КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Вероятностный подход
|
|
|
|
Рассмотрим в качестве примера опыт, связанный с бросанием правильной игральной.кости, имеющей N граней (наиболее распространенным является случай шестигранной кости: N = 6). Результаты данного опыта могут быть следующие: выпадение грани с одним из следующих знаков: 1,2,... N.
Введем в рассмотрение численную величину, измеряющую неопределенность - энтропию (обозначим ее Н). Величины N и Н связаны между собой некоторой функциональной зависимостью:
H = f (N), (1.1)
а сама функция f является возрастающей, неотрицательной и определенной (в рассматриваемом нами примере) для N = 1, 2,... 6.
Рассмотрим процедуру бросания кости более подробно:
1) готовимся бросить кость; исход опыта неизвестен, т.е. имеется некоторая неопределенность; обозначим ее H1;
2) кость брошена; информация об исходе данного опыта получена; обозначим количество этой информации через I;
3) обозначим неопределенность данного опыта после его осуществления через H2. За количество информации, которое получено в ходе осуществления опыта, примем разность неопределенностей “до” и “после” опыта:
I = H1 – H2 (1.2)
Очевидно, что в случае, когда получен конкретный результат, имевшаяся неопределенность снята (Н2 = 0), и, таким образом, количество полученной информации совпадает с первоначальной энтропией. Иначе говоря, неопределенность, заключенная в опыте, совпадает с информацией об исходе этого опыта. Заметим, что значение Н2 могло быть и не равным нулю, например, в случае, когда в ходе опыта следующей выпала грань со значением, большим “З”.
Следующим важным моментом является определение вида функции f в формуле (1.1). Если варьировать число граней N и число бросаний кости (обозначим эту величину через М), общее число исходов (векторов длины М, состоящих из знаков 1,2,.... N) будет равно N в степени М:
X=NM. (1.3)
Так, в случае двух бросаний кости с шестью гранями имеем: Х =62=36. Фактически каждый исход Х есть некоторая пара (X1, X2), где X1 и X2 – соответственно исходы первого и второго бросаний (общее число таких пар – X).
Ситуацию с бросанием М раз кости можно рассматривать как некую сложную систему, состоящуюиз независимых друг от друга подсистем – “однократных бросаний кости”. Энтропия такой системы в М раз больше, чем энтропия одной системы (так называемый “принцип аддитивности энтропии”):
f(6M) = M ∙ f(6)
Данную формулу можно распространить и на случай любого N:
F(NM) = M ∙ f(N) (1.4)
Прологарифмируем левую и правую части формулы (1.3): ln X=M ∙ ln N, М =ln X/ 1n M. Подставляем полученное для M значение в формулу (1.4):
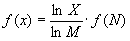
Обозначив через К положительную константу, получим: f(X) =К ∙ lnХ, или, с учетом (1.1), H=K ∙ ln N. Обычно принимают К = 1 / ln 2. Таким образом
H = log2 N. (1.5)
Это – формула Хартли.
Важным при введение какой-либо величины является вопрос о том, что принимать за единицу ее измерения. Очевидно, Н будет равно единице при N=2. Иначе говоря, в качестве единицы принимается количество информации, связанное с проведением опыта, состоящего в получении одного из двух равновероятных исходов (примером такого опыта может служить бросание монеты при котором возможны два исхода: “орел”, “решка”). Такая единица количества информации называется “бит”.
Все N исходов рассмотренного выше опыта являются равновероятными и поэтому можно считать, что на “долю” каждого исхода приходится одна N-я часть общей неопределенности опыта: (log2 N) 1 N. При этом вероятность i -го исхода Рi равняется, очевидно, 1 /N.
Таким образом,
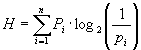 (1.6)
(1.6)
Та же формула (1.6) принимается за меру энтропии в случае, когда вероятности различных исходов опыта неравновероятны (т.е. Рi могут быть различны). Формула (1.6) называется формулой Шеннона.
В качестве примера определим количество информации, связанное с появлением каждого символа в сообщениях, записанных на русском языке. Будем считать, что русский алфавит состоит из 33 букв и знака “пробел” для разделения слов. По формуле (1.5)
Н = log2 34 ≈ 5 бит.
Однако, в словах русского языка (равно как и в словах других языков) различные буквы встречаются неодинаково часто. Ниже приведена табл. 1 вероятностей частоты употребления различных знаков русского алфавита, полученная на основе анализа очень больших по объему текстов.
Таблица 1. Частотность букв русского языка
| i | Символ | Р(i) | i | Символ | P(i) | i | Символ | Р(i) |
| Пробел | 0,175 | 0,028 | Г | 0.012 | ||||
| 0,090 | М | 0,026 | Ч | 0,012 | ||||
| Е | 0,072 | Д | 0,025 | И | 0,010 | |||
| Ё | 0,072 | П | 0,023 | X | 0,009 | |||
| А | 0,062 | У | 0,021 | Ж | 0,007 | |||
| И | 0,062 | Я | 0,018 | Ю | 0,006 | |||
| Т | 0,053 | Ы | 0,016 | Ш | 0.006 | |||
| Н | 0,053 | З | 0.016 | Ц | 0,004 | |||
| С | 0,045 | Ь | 0,014 | Щ | 0,003 | |||
| Р | 0,040 | Ъ | 0,014 | Э | 0,003 | |||
| В | 0,038 | Б | 0,014 | Ф | 0,002 | |||
| Л | 0,035 |
Воспользуемся для подсчета Н формулой (1.6) и получим, что Н ≈ 4,72 бит. Полученное значение Н, как и можно было предположить, меньше вычисленного ранее. Величина Н, вычисляемая по формуле (1.5), является максимальным количеством информации, которое могло бы приходиться на один знак.
Аналогичные подсчеты Н можно провести и для других языков, например, использующих латинский алфавит – английского, немецкого, французского и др. (26 различных букв и “пробел”). По формуле (1.5) получим
H = log2 27 ≈ 4,76 бит.
Как и в случае русского языка, частота появления тех или иных знаков не одинакова.
Если расположить все буквы данных языков в порядке убывания вероятностей, то получим следующие последовательности:
АНГЛИЙСКИЙ ЯЗЫК: “пробел”, E, T, A, O, N, R, …
НЕМЕЦКИЙ ЯЗЫК: “пробел”, Е, N, I, S, Т, R, …
ФРАНЦУЗСКИЙ ЯЗЫК: “пробел”, Е, S, А, N, I, Т, …
Рассмотрим алфавит, состоящий из двух знаков 0 и 1. Если считать, что со знаками 0 и 1 в двоичном алфавите связаны одинаковые вероятности их появления (Р(0)=Р(1)= 0,5), то количество информации на один знак при двоичном кодировании будет равно
H = 1оg2 2 = 1 бит.
Таким образом, количество информации (в битах), заключенное в двоичном слове, равно числу двоичных знаков в нем.
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 567; Нарушение авторских прав?; Мы поможем в написании вашей работы!