КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Выполнение операций сложения и вычитания с плавающей точкой над векторами
|
|
|
|
Этап.
Этап.
Этап.
Этап.
Этап.
Определили знак результата. Знаковые разряды операндов складываются по модулю 2, и результат заносится в знаковый разряд. Знаковые разряды после этого обнуляются.
В счётчик цикла заносится число (n-1) – число значащих разрядов, а n – длина разрядной сетки.
На втором этапе происходит обработка (n-1) циклов.
На каждом цикле анализируется очередной младший разряд множителя (регистр Р2). Если младший разряд равен 1, то переписываем на РА содержимое регистра Р1 (это переход на микропрограммный уровень); а если младший разряд равен 0, то обнуляем РА. После этого в сумматоре складывается содержимое РА и РВ (РВ предварительно обнулили), и на выходе сумматора СМ образуется сумма частичных произведений до сдвига. На РС заносится сумма частичных произведений после сдвига, которая потом переписывается на РВ. Младший разряд сумматора при сдвиге будет заноситься в старший разряд Р21, и он будет (освобождающийся) представлять собой младший разряд произведения. В этом же цикле множитель сдвигается на один разряд вправо путём пересылки с Р2 на Р21, и после записываем на Р2. Счётчик цикла уменьшаем на 1. Если счётчик цикла равен 0, то дальше идёт коррекция результата: старшая часть на РС, младшая на Р21, происходит сдвиг на один разряд. Либо сразу вместо коррекции можно взять n.
Деление чисел с фиксированной точкой.
Деление с восстановлением остатка и без.
x/y=z x- делимое (2n разрядов)
y- делитель (n разрядов)
z- частное (n разрядов)
Надо проверить, вместится ли частное в разрядную сетку:
z < 2n-1
Пример.
n=4
знак
8=23=2n-1→z< 2n-1
x/y< 2n-1
x-2n-1∙y<0
| 20 | ||
| 21 | ||
| 22 | ||
| 23 |
Какова степень, на столько разрядов и сдвигается
Если любое двоичное число умножить на 2m, то это значит, что двоичное число сдвигается на m разрядов влево.
Этапы деления.
Проверка деления. На первом этапе деления проверяется возможность проведения операции деления: из делимого x вычитается делитель y, сдвинутый на (n-1) разряд влево. Если результат вычитания оказывается меньше 0, то деление возможно, т.к. результат z уместится в разрядную сетку n. В противном случае (результат больше 0), z будет требовать больше, чем n разрядов, для своего представления, и, следовательно, деление невозможно.
Определение знака результата. Ниже рассматривается случай деления в прямом коде. Знак результата определяется путём сложения по модулю 2 знаковых разрядов операндов. После этого знаковые разряды операндов обнуляются.
Определение очередной цифры частного. Зависит от метода выполнения деления.
Деление с восстановлением остатка.
Пример.
Число 25 (0.0011001) разделить на 5 (0.101).
n=4
x-2n-1∙y<0

 0.00110 0 1 0. 1 0 1
0.00110 0 1 0. 1 0 1
0101 0. 1 0 1



 рез<0
рез<0
 0011
0011
_0110
 0101
0101
 рез<0 0001
рез<0 0001
рез<0
 0010
0010
_0101
 0000
0000
На очередном этапе частичный остаток сдвигается влево на один разряд. В освободившийся разряд заносим очередную цифру делимого. Из сдвинутого частичного остатка вычитаем делитель (в ЭВМ производится сложение с дополнительным или обратным кодом). Получаем новый частичный остаток. Если результат получился отрицательный, то в очередную цифру частного заносим 0 и восстанавливаем частичный остаток. В противном случае (если результат положительный, либо равен 0), заносим 1.
Деление без восстановления остатка.
Если на очередном шаге частичный остаток оказался положительным, то в частное заносится 1, но на следующем шаге, после сдвига частичного остатка и занесения очередной цифры делимого, производится вычитание делителя и сдвинутого частичного остатка (сложение с дополнительным или обратным кодом). Если частичный остаток отрицательный, то в очередную цифру частного заносится 0, а к сдвинутому частичному остатку прибавляется делитель.

 0.00110 0 1 0. 1 0 1 +5 0.101
0.00110 0 1 0. 1 0 1 +5 0.101
 1011 0. 1 0 1 -5ок 1.010
1011 0. 1 0 1 -5ок 1.010


 рез<0 1110 -5дк 1.011
рез<0 1110 -5дк 1.011
+1100
0101
рез<0 0001 пробное вычитание
рез<0
 1101
1101
+1011
0000
Структурная схема АЛУ.
(Для 2-ого случая).


 Швх
Швх


|
 | |||
 | |||


 Р1
Р1
Р21
 | |||||
 | |||||
 | |||||
РА РВ
 |  |

|
*



Тр СМ
 |
РСМ
 |  | ||

 Швых
Швых
 | |||
 |
Р1 – регистр делителя.
Делимое: старшая часть заносится на РВ, младшая часть на Р2.
Частичный остаток до сдвига получается на выходе сумматора СМ, а частичный остаток после сдвига – на РСМ.
На РСМ с Р2 заносится по линии * очередной разряд делимого. А потом сдвинутый частичный остаток на Р2.
Очередная цифра частного будет записываться в младший разряд регистра Р21.
Р21 предназначен для сдвига младшей части делимого.
Частное формируется на Р21 и переносится на Швых.
Особенности выполнения операций над числами с плавающей точкой.
 |
 - нормализованная правильная дробь
- нормализованная правильная дробь
Знак числа
25.31 + 3.2→0.2531×102 + 0.32×101 = число ×102
1. Порядок результата принимается равным большему из двух порядков.
2. Производится коррекция мантиссы с меньшим порядком: сдвигается вправо на число порядков, равное разности порядков.
3. Этап сложения мантисс: производится сложение мантисс как чисел с фиксированной точкой.
4. Нормализация результата: если результат не нормализован, то нормализуем результат – сдвигаем мантиссу влево на количество разрядов, равное числу нулей до первой значащей цифры; порядок мантиссы при этом уменьшается на это же число.
При сложении мантисс возникает «переполнение». Тогда сдвигаем мантиссу вправо, а порядок увеличивается.
При коррекции порядка может возникнуть переполнение разрядной сетки. Тогда будет прерывание.
Умножение чисел с плавающей точкой.
0.5×103 + 0.26×102
 |  |
РА×2 РВ×2L
При умножении мантиссы перемножаем, порядки складываем.
Деление чисел с плавающей точкой.
Порядки вычитаем, мантиссы делятся.
Л17
ОРГАНИЗАЦИЯ СИСТЕМЫ ПРЕРЫВАНИЯ
В ЭВМ существуют различные ситуации (например, переполнение разрядной сетки, необходимость в/в), когда пользовательская программа должна быть снята с обработки и в ЦП должна начаться программа обработки прерывания.
По окончании выполнения программы обработки прерывания происходит возврат к прерванной программе. Сответствующий механизм, поддерживающий указанные действия, называется системой прерывания. Существует большое многообразие причин прерывания, которые вызывают прерывание обработки программы.
Все возможные прерывания делятся на классы, которым присваивается свой уровень приоритета. Если запрос на прерывание имеет более высокий приоритет, чем обрабатываемая программа в ЦП, то прерывание воспринимается.
Существует специальная маска, которая позволяет замаскировать отдельные запросы на прерывание.
Если код маски установлен в ноль для некоторых причин, то соответствующие запросы не обрабатываются.
Общие правила организации прерывания.
Выполнение программы:


 I (сохранение основных параметров)
I (сохранение основных параметров)

 запрет на прерывание II
запрет на прерывание II








 процесс обработки прерывания
процесс обработки прерывания
 III
III
Основные параметры, подлежащие хранению:
Счеткик команд (CrK)
Признаковые триггера в АЛУ
Маска
Дополнительные параметры:
РОНы
ССП – слово состояния программы (хранит основные параметры)
Запросы на прерывание, как правило, обрабатываются по окончанию выполнения очередной машинной команды.
1 этап: выбор машинной команды из памяти;
2 этап: дешефрация;
3 этап: формирование исполнительного адреса и выбор операндов;
4 этап: выполнение операции в АЛУ;
5 этап: запись результата.
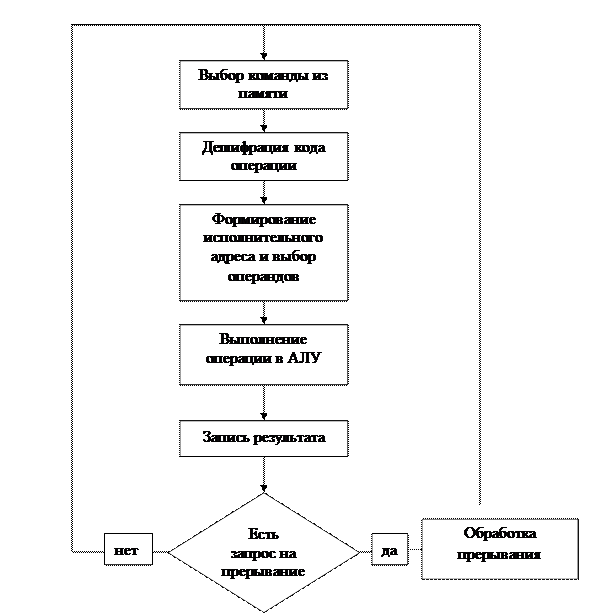
Для систем реального времени, где требуется быстрая реакция на запрос, возможно прерывание в процессе выполнения команды.
При возникновении запроса на прерывание по окончанию выполнения текущей команды происходят следующие действия:
I. Необходимо сохранить основные параметры в памяти (счетчик команд, признаки, маска).
II. Чтобы выполнить программу обработки прерывания в ЦП на счетчик команд из некоторой фиксированной ячейки памяти подается адрес 1-й команды программы обработки прерывания. Процесс выполнения программы обработки прерываний условно включает в себя 3 этапа:
1. Сохранение в памяти дополнительных параметров – содержимого РОНов для прерванной программы.
2. Этап непосредственного выполнения программы обработки прерывания.
3. Восстановление из памяти содержимого РОНов для прерванной программы.
III. Чтобы продолжить выполнение прерванной программы, необходимо восстановить в ЦП содержание регистров ССП, т.е. основных параметров.
Механизм реализации прерываний с помощью «старых» и «новых» ячеек
Все запросы на прерывание делятся на 5 классов:
обработка программ обработка запросов на прерывание
прерывания
max приоритет min приоритет
· 

 Аппаратное прерывание.
Аппаратное прерывание.
· В/в
· Внешние прерывания.
· Супервизор.
· Программное прерывания.
min приоритет max приоритет
Обработка одного запроса на прерывание.
В оперативной памяти выделяются «старые» и «новые» ячейки, их количество соответствует числу классов прерывания (по 5 шт.)
- Код причины прерывания заносится на регистр ССП.
- Содержимое регистра ССП будет записано в «старую» ячейку для этого класса прерывания. (I)
- Содержимое «новой» ячейки для данного класса заносится на регистр ССП (II). В «новой» ячейке содержится адрес первой команды обработки прерывания и маски для обработки прерывания.
4. Выполнение программы обработки прерывания:
а. сохранение РОНов
б. непосредственное выполнение програмы обработки прерывания (анализируется код причины прерывания и в соответствии с кодом выполняется нужная подпрограмма)
в. восстановление РОНов
5. Содержимое «старой» ячейки помещается на ССП (восстановление основных параметров) (III)
При выполнении одной команды приходят одновременно 2 запроса на прерывание от различных классов.
Пример: в/в и внешнее прерываие
- На регистр ССП поступает запрос внешних прерываний.
- В старую ячейку внешних прерываний записывается содержимое регистра ССП.
- Содержимое «новой» ячейки внешних прерываний заносится на регистр ССП. Регистр ССП содержит адрес первой команды программ обработки прерывания для внешних прерываний.
- Запрос по в/в заносится на регистр ССП. Содержимое регистра ССП заносится в «старую» ячейку по в/в. В старой ячейки по в/в будет занесен адрес первой команды внешних прерываний.
- Содержимое из «новой» ячейки по в/в записывается на регистр ССП (адрес первой команды программы обработки прерывания по в/в).
- Выполнение программы обработки прерывания по в/в.
- Содержимое «старой» ячейки по в/в заносится на регистр ССП (На регистре ССП будет содержаться адрес первой команды программы обработки внешних прерываний).
- Выполнение программы обработки внешних прерываний.
- Содержимое «старой» ячейки внешних прерываний записывается на регистр ССП (содержит адрес следующей команды прерванной программы).
Если программа обработки прерывания по в/в уже начала обрабатыватся, и приходит запрос от внешних прерываний, то эта система приоритетов не действует, а возможность прерывания определяется маской: если внешнее прерывание не замаскировано, то запрос от внешних прерываний будет обрабатываться
Стековый механизм организации
Различают понятия: вектор состояния и вектор прерывания, хотя они имеют одинаковую структуру.
 СЧК вектор состояния
СЧК вектор состояния
ССР вектор прерывания
При обработке программы в ЦП изменяется вектор состояния.
При возникновении запроса на прерывание анализируется приоритет обрабатываемой программы в ЦП (порог прерывания) и приоритет запроса на прерывание.
Если запрос на прерывание имеет более высокий приоритет, то инициируется процесс обработки прерывания.
I - Вектор состояния будет для прерванной программы запомнен в стеке.
II - Из некоторой ячейки выбирается вектор прерывания и помещается на регистры ЦП, который содержит адрес 1-й команды программы обработки прерывания. Далее выполняется программа обработки прерывания (3 этапа):
- Сохранение РОНов для прерванной программы.
- Непосредственное выполнение программы обработки прерываний.
- Восстановление сохраненных ронов для прерванной программы.
III - Из верхушки стека выбирается вектор состояния для прерванной программы и помещается на регистры ЦП.
Различаются внутренние и внешние прерывания. Вектор прерывания находится в ячейках с фиксированным адресом (для внутренних причин).
Внешние прерывания
|



 ЗП1
ЗП1
РПn

 РП1
РП1
 |
Существуют i линий запросов на прерывание, к каждой линии может быть подключено несколько внешних устройств (n). Все внешние устройства, подключенные к одной линии, имеют одинаковый приоритет, соответствующий данной линии запроса на прерывание.
Если внешнее устройство выставило запрос на прерываине, то в ЦП сравнивается приоритет запроса на прерывание и приоритет обрабатываемой программы.
Если приоритет запроса на прерывание выше, то происходит прерывание выполняемой программы в ЦП. При этом по соответствующей линии разрешение прерывания подается сигнал разрешения прерывания. (Внешние устройства подключаются к линии запроса на прерывание и к линии разрешения с одинаковыми номерами).
Все устройства, подключенные к данной линии разрешения прерывания, сканируют сигнал разрешения прерывания, и то устройство, которое выставило запрос при обнаружении сигнала разрешения прерывания, передает в ЦП адрес вектора прерывания. В ЦП вектор состояния упаковывается в стек, а на основании полученного адреса вектора прерывание начинает выполняться программа обработки прерывания.
Классификация систем прерывания
Различаются одноуровневые и многоуровневые системы прерываний.
В одноуровневых системах прерывания существует одна линия запроса и одна линия разрешения прерывания.
В многоуровневых системах существуют несколько линий запросов и разрешений прерывания.
Если к одной линии разрешения прерывания подключено несколько устройств, то системы можно классифицировать по следующему признаку:
Системы с фиксированным, либо плавающим приоритетом.
Системы с фиксированным приоритетом часто назначаются по следующему правилу: то устройство, которое физически ближе подключено к ЦП, имеет более высокий приоритет. В системах с плавающим приоритетом опрос устройств ведется в соответствии с приоритетом, который назначается программой.
Организация в/в
Существуют 3 основных подхода к организации в/в:
- Канальный в/в.
- Магистральный в/в.
- Радиальный в/в.
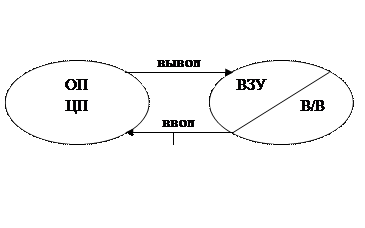
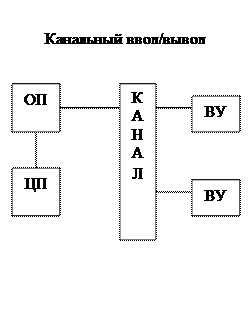 Каналы представляют собой специализированные процессоры, предназначенные специально для организации в/в, которые выполняют канальную программу.
Каналы представляют собой специализированные процессоры, предназначенные специально для организации в/в, которые выполняют канальную программу.
ЦП инициирует в/в, а далее продолжает выполнять программу ЦП. Канал, восприняв запрос по в/в, функционирует параллельно с ЦП и занимается в/в информации. Таким образом, для этого класса систем обработка программ ЦП и организация в/в ведется параллельно.
Канальная команда
Поскольку канал предназначен для организации в/в, а не для обработки данных, то формат канальной команды в корне отличается от формата команды ЦП. Канальная команда содержит следующие поля:
- КОП (код операции: чтение, запись).
- Адрес начала массива, считываемого или записываемого в ОП.
- Длина массива.
- Специальные признаки.
 |
УС(управляющее слово)
Признаки:
1-й признак - цепочка команд.
Когда ЦП инициирует в/в, то он передает номер канала и номер внешнего устройства, с которым необходимо произвести обмен.
Далее канал по отношению к этому внешнему устройству будет выполнять одну канальную программу (ряд канальных команд).
Если признак цепочки команд в некотором управляющем слове установлен в значение 1, то это будет означать, что следующее управляющее слово принадлежит данной канальной программе. Если признак цепочки команд = 0, то данная канальная команда является последней, следовательно, операция в/в завершена и канал посылает сигнал прерывания в ЦП, сигнализирующий завершение операции в/в.
2-й признак - цепочка данных. Используется в том случае, если одна и та же операция (например, чтение или записи) выполняется над разными фрагментами массива. Тогда в одну канальную команду объединяются несколько управляющих слов, которые будут иметь один и тот же КОП, но для каждого фрагмента будет свой адрес начала размещения данного фрагмента в ОП и длина фрагмента.
Для того, чтобы показать, что следующее управляющее слово принадлежит данной канальной команде, устанавливается признач цепочки данных=1
Выделяются 2 типа каналов:
Один тип каналов предназначен для работы с высокоскоростными устройствами и работает в многоканальном режиме (селекторный).
Второй канал предначен для работы с медленно действующими устройствами. Работает в режиме разделения времени. Называется мультиплексный канал.
При обслуживании высокоскоростных устройств канальная программа выполняется с начала до конца для одного вычислительного устройства
В мультиплексном канале параллельно обслуживается несколько внешних устройств, каждое по своей канальной программе. При этом выделяется для каждого внешнего устройства сеанс связи, в течении которого с данным внешним устройством канал обменивается порцией информации. Таким образом, сеансы связи для разных внешних устройств чередуются во времени.
Функционирование селекторного канала
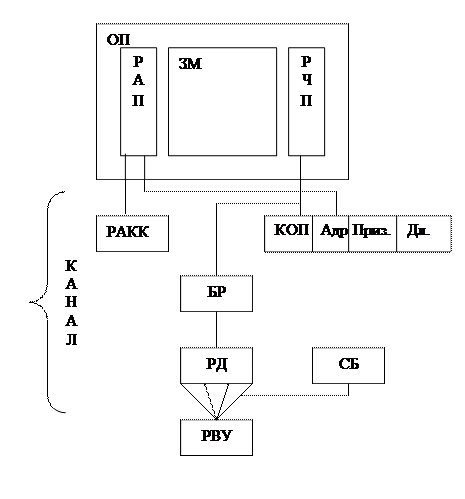
РКК
РАРК – регистр адреса канальной команды
РКК – регистр канальной команды
БР – буферный регистр
РДК – регистр данных канала
СБ – счетчик байт
РВУ – регистр внешнего устройства
РАРК хранит адрес следующего выполняемого управляющего слова.
РКК хранит текущее управляющее слово.
БР предназначен для повышения скорости работы селекторного канала.
РДК - его длина равна ширине выборки из оперативной памяти, т. е. числу байт, которое одновременно можно считать или записать в ОП.
СБ определяет номер байта на РДК, с которым производится обмен с РВУ. Имеет кольцевую структуру и после того, как РДК полностью заполнен, либо полностью разгружен сбрасывается в ноль. Для определенности положим, что ширина выборки из ОП равна 4 байтам.
Ширина информационного тракта – это число байт одновременно передаваемых между РДК и РВУ. Для определенности положим, что ширина информационного тракта равна 1 байту.
Два младших разряда адреса данных в ОП определяют номер байта внутри ширины выборки. Старшие разряды определяют адрес ячейки памяти, где хранятся данные, объем которых равнен ширине выборки.
1010…0|00
1010…0|01
1010…0|10
1010…0|11
1010…1|00
Первый этап: выбор управляющего слова из памяти. УС имеет размер 8 байт, поэтому по адресу, который хранится на РАРК за два обращения к ОП выбирается УС и помещается на РКК. Далее анализируется КОП.
Выполнение операции «запись»
Старшая часть адреса поступает в ОП. В СБ заносятся младшие разряды исполнительного адреса, которые определяют номер байта, считываемого в РДК.
СБ управляет коммутационной схемой, которая коммутирует нужный номер, хранящегося на РДК, байта с РВУ. По СБ 1 байт переписывается с РДК на РВУ и корректируются параметры канала в соответствии с формулой (1):
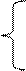
Дл = Дл – 1;
Адр = Адр + 1; (1)
СБ = СБ + 1.
Если СБ и Дл массива не равны нулю, то с РДК на РВУ считывается следующий байт информации.
Если Дл массива не равна нулю, а СБ = 0, то РДК разгружен полностью. И если массив полностью не переписан, по адресу, хранящемуся на РКК, нужно считать следующие 4 байта из памяти и поместить их на РДК.
Если Дл массива стала равна нулю, нужно проверить поле признака. Если признак цепочки команд равен 1, то выбирается следующее управляющее слово из памяти. Если признак равен 0, то формируется сигнал прерывания в ЦП.
Выполнение операции «чтение»
По СБ с РВУ на РДК заносится очередной байт информации и по формуле (1) корректируются параметры канала.
Если СБ и Дл массива не равны нулю, то с РВУ на РДК заносится следующий байт информации.
Если СБ = 0, то РДК заполнен полностью и данные с РДК надо записать в память по старшим разрядам адреса, хранящимся на РКК. Если Дл массива = 0, то проверяется поле признака (см. выполнение операции «запись»). Предварительно содержимое РДК заносится в ОП.
При выполнении операции «запись» в ОП сначала данные считываются на РЧП, а потом по СБ с РДК нужное количество байт изменяется на РЧП.
БР позволяет организовать параллельную работу по разгрузке и заполнению РДК и по обмену между БР и ОП. БР позволяет увеличить скорость работы селекторного канала. При выполнении операции «запись», пока данные с РДК переписываются на РВУ, из памяти выбираются следующие 4 байта массива на БР. При выполнении операции «чтение» предшествующие 4 байта с БР записываются в ОП, а в это время с РВУ заполняется следующими байтами РДК.
Организация мультиплексного канала
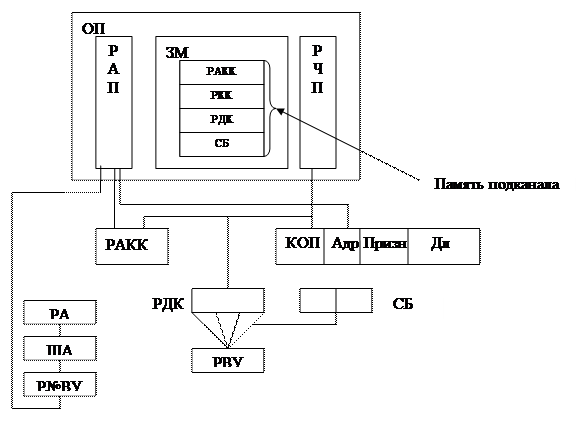
ША – шифратор адреса
РА – регистр адреса
Р№ВУ - регистр номера внешнего устройства
Мультиплексный канал предназначен для параллельной обработки одновременно работающих ВУ во времени.
Структура мультиплексного канала включает в себя 2 части:
1. Одна часть предназначена для хранения параметров канальной программы относительно отдельных ВУ (относятся к отдельному внешнему устройству и представляют собой память подканалов).
2. Вторая часть является общей для всех ВУ и представляет собой регистры канала.
При работе мультиплексного канала выделяют 2 типа сеансов связи:
1. Сеанс начальной выборки
2. Сеанс по запросу внешнего устройства
Сеанс начальной выборки
Предназначен для создания нового подканала. ЦП выдает в канал и номер устройства и номер канала, с которым необходимо произвести операцию. Далее происходит тестирование ВУ, и если оно свободно и готово к выполнению операции, то далее на РАКК из специальной ячейки помещается адрес первой канальной команды, на РКК выбирается первое управляющее слово, в СБ заносятся младшие разряды адреса. Если КОП – запись, то на РДК из памяти считываются первые 4 байта массива. Далее по номеру ВУ определяется адрес подканала и в этот подканал заносится содержимое РАКК, РКК, СБ. После того как ВУ будет готово к приему или выдаче информации, оно передает свой номер в мультиплексный канал. И далее будет иметь место второй тип сеанса связи по обслуживанию ВУ.
Т. к. мультиплексный канал предназначен для обслуживания медленных ВУ, то каждому из них выделяют отдельный сеанс связи, в течение которого ВУ обменивается с каналом одним байтом информации. Сеансы связи по обслуживанию различных ВУ чередуются между собой во времени.
Сеанс связи по запросу ВУ
Рассмотрение этого сеанса включает 3 этапа:
1. По адресу, полученному на регистре РА (адрес памяти подканала) выбирается содержимое памяти подканала и подается на регистры канала.
2. Основной этап начинается с анализа кода операции на регистре РКК (канальная команда, находящаяся на РКК. Ее выбирать не надо)и пересылки 1 байта информации между РДК и РВУ.
3. Третий этап заключается в том, что содержимое регистров канала переписывается в подканал, адрес которого содержится на регистре РА.
ВУ на регистр номера ВУ выставляет свой номер (когда данное ВУ готово к работе, к обмену одним байтом РДК с РВУ).
Шифратор адреса по номеру ВУ определяет адрес ячейки ОП, начиная с которой хранится содержимое памяти подканала (содержимое РАКК, РКК, СБ и РДК). Далее содержимое памяти подканала заносится на регистры канала.
Выполнение операции «запись»
По СБ 1 байт переписывается с РДК на РВУ и по формуле (1) корректируются параметры канала. Если СБ и Дл массива не равны нулю, то переходим к этапу 3.
На втором этапе, после того как очередной байт переписался на РВУ, СБ может оказаться равным нулю, а Дл массива не равной нулю. Тогда на этом же этапе по адресу, содержащемуся в РКК, выбирается очередной фрагмент массива и передается на РДК. Далее 3 этап.
На втором этапе после передачи очередного байта, Дл массива может оказаться равной нулю. Тогда анализируем поле признаков. Если признак цепочки команд равен нулю, то формируется сигнал прерывания, канальная программа завершена. В противном случае из ОП выбирается следующее управляющее слово по адресу, который содержится на РАКК. Это управляющее слово записывается на РКК за два обращения к ОП.
После выбора очередного управляющего слова на РКК в этом же сеансе связи проверяется КОП. Если происходит операция записи, то на РДК считывается фрагмент массива по адресу, хранящемуся на РКК. Далее третий этап.
Выполнение операции «чтение»
По СБ с РВУ на РДК считывается очередной байт информации. По формуле (1) корректируются параметры канала.
Если СБ и Дл массива не равны нулю, то переходим к третьему этапу.
Если СБ = 0, а Дл массива ≠ 0, то это означает, что СБ заполнен полностью и по адресу с РКК производиться запись в память с РДК. Далее третий этап.
Если Дл массива =0, то РДК записывается в память и анализируется поле признаков (см. выполнение операции «запись»).
В мультиплексном канале существует 3 различных регистра для хранения адреса.
1. РА – хранит адрес памяти подканала.
2. РАКК – хранит адрес следующего управляющего слова.
3. Адр в РКК – хранит адрес массива, который считывается или записывается в ОП.
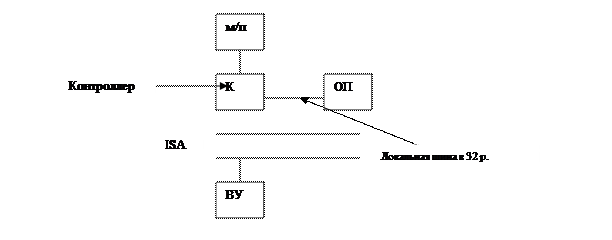
Магистральный ввод/вывод

Через общую шину могут обслуживаться одновременно только 2 устройства. Поэтому, в отличие от предыдущего случая, параллельное совмещение по времени выполнения программы в ЦП и ввод/вывод невозможно.
В каждый момент времени одно устройство является ведущим, а остальные являются ведомыми, за исключением ОП, которая всегда ведомая.
В общей шине выделяют 4 группы шин:
1. Шины данных
2. Шины управления
3. Адресные шины
4. Шины арбитража
Шины данных:
По шинам данных в параллельном коде данные пересылаются между ведущим и ведомым устройствами.
Шины управления предназначены для передачи управляющих сигналов.
Адресные шины:
При данном способе ввода/вывода существует единое адресное пространство для всех устройств. Следовательно, здесь не нужны специальные команды в/в, а достаточно команды move (команда пересылки), а адреса определяют между какими устройствами осуществляется передача. В этом заключается отличие от радиального в/в.
Шины арбитража(шина запроса на прерывание):
См. стековый механизм прерывания.
ВУ, готовое к приему или передаче 1-2 байт информации, выставляет сигнал прерывания на шину запроса. Запрос обрабатывается и в качестве программы обработки прерывания будет выступать программа в/в, под управлением которой 1-2 байта информации будут передаваться между двумя устройствами. Такой программно управляемый в/в характерен для медленных устройств. Для быстродействующих систем используют прямой доступ к памяти. Быстродействующие устройства подключаются к специальной шине запроса на прерывание, которая имеет наивысший приоритет. При поступлении запроса на шину прямого доступа к памяти общая шина освобождается для в/в. Однако программа, обрабатываемая в ЦП, с обработки не снимается, т.е. стековый механизм реализации прерывания в этом случае не работает.
Программно-управляемый ввод/вывод(для медленных ВУ)


|

 : ЗП1
: ЗП1
:

 РПn
РПn
|
|

 РП1
РП1
ВУ как только готово принять или передать байт информации на шину запроса на прерывание, выставляет запрос на прерывание.
В стэк записываются основные параметры прерванной программы(вектор состояния). По адресу вектора прерывания, который выдаёт ВУ, выбираются основные параметры прерывания во вводу/выводу(адрес 1-ой выполняемой команды, порог прерывания) и помещаются на регистры ЦП. В ЦП начинает выполняться программа прерывания по вводу/выводу. Под управлением этой программы происходит ввод/вывод 1-2 байта информации (обмен между ВУ и ОП или ЦП). После этого программа обработки прерываний завершает свою работу. Из стэка восстанавливаются основные параметры прерванной программы(вектор состояний), и она продолжает выполняться далее. Когда ВУ вновь будет готово принять или передать 1-2 байта информации, то оно вновь выставляет запрос на прерывание и т.д.
Параллельно ввод/вывод и обработка программы в ЦП выполняться не могут.
Прямой доступ к памяти(для быстродействующих ВУ)
Программа в ЦП не прерывается(стэковый механизм прерывания не задействуется). Непосредственно ввод/вывод осуществляется под управлением контроллера по вводу/выводу. При этом ВУ подаёт запрос на специальную шину: запрос прямого доступа к памяти. Эта линия всегда имеет самый высокий приоритет. В контроллере есть регистр адреса начала массива, регистр длины массива. Как только длина массива = 0 передача заканчивается.
Радиальный ввод/вывод
В отличие от магистрального ввода/вывода имеется отдельное адресное пространство. Это значит ВУ может иметь один и тот же адрес, что и ячейка памяти, использующая команды в/в.
Микропроцессоры.
Выделяют два основных направления:
- однокристальные
- секционированные
Секционированные микропроцессоры:
на одном кристалле выполнен полностью микропроцессор (мп) на ограниченное кол-во разрядов (например 4) Секции соединяются между собой, следовательно происходит наращивание разрядности мп до требуемого числа разрядов. Программирование ведется на микропрограммном уровне.
Однокристальные микропроцессоры:
весь процессор выполнен на одном кристалле. Программирование ведется на уровне машинных команд. На 1-ой ступени развития целиком мп не удавалось выполнить на одном кристалле, тогда мп был разделен «горизонтальными плоскостями» на несколько кристаллов.
Микропроцессоры серии INTEL.
| м/п | Год выпуска | Частота МГц | Кол-во транзисторов тыс.шт | Разряд шины | Размер адресного пространства | Примечания |
| Intel 8086 | 5-10 | Внутр внешн 16/16 | 1Мбайт | 20 разрядов адресная шина | ||
| Intel 8088 | 5-8 | 16/8 | 1Мбайт | Используем в PC-XT | ||
| 10-16 | 16/16 | 16Мбайт | Шина адреса 24 разряда, исп в PC-AT | |||
| 80386DX | 20-33 | 32/32 | 4Гбайт | Шина адреса 32 разряда | ||
| 80386SX | 20-30 | 32/16 | 4Гбайт | |||
| 80486DX | 25-50 | 32/32 | 4Гбайт | |||
| 80486DX2 DX4 | До 133 | |||||
| 80486SX | До 33 | 32/32 | 4Гбайт | |||
| Pentium | 150-200 | 3.1 млн | 4Гбайт | |||
| Pentium Pro | 150-200 | 5.5 млн +15.5млн или 31млн | 64Гбайт | 5.5 млн на осн кристалле 15.5млн(КЭШ 256Кб) 31млн(КЭШ 500Кб) | ||
| Pentium MMX | 166-266 | 4.5 млн. | 64 Гбайт | |||
| Pentium 2 | 233-466 | 7 млн. | 64 Гбайт | |||
| Celeron | 266-300 | |||||
| Pentium III | 500-1000 | 8.2 млн | ----//---- | ----//---- | ||
| Pentium IV Prescott | 2-3 ГГц от 3 ГГц | 55 млн 100 млн | ||||
| Pentium M | 1-2 ГГц | 77-144 млн | ||||
| Core Yonah | 1-2 ГГц | 155 млн | ||||
| Core 2 Solo | 1,6-3 ГГц |
INTEL 8086,8088
Впервые идет совмещение обработки команд во времени.
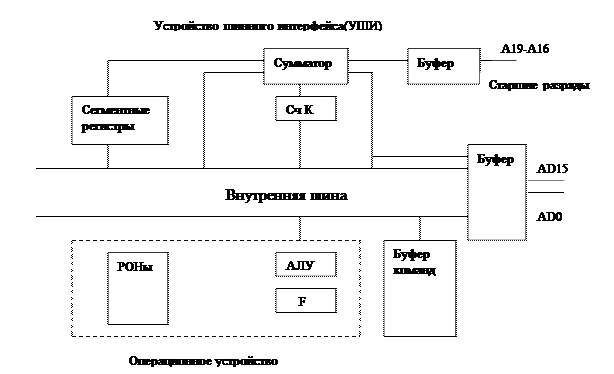
Выделяются 2 устройства: операционное устройство (ОУ) и устройство шинного интерфейса (УШИ). УШИ предназначено для вычисления адресов и формирования запросов к памяти (ОП) к ВУ. В УШИ включён буфер команд емкостью 6 байт (очередь команд). Как только в буфере команд освободится 2 байта (внешняя шина данных и ширина выборки ОП 2 байта) УШИ формирует опережающий запрос в память за командами. ОУ выполняет команды, находящиеся в буфере команд. Если требуется обращение к памяти за операндами или по записи результата, то ОУ выставляет запрос к УШИ. Если УШИ свободно, то запрос выполняется сразу же, если УШИ занято выборкой команд, то после получения 2-х очередных байт обрабатывается запрос от ОУ. Т.о. выбор следующей команды начинается не по завершению предыдущей команды, а по наличию 2х свободных байт в буфере команд- принцип опережающей обработки. Снижение производительности происходит из-за появления команд перехода. При появлении команд перехода содержимое буфера обнуляется и буфер команд заполняется с команды, на которую осуществляется переход. Мультиплексированы шины данных и шины адреса.
МИКРОПРОЦЕССОР 8088
Внешняя шина данных 8 разрядов для совместимости с ранее разработанными ВУ. Для реализации плавающей точки в м/п 8086 и в 8088 для повышения производительности на материнской плате мог отдельно устанавливаться мп, аппаратно реализующий операции с плавающей точкой.
| Тип операции | 8087 Мкс | 8086 и 8088 эмуляция мкс |
 + +
| 17-18 | |
| * | ||
| √ | ||
| Exp x |
INTEL 80286
1.В отличие от 8086/8088 шина адреса и шина данных не мультиплексированы во времени (своя ША и ШД)
2. Разработчики предусмотрели реальный и защищенный режим. В защищённом режиме имеется возможность использования мультипрограммирования.
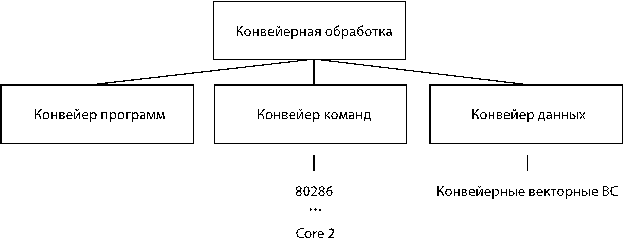
3. Конвейерная обработка команд
 Конвейерная обработка на уровне команд:
Конвейерная обработка на уровне команд:
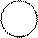 Каждый этап машинной команды обрабатывается на отдельном блоке. На 1-м такте 1-я команда подается на первый блок, то есть реализует 1-й этап(выборка команды из памяти). Во 2-м такте 1-я команда переходит на 2-й этап, а 2-я команда поступает на первый этап. В 3-ем такте, 1-я команда на 3 этапе, 2-я команда на 2-ом этапе, 3-я команда на 1-ом этапе. Т.е. конвейер команд аналогичен технологическому конвейеру. После заполнения конвейера каждый такт на конвейере заканчивает обрабатываться очередная команда. Поэтому говорят, что за первый такт выполняется 1 команда. Потеря производительности происходит в следствие команд перехода, когда содержимое конвейера обнуляется и в следствии информационных конфликтов
Каждый этап машинной команды обрабатывается на отдельном блоке. На 1-м такте 1-я команда подается на первый блок, то есть реализует 1-й этап(выборка команды из памяти). Во 2-м такте 1-я команда переходит на 2-й этап, а 2-я команда поступает на первый этап. В 3-ем такте, 1-я команда на 3 этапе, 2-я команда на 2-ом этапе, 3-я команда на 1-ом этапе. Т.е. конвейер команд аналогичен технологическому конвейеру. После заполнения конвейера каждый такт на конвейере заканчивает обрабатываться очередная команда. Поэтому говорят, что за первый такт выполняется 1 команда. Потеря производительности происходит в следствие команд перехода, когда содержимое конвейера обнуляется и в следствии информационных конфликтов

 R1 + R2 R1
R1 + R2 R1
 |
R3 + R1 R3
До тех пор пока результат для 1-й команды не будет записан в R1 вторая команда не может считывать операнды из R1 т.е. происходит блокирование конвейера. Для м/п INTEL 80286 число ступеней конвейера равно 4.
INTEL 80386 DX
Первый 32-х разрядный м/п. Уже в PC впервые поддерживается Windows. Работает как в реальном, так и в защищенном режиме. Поддерживается виртуальный режим м/п 8086 (если параллельно запущенно несколько задач. то каждая задача обрабат. на м/п 8086
INTEL 80386 SX
Уменьшены внешние шины данных с 32 до 16 разрядов, было вызвано совместимостью с ВУ, которые работали с м/п 80286
INTEL 80486 DX
- Впервые сопроцессор с плавающей точкой был встроен в кристалл м/п. В предыдущих моделях сопроцессор с плавающей точкой реализован на отдельном кристалле. Сопроцессор стал работать на тактовой частоте основного процессора и произошло увеличение производительности в 2 раза.
- Внутрь самого кристалла был встроен КЭШ 1-го уровня, его емкость 8 Кбайт. КЭШ 2-го уровня располагалась отдельно на материнской плате и его объем 256Кбайт и 512Кбайт. Впервые КЭШ на материнской плате стал использоваться совместно с 80386 микропроцессором.
- Был усовершенствован механизм обработки команд, используется 5-ти ступенчатый конвейер, в среднем обеспечивается обработка 1-й команды за 1 такт.
DX2 – удвоение тактовой частоты
DX4 – утроение тактовой частоты
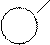
PENTIUM
- Впервые появился отдельно КЭШ команд и КЭШ данных, каждый по 8Кбайт.
- Впервые появляется суперскалярная обработка команд. В структуре имеется 2 АЛУ, которые параллельно обрабатывают независимые команды.
- Впервые аппаратно реализован блок предсказания переходов.
- Операции с плавающей точкой обрабатываются в конвейерном режиме.
PENTIUM PRO
1. В кристалле встроен КЭШ 1-го уровня на 16 Кбайт и КЭШ 2-го уровня либо на 256Кбайт либо на 512Кбайт. КЭШ 2-го уровня работает на тактовой частоте самого м/п, т.к встроена в кристалл.
2. В следующей модели фирма Intel отказалась от встроенного КЭШ 2-го уровня в кристалле, т.к. увеличился процент брака.
3. В Pentium Pro используют 14-ступенчатый конвейер.
4. В Pentium Pro (c него начинается серия Р6) используется конвейер с изменяемой последовательностью команд. Зависимая команда, поступающая на вход конвейера, не сдерживает выполнение следующей за ней независимой команды в окне просмотра. В предыдущих моделях зависимая команда блокировала выполнение всех следующих за ней команд.
PENTIUM MMX
Структура соответствует Pentium, однако увеличен КЭШ 1-го уровня до 32Кбайт (16 КЭШ команд +16 КЭШ данных)
Добавлено 57 новых команд для обработки видео изображения.
PENTIUM 2
Это есть Pentium Pro + Pentium MMX. Однако КЭШ 2-го уровня вынесен из кристалла и помещен на подложку в одном корпусе с основным кристаллом, работал на 0.5 тактовой частоте.
CELERON
Из подложки удален КЭШ 2-го уровня. Резко падает производительность системы. Начиная с модели 300А и выше, встраивается КЭШ внутрь кристалла на 128 Кбайт, который работает на частоте ЦП.
PENTIUM III
Структура Pentium 2, добавлены команды для обработки видео изображения.
PENTIUM 4
В последующих моделях Pentium III КЭШ встраивается в кристалл на 256 Кбайт. Все Pentium 4: КЭШ в кристалле.
- КЭШ 1-го уровня включает в младших моделях 8Кбайт данных, 12 Кбайт КЭШ, которая хранит микрокоманды. КЭШ 2-го уровня встроен в кристалл
- Число ступеней конвейера 20.(гиперконвейерная обработка) В КЭШ 1-го уровня поступают декодированные команды(хранится в КЭШ 1-го уровня микропрограмма), и за 1 такт декодирует одновременно 3 команды. В КЭШ хранится несколько цепочек микрокоманд. Если направление перехода выбрано не верно, происходит обращение в КЭШ 1-го уровня и выбирается другая цепочка микрокоманд.
- Память расширена до 16 Кбайт(в последних моделях)
- Существует 2 параллельно работающих АЛУ. С 2002г. Pentium 4 оснащается специально BIOS, который поддерживает гипертрейдинг: т.к. число блоков конвейера велико, то одновременно часть блоков может простаивать. Потому эти свободные блоки загружаются другой задачей.
PRESCOTT
31 ступень конвейера (гиперконвейрная обработка). КЭШ в кристалле увеличена до 1 Мб. КЭШ 3-го уровня 2Мб помещен на материнскую плату. Появляется новая обработка – гипертрейдинг. Чтобы заполнить 20-30 ступеней в КЭШ 1-го уровня находятся трассы микропрограмм. Гипертрейдинг – это псевдомультипрограммный режим, т.е на свободные блоки конвейера запускают вторую задачу, т.е одновременно обрабатываются 2 задачи.
PENTIUM D
На одной подложке (кристалле) помещены 2 ядра Prescott (каждый со своим КЭШ), отключив гипертрейдинг.
PENTIUM M
КЭШ 1-го уровня увеличена до 64 Кб. (архитектура P6 (продолжение Pentium III) 32Кб команд, 32Кб данных. КЭШ 2-го уровня 1-2Мб встроен в кристалл. Количество обрабатываемых блоков 9 штук)
CORE 2
КЭШ 1-го уровня увеличен до 2-4 Мб. КЭШ команд 32 Мб, КЭШ данных 32 Кб. Добавляется четвертый простой декодер. Число обрабатываемых блоков 11 штук: АЛУ с фиксированной точкой 3 штуки по 64 разряда, 2 шт. АЛУ с плавающей точкой 128р. Команды видеорежима 3 блока 128р. 3 блока обращения к памяти. Intel впервые в Core и Core 2 для двуядерных процессоров использовал общую КЭШ 2-го уровня. В Core 2 имеется связь между отдельными ядрами.
Системные интерфейсы
1. м/п 8086, 80286
тактовая частота 5-10, 10-16МГц
Проблемы которые решаются системным интерфейсами: связь ОП и ЦП, связь ядра с ВУ.

тактовая частота 5-8 Мгц
пропускная способность 5-10 Мбайт/сек
2. м/п 80386, 30 Мбайт/сек
На материнской плате появляются новые архитектурные решения: Появляется КЭШ, чтобы как можно реже обращаться к ОП. Стали использовать несколько структур решений:
1. Использование локальной шины
2 MCA, 16,32p, = 14 Мбайт/сек
использование в системах PS2, прекращ. существование
3 EISA, 32p, 33 Мбайт/сек
- расширенная шина ISA, прекращ. существование
3. м/п 80486
тактовая частота 33 Мгц
пропускная способность 130 Мбайт/сек
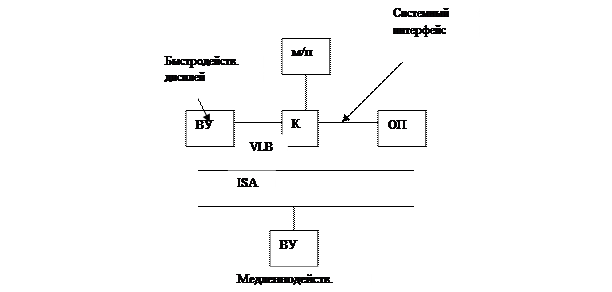
4. Pentium
PCI: 32разряда
133 Мбайт/сек
33 МГц
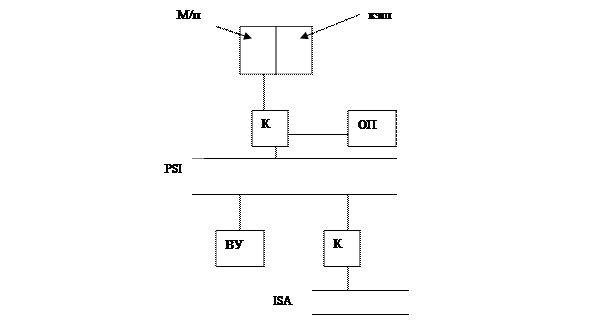
5. Pentium MMX: поддержка 3-х мерной графики
AGP: 133 МГц
633 Мбайт/сек
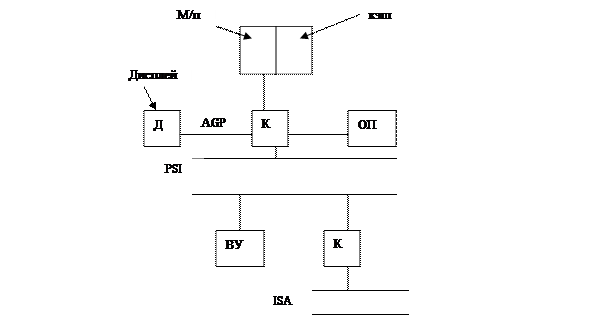
6. Pentium II
Системная шина 528-800 Мбайт/сек, 66-110 МГц, AGP - 500 Мбайт/сек
7. Pentium 4
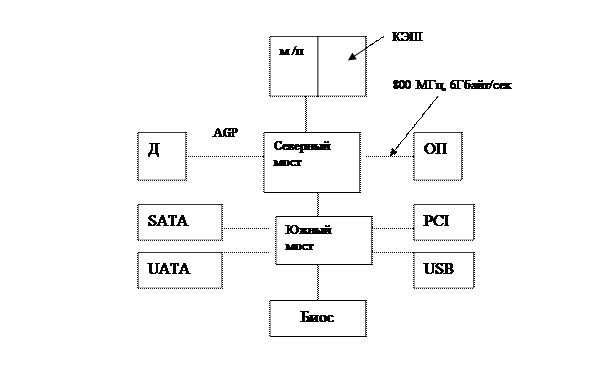
Классификация вычислительных систем.
Выделяют четыре класса вычислительных систем:
1. ОКОД (одиночный поток команд, одиночный поток данных)
2. ОКМД (одиночный поток команд, множественный поток данных)
3. МКОД (множественный поток команд, одиночный поток данных)
4. МКМД (множественный поток команд, множественный поток данных)
Под множественным потоком команд понимается случай, когда в вычислительных системах одновременно на разных ЦП обрабатываются различные команды.
Под множественным потоком данных понимается случай, когда в вычислительных системах одновременно на разных блоках обрабатываются множество потоков данных.
Под потоком команд / данных понимают одновременную обработку нескольких команд или данных в ЦП.
Многообразие вычислительных систем связано с различием в характеристиках обрабатываемых задач.
Классы задач:
1. Слабосвязанные задачи, параллелизм независимых задач.
2. Параллелизм независимых ветвей.
3. Параллелизм независимых объектов.

МКМД
1.Многомашинные комплексы.
Имеется несколько ЭВМ, каждая из которых содержит свой ЦП, ОП и ВУ и соответственно работает под управлением своей ОС. Служат для решения задач первого класса.
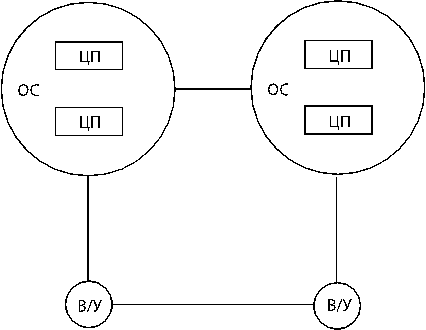
Классификация многомашинных комплексов.
1. Слабосвязные – связь устанавливается на уровне в/у.
2. Сильносвязные – связь на уровне «ядро-ЭВМ».
3. Сателлиты
Слабосвязные ЭВМ. Повышение надежности.
1. Связь по в/у, резервная ЭВМ может находится в выключенном состоянии.
2. Резервная ЭВМ во включенном состоянии в режиме тестировании. Как только основная ЭВМ выходит из рабочего состояния, резервная подключается к выполнении задачи.
3. Троированная система Три системы решают одну задачу. Если 2 системы одинаково решили задачу, значит они исправны, а третья вышла из строя.
Мультипроцессорные вычислительные системы.
Предназначены для повышения производительности задач 2-ого класса.
В то время, как многомашинные комплексы предназначены либо для повышения производительности при обработке задач, обладающих свойством независимости на уровне задач, либо повышения надежности вычислительных систем.
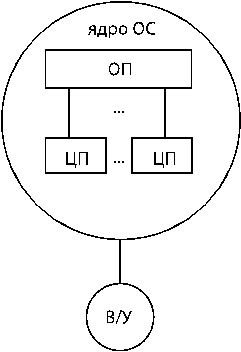
Используются для повышения производительности при решении задач, характеризующихся параллелизмом независимостью ветвей.
Особенности:
1. ЦП работают с общей памятью
2. Для ядра имеется общее ВУ и общая ОС.
Классификация мультипроцессорных ВС:
1. На основе общей шины
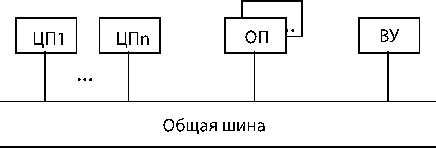
Только два устройства могут общаться между собой, т.е. малая производительность.
Достоинства: простота, система просто наращивается.
Недостатки: низкая надежность, т.к. если общая шина выходит из строя, то вся система тоже выходит из строя. Низкое быстродействие.
2. На основе коммутационной матрицы.
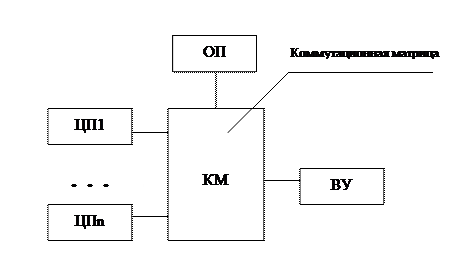
Достоинства: Высокая производительность надежность (выше чем в первом случае).
Недостатки: Малая гибкость, чтобы нарастить систему, надо переделать всю коммутационную матрицу.
3. С многовходовой памятью. (ОП)
ОКМД
В системе существует матрица процессоров, т.о. все процессоры вычислительной системы выполняют одну и ту же команду над своими различными данными, таким образом получается матрица результатов. Т.е. эти системы предназначены для решения задач 3-его класса (задачи с одним алгоритмом, но различными объектами).
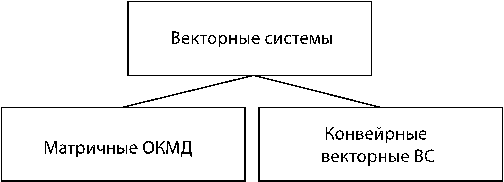
Системы, относящиеся к классу ОКМД – одна из разновидностей векторных вычислительных систем.
Особенности матричных ВС:
1. Общее УУ для всех процессорных модулей.
2. Все процессоры одновременно выполняют одну и туже команду, но над различными данными.
Сложно установить связи между отдельными ЦП, если между ними не предусматривается прямых связей.
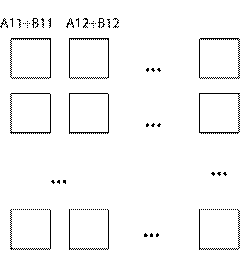
Векторная ВС предназначена для обработки векторов.
В векторных вычислительных системах в формате команд вводится дополнительное поле, указывающее длину вектора.
Векторная команда:

Если задача не векторизируется, то прироста производительности не будет.
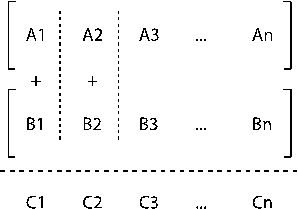
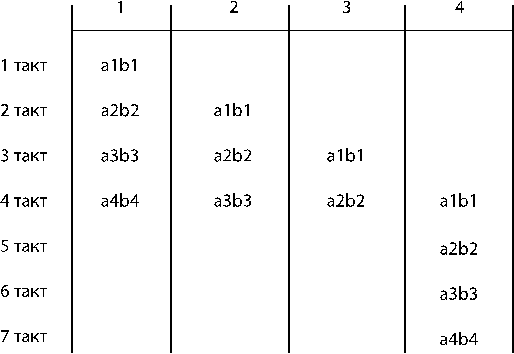
МКОД. Конвейерные векторные ВС.
Конвейер на уровне данных может использоваться только тогда, когда имеются векторные данные (имеются векторные регистры). При конвейерной обработке данных нет информационной зависимости.
Методы повышения производительности:
1. Конвейерная обработка на уровне команд (см. 286-процессор).
2. Конвейерная обработка на уровне данных (характерна для векторных вычислительных систем). Каждый такт выводит результат.
1. Разность порядков.
2. Сдвиг мантисс.
3. Сложение или вычитание мантисс.
4. Нормализация результата.
Особенности конвейерных ВС:
1. Конвейерная обработка на уровне данных.
2. Использование однофункциональных АЛУ
3. Метод зацепления – когда параллельно работают несколько АЛУ, и при этом не дожидаясь завершения предыдущей операции над всеми элементами вектора запускается следующий конвейер с другой операцией.
Видеорежимы.
Отображение образа экрана в памяти системы.
Есть взаимно-однозначное соответствие между информацией в ОП и на экране дисплея (видеопамять).
Существует два режима:
1. Текстовый
2. Графический
Текстовый режим – все поле экрана разбивается на клетки: алфавитно-цифровые. Каждому символу в памяти выделяется 2 байта. Первый байт в коде ASCII, а второй байт предназначен для кодирования цвета символа и кода.
Графический режим – все поле разбивается на светящиеся точки – пиксели (пиксельная графика) Каждой клетке в памяти должен соответствовать хотя бы 1 бит (черно-белое изображение). Если 2 бита – 4 цвета.
Сколько бит – такова цветность.
|
|
|
|
|
Дата добавления: 2014-01-06; Просмотров: 743; Нарушение авторских прав?; Мы поможем в написании вашей работы!