ЕС ЭВМ, а с середины 80-х стала использоваться в первых русифицированных версиях операционной системы UNIX.
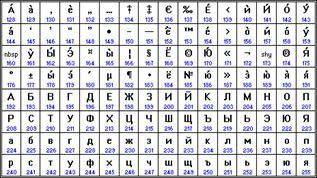
Наиболее распространенной в настоящее время является кодировка Microsoft Windows, обозначаемая сокращением CP1251 ("CP" означает "Code Page", "кодовая страница").
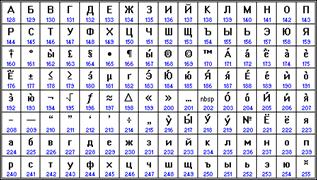
От начала 90-ых годов, времени господства операционной системы MS DOS, остается кодировка CP866.
Компьютеры фирмы Apple, работающие под управлением операционной системы Mac OS, используют свою собственную кодировку Mac.
В конце 90-ых годов появился новый международный стандарт Unicode, который отводит под один символ не один байт, а два, и поэтому с его помощью можно закодировать не 256, а 65536 различных символов. Полная спецификация стандарта Unicode включает в себя все существующие, вымершие и искусственно созданные алфавиты мира, а также множество математических, музыкальных, химических и прочих символов.
Чаще всего используют кодировки Unicode UTF-8 и UTF-16:
| Кодировка | Описание |
| UTF-8 | Символы в UTF-8 могут быть длиной от 1 до 4 байт. С помощью этой кодировки можно отобразить любой символ. UTF-8 обратно совместим со стандартом ASCII. UTF-8— рекомендованная кодировка для электронной почты и веб-страниц. |
| UTF-16 | 16-битный формат преобразования Unicode позволяет кодировать любые символы переменной длины. Эта кодировка используется в основных операционных системах и средах разработки, таких как Microsoft Windows 2000/XP/2003/Vista/CE, Java и.NET. |
Первые 256 символов кодировок Unicode соответствуют 256 символам ISO-8859-1.
|
|
|
Пример 1. Последовательности десятичных кодов слова «ЭВМ» в различных кодировках на основе кодировочных таблиц:
| КОИ8-Р | 252 247 237 | ||||||
| CP1251 | 221 194 204 | ||||||
| CP866 | 157 130 140 | ||||||
| Mac | 157 130 140 | ||||||
| ISO | 205 178 188 | ||||||
| Кодировка русских букв КОИ8-Р | Кодировка русских букв CP1251 | ||||||
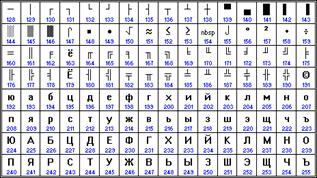
| 
| ||||||
| Кодировка русских букв CP866 | Кодировка русских букв MAC | ||||||

| 
| ||||||
| Кодировка русских букв ISO 8859-5 | Международная кодировка ASCII | ||||||
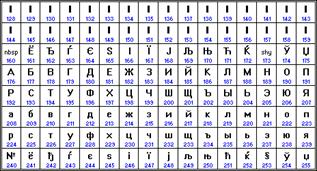
| 
| ||||||
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 1905; Нарушение авторских прав?; Мы поможем в написании вашей работы!